
你在被窝里刷手机岁月静好,一个“神秘引擎”却在远方和时间赛跑
浅友们好~我是史中,我的日常生活是开撩五湖四海的科技大牛,我会尝试各种姿势,把他们的无边脑洞和温情故事讲给你听。如果你想和我做朋友,不妨加微信(shizhongmax)。

于是神舟上天,航母下水,高压线飞架,铁路桥纵横,山河之间,各式机器飞转。我们愣是把自己家干成了世界工厂,从拖鞋袜子造到手机电脑,造不出来算我输。(这不最近造芯片遇到点困难,正在痛定思痛。)





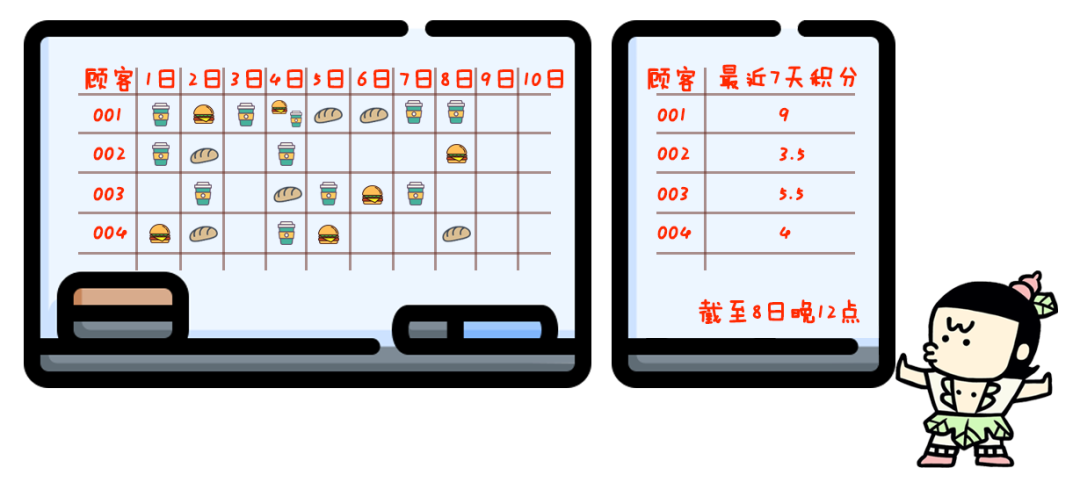
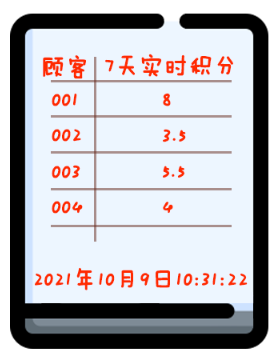
你店里卖的东西种类越来越多:10种咖啡,8种点心,还有6种正餐。
与此同时,你的促销活动也变得更复杂:一份咖啡积1分,一份点心积0.5分,一份正餐积2分。
一周内积够10分才送骑马,七天之前的过期积分就作废。
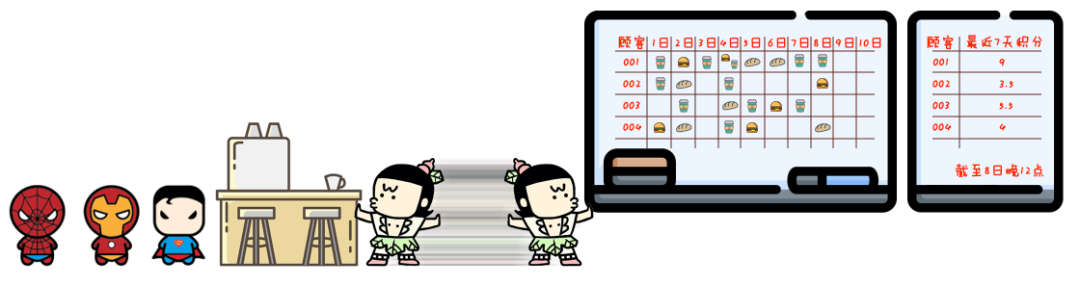


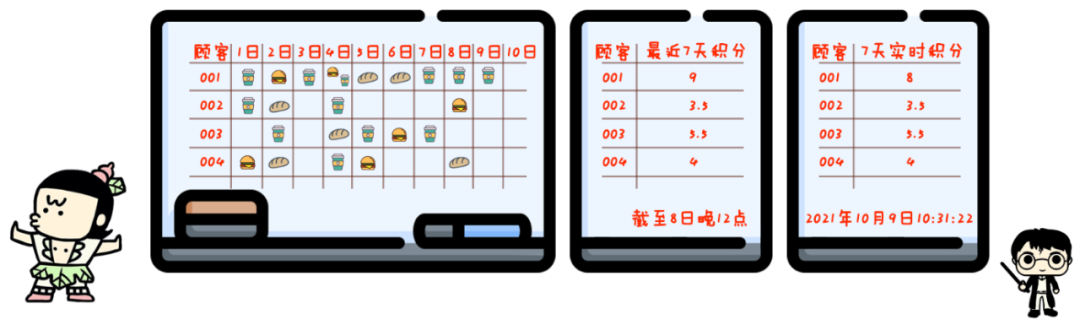

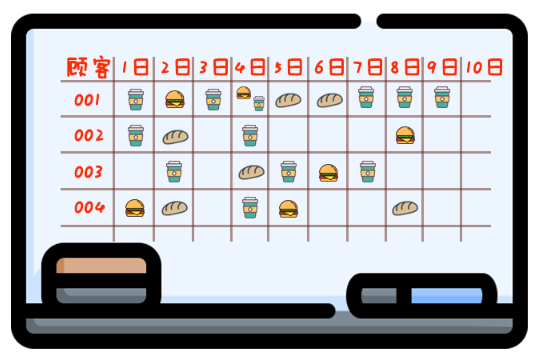
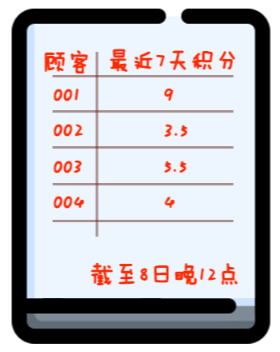

1、“实时计算”的潮流势不可挡,在最近三年,全世界都经历了从头部互联网公司到全体互联网公司的扩散,现在正在经历从互联网行业到传统行业的传递过程。
2、“实时计算引擎”曾经有很多技术路线相互竞争。如今,有一种引擎刚刚锁定胜局,承担了各行各业大多数实时计算的任务,这个引擎叫做 Flink。
3、Flink 的技术纵然非常精密,但它本身不属于任何一家公司,是完全开源的,人人都可以像呼吸空气一样自由使用 Flink。而对这项前沿技术掌握最炉火纯青的,正是我们中国的百万程序员。







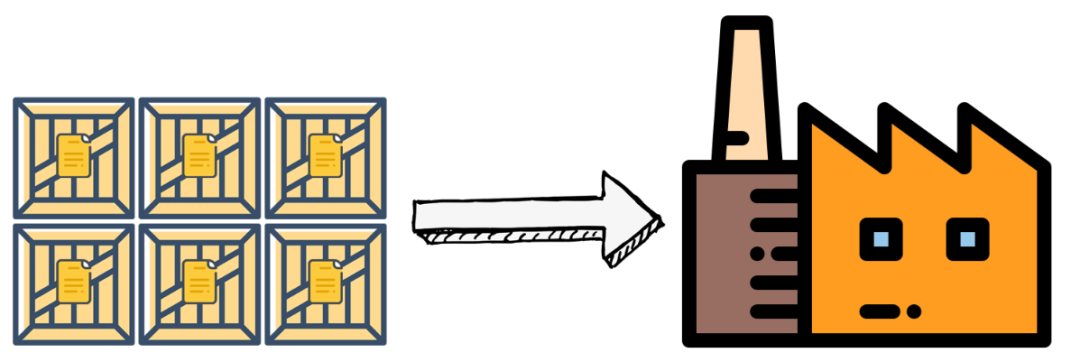
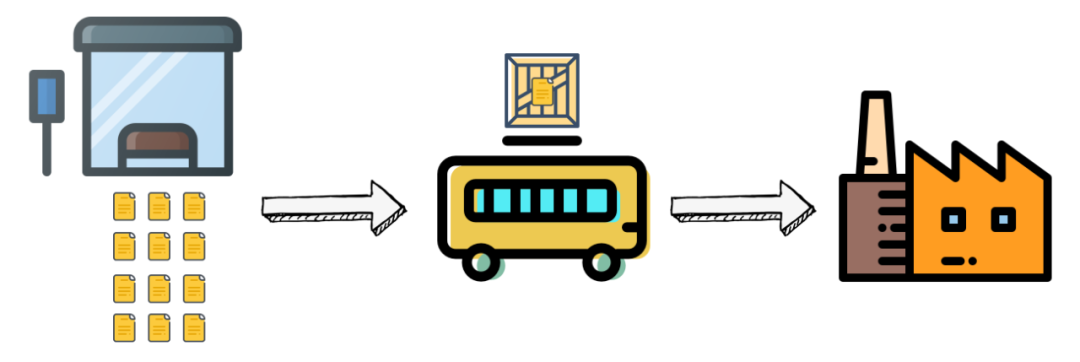
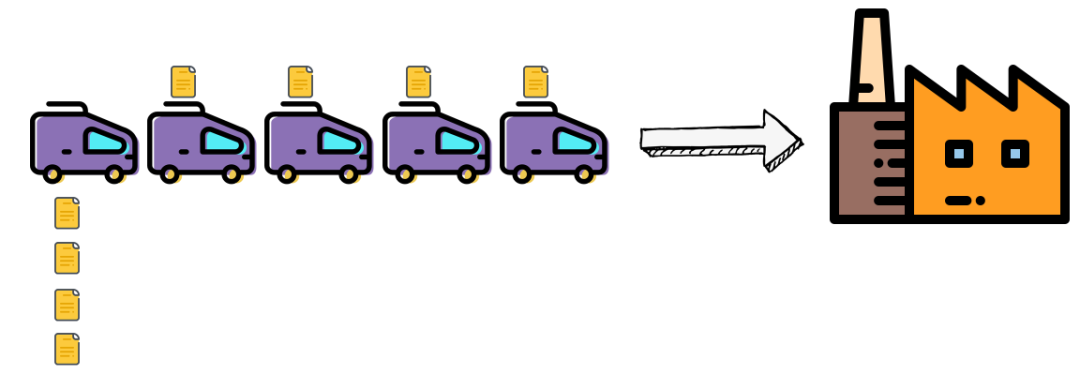







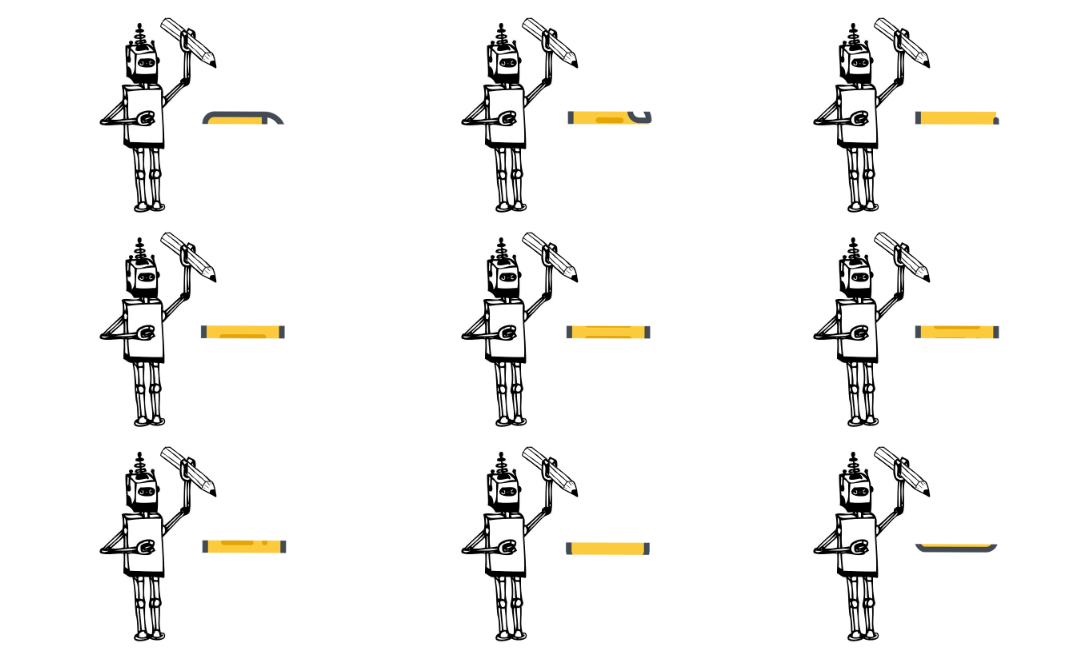



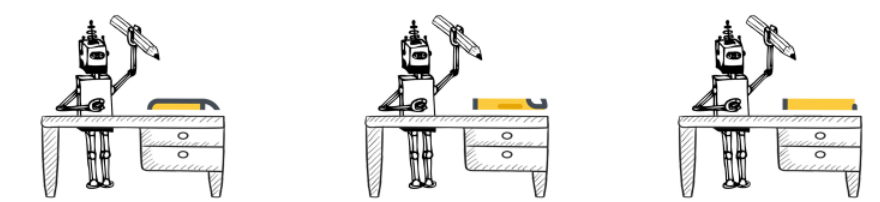

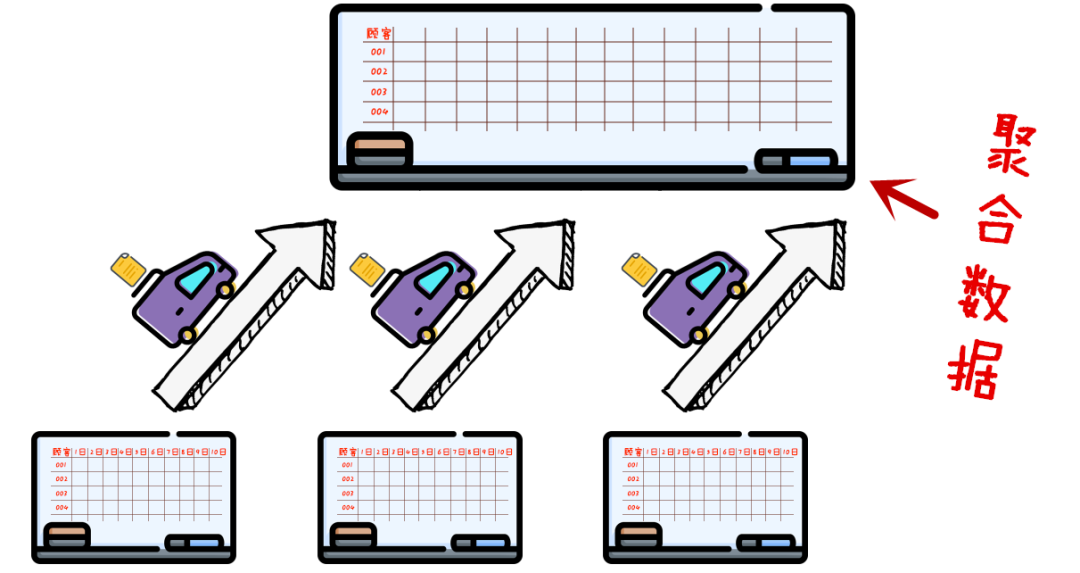




你把数据流想象成水龙头里流出来的水,原来我们流出一滴就做一次计算,现在我们拿一个桶,在下面接满一桶再拿给 Flink 计算。
再打个比方,就像你追剧,原来出一集你看一集,现在你攒十集一起看,不也行吗?


比如,批计算有一个语义是“停止”,但流计算就没有“停止”,你就必须用一套简洁易懂的 SQL 语言逻辑实现又能描述批的行为又能描述流的行为。
再比如,流式引擎一般从 Kafka 这样的中间件里读取数据,但批式引擎会从落盘之后的永久存储里读数据。面对两种数据源,Flink 要能用一套方式对它们进行操作。
这些都要求设计者对计算引擎的逻辑有非常深刻的理解。
其实,Flink 社区里很多人都是利用业余时间义务工作的。
对于很多程序员来说,干活绝不仅仅是为了养家糊口。能够遇到志同道合的人,一起创造一个更完美的世界,这才是真正的激情所在。

“毕竟两个团队相隔千里,还得用英语线上交流,真想打起来也不容易。。。
再说,虽然我们中国的场景确实是最丰富的,但这也不代表他们有的场景你都有,而且欧洲团队天然对欧美文化和市场更了解。这么几年磨合下来,我们最大的心法就是“相互尊重,相互认可”。
尊重是一种态度,认可是一种能力。”



时间就是金钱
再自我介绍一下吧。我叫史中,是一个倾心故事的科技记者。我的日常是和各路大神聊天。如果想和我做朋友,可以搜索微信:shizhongmax。
哦对了,如果喜欢文章,请别吝惜你的“在看”或“分享”。让有趣的灵魂有机会相遇,会是一件很美好的事情。
Thx with  in Beijing
in Beijing
评论