来源:QECon质效前沿
作者:茹炳晟(腾讯T4级技术专家,腾讯研究院特约研究员,业界知名实战派研发效能和软件质量双领域专家。)
之前读了一篇文章:“外卖骑手,困在系统里”,引发了我很多的思考,后来有幸和作者有过一次交流更是让我印象深刻。然后我写了一篇文章“如何用研发效能搞垮一个团队”引起了业界同行大量的讨论与关注,今天想借此继续来聊聊研发效能提升过程中另一个无法回避的的话题:“度量”。
先看一张图,这是英国街头的房屋,你可能好奇这些房屋的窗户为什么都被封了起来。

这其实是“窗户税”所引发的不良后果。
1696年之前,英国政府对于个人房屋的税收采用的是“壁炉税”,也就是根据屋内的壁炉数量来计算应缴税费的,这就要求税务员进屋查看,这无形中就增加了税收的难度,所以1696年之后,改为了计算窗户数量来计算应缴税费的“窗户税”,这样税务人员就不需要进门,能直接在街道上数窗户就行了。
面对此种“度量”手段,为了少缴税的房东也没闲着,除了买油灯、堵窗户以外,在屋顶开天窗也逐渐流行了起来。结果,除了在昏暗的房屋里搞出了一大批近视眼,由此刺激了照明业和眼镜业的发展外,税收机构几乎一无所获。
再来看看我们身边的案例:海底捞。

海底捞CEO张勇为了提高用户的满意度,一度在用餐体验方面花了很多心思,并要求服务员严格遵守。
比如只要是来吃火锅的戴眼镜的客人,都要给他一块眼镜布;杯子里的饮料低于1/3,就要赶紧给客人加饮料;如果客人带了手机,把手机放在桌上,要赶紧用一个塑料袋把它给套上。如果做不到,就扣服务员的服务分,最后直接反映在工资绩效上。
这样的“度量”体系设计直接导致了服务员为了绩效而不断地“骚扰”顾客。顾客吃完准备走了不需要饮料了,不行,必须加满才能走。顾客不喜欢用塑料袋把手机套上,不行,我的地盘我做主,必须要套上。结果直接导致了一系列用户体验的问题。
其实,还有很多由于度量体系设计不当而引发“内卷”等不良行为的案例。如果想进一步了解,可以关注一下美国的历史学家杰瑞缪勒写的《指标陷阱》一书,保证你会“大开眼界”。

这些度量为什么都会失败呢?正如我在之前那篇文章中提到的,面对变革,最重要的并不是方法和技术的升级,而应该是思维模式的升级。我们身处数字化的变革之中,需要转换的是自己的思维模式,我们需要将工业化时代科学管理的思维彻底转为字节经济时代的全新思维。
对于软件研发效能的度量,绝大多数时候我们都还在用工业化时代形成的管理理念来试图改进字节经济下的研发模式。时代变了,很多事物的底层逻辑都已经变了,工业化时代形成的科学管理理念在字节经济的今天是否还依然适用?值得我们深思。
下面我们就研发效能度量过程中常犯的错误来展开讨论,希望能借此引发大家的思考。
4.1 使用容易获得的量化指标
度量数据收集的难易程度不同,容易收集的数据往往实用价值低(比如代码行),难收集的数据往往度量价值更高(比如:产品用户价值,NPS等)。我们通常有一种天然倾向,就是把焦点放在最容易量化的目标上,把它作为解决复杂问题的抓手。用不了多久,人们就只重视那些可量化的目标,而忽略那些不可量化的目标。
- 首先,那些容易量化的次要目标(比如:代码行人天),会逐渐排挤掉那些难以量化但非常重要的目标(比如:代码影响力)。
- 其次,容易量化的目标(比如:个人工作时长)往往是局部目标,而难以量化的目标(比如:项目价值交付)往往是整体目标。局部目标更容易达成,时间久了以后,局部目标就会排挤掉整体目标。
- 最后,容易量化的目标(比如:缺陷数量)往往是短期目标,而难以量化的目标(比如:长期质量)往往是长期目标。短期目标往往关注当下的绩效,属于“救火”的范畴,而长期目标则属于“未雨绸缪”的范畴,人的短视很容易让短期目标排挤掉长期目标。
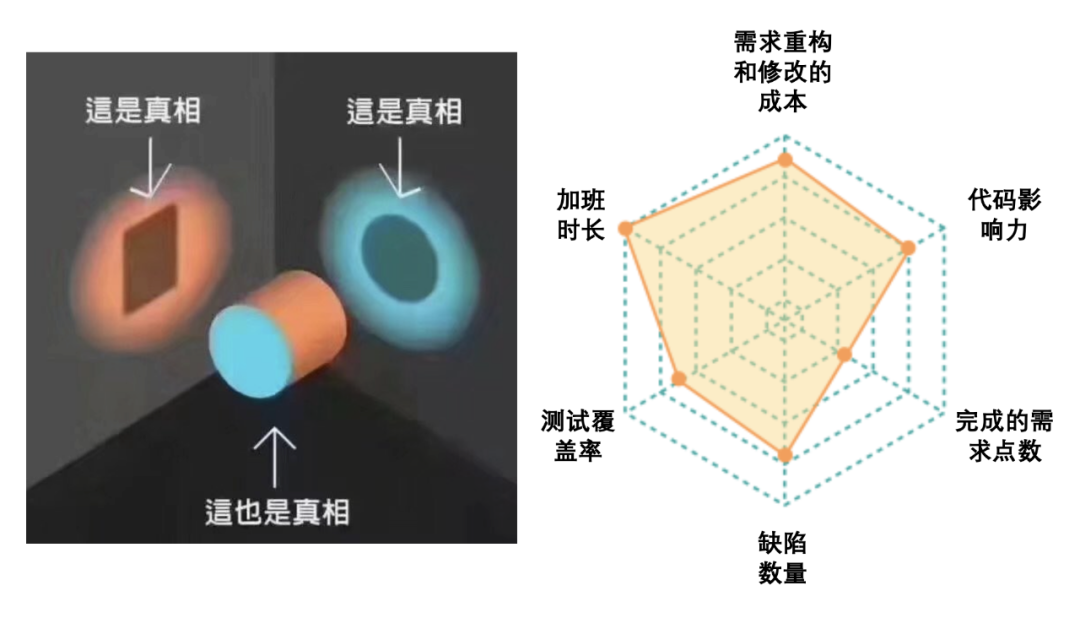
试图通过单一维度去做度量也是非常不可取的,因为事物往往具有多面性,事物本身的复杂度就决定了度量也必须是全方位,多维度的。因此,我们更应该建立度量的雷达图,从事物的多个维度来进行度量。雷达图中度量矩阵的设计要做让各个度量指标之间有相互牵制的作用,比如当你人为“粉刷”其中某个度量值的时候,其他的度量值将会“出卖”你。图中的度量雷达图就是一个很好的例子。- 当你的“缺陷数量”低的时候,不能直接得出你写代码质量高的结论,而要结合“完成的需求点数”来做综合判断。
- 当你的“加班时长”长的时候,不能直接得出你是高绩效员工的结论,而要结合“完成的需求点数”、“代码影响力”和“缺陷数量”来做综合判断。
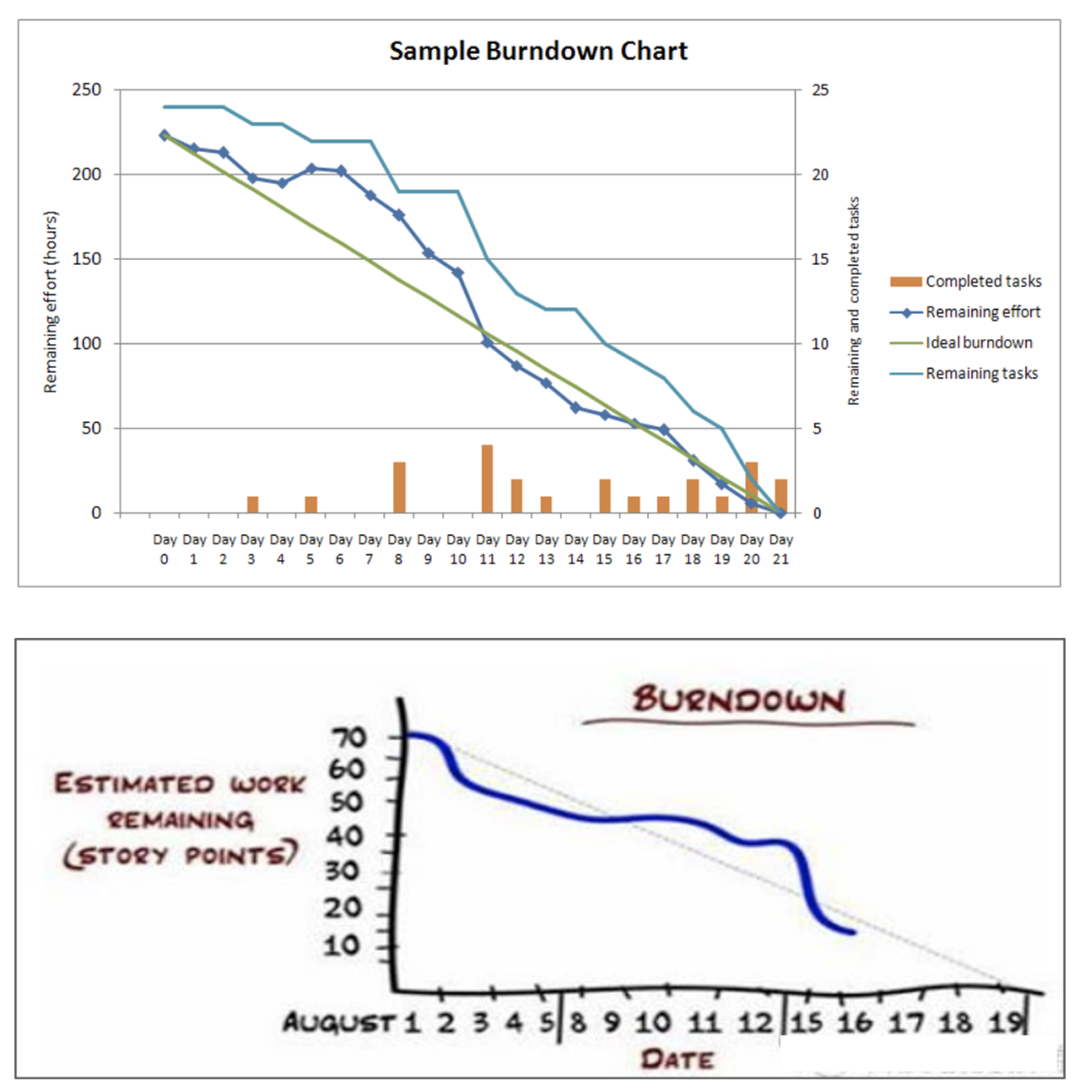
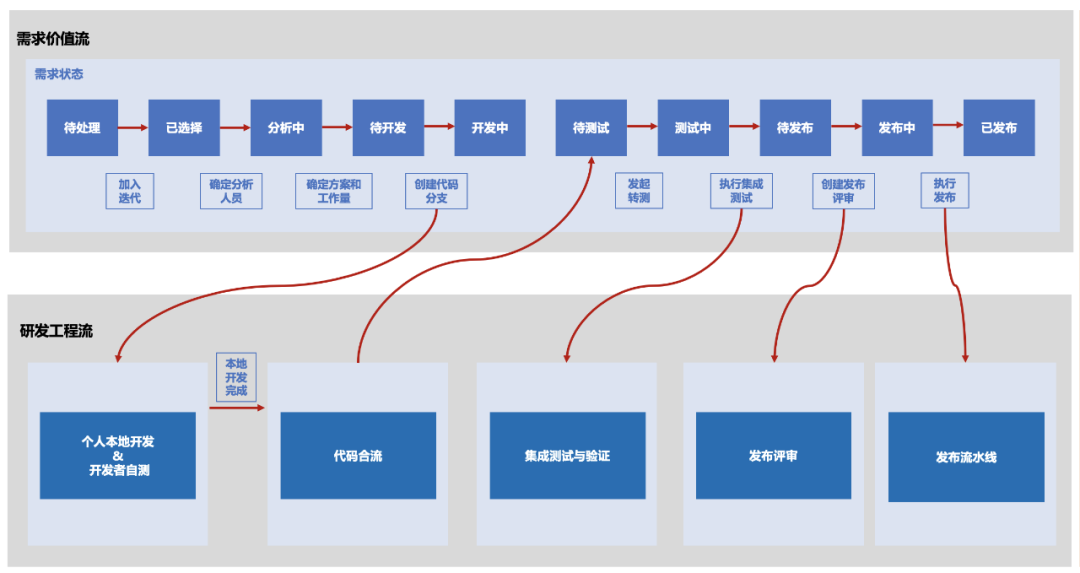
由此可见,如果你想同时人为优化所有指标,那几乎是不可能的,这正是度量雷达图的魅力所在。 在企业中,度量数据的获取一定要实现自动化,如果你的度量数据都依赖于工程师的手工录入来获取,一方面工程师会对此种工作模式十分反感,另一方面会让后续的度量分析完全失去意义,因为人工录入的数据或多或少已经存在了很多失真,而且很多数据的录入时间是有很大参考价值的,如果数据不是实时获取,而是人工填充的,那么数据本身就失去了度量的意义。 在Scrum团队,有个很好的例子可以说明这点。燃尽图是用来反应迭代任务完成情况的全局视图,理想中的燃尽图应该是下图中的上半部分,但是实际项目中的燃尽图往往看起来更像下图中的下半部分。原因很简单,因为工程师不会实时去更新任务的完成状态,而是等到迭代快要结束的时候,批量集中地人工更新任务状态,所以燃尽图就成为了这种到了最后一天断崖式下降的样子。试想一下,这样的过程度量是不是就完全失去了原本的意义,而且这些获取的数据也不能用来做进一步的分析,因为时间维度严重失真了。要解决这一问题,必须让研发过程数据采集通过工具平台自动完成,而不能依赖人工录入,腾讯的“研发效能双流模型”就提供了很好的思路。比如在双流模型的支持下,当feature分支成功合并到master的时候,就会主动触发需求状态的流转,从原来的“开发中”转到“待测试”,可以完美实现了“需求价值流”和“研发工程流”两者之间的联动。关于度量有一句名言是这么说的,你度量什么,就会得到什么,而且往往是以你所不期待的方式得到的。我一直说一句话,当你把度量变成了个人考核的时候,永远不要低估人们在追求指标方面“创造性”,当然这个创造性是打了引号的。所以我一直反对将度量与个人KPI绑定,因为度量本身很难做到客观和公正,如果直接作用于个人,而且强绑定个人绩效可能反而会适得其反,容易导致工程师纯粹面向指标去开展工作,而不是面向结果。 虽说不建议将度量和个人绩效绑定,但是将度量和团队绩效绑定还是很有必要的,通过度量能够反馈团队宏观层面问题,进而可以采取有效措施去改进。要注意的是,团队度量依然无法做到客观和公正,但是这些不够客观和不够公正的因素可以在团队lead层面进行补偿和调整。然后在团队内部消化掉。度量从来不是目标,而应该是实现目标的手段。度量是为目标服务的,所以好的度量设计一定对目标有正向牵引的作用,如果度量对目标的负向牵引大于正向牵引的话,这样的度量本质上就是失败的。 举个例子,现在国内很多软件企业都使用Sonar来实现代码静态质量的把控,为了推进Sonar在团队内的普及,不少企业会用“Sonar项目接入率”这样的指标,也就是有多少百分比的项目已经在持续集成CI中启用了Sonar,来衡量静态代码检查的普及率。这个指标看似中肯,实际上对于实现最终目标的牵引力是比较有限的。使用Sonar的最终目标是提升代码的质量,只是接入Sonar并不能实际改善代码的质量,而且还容易陷入为了接入而接入的指标竞赛。理解了这层逻辑,你会发现使用“Sonar严重问题的平均修复时长”和“Sonar问题的增长趋势”其实更有实践指导意义。 所以,一个好的度量,一定要为解决本质问题服务,并且要能够引导出正确的行为。我们看到一个人获得了成功,就会立刻认为他过去所有的行为都是那么地有道理。我们看到一公司获得了成功,就会觉得他们采取的策略和工程实践是多么有效。这正是“比较思维”的可怕之处。实际上,没有哪家企业是通过盯住竞争对手而获得成功的。 OKR在Google的成功应用使得很多公司对此实践趋之若鹜,但是通过使用OKR取得成功的企业又有多少?这种“追星式”的度量只能让你陷入更深的内卷。 对于研发效能的度量体系,切记不要盲目生搬硬套“大厂”所谓的最佳实践,也不要拿自己的度量实践去和大厂的比较,你们的上下文不同、组织生态不同,这药给大厂吃可以治病,给你吃可能致命。不要在没有任何明确改进目标的前提下开展大规模的度量,因为度量是有成本的,而且这个成本还不低。很多大型组织往往会花大成本去建立研发效能度量数据中台,指望通过研效大数据的分析来获取改进点。这种“广撒网”的策略虽然看似有效,实则收效甚微。事实证明,度量数据中台的建设成本往往会大幅度高于实际取得的效果。 比较理想的做法应该是通过对研发过程的深度洞察,发现有待改定的点,然后寻找能够证实自己观点的度量集合并采取相应的措施,最后再通过度量数据来证实措施的实际价值,这种“精准捕捞”的策略往往更具实用价值。 好了,今天我们就先聊到这里,感谢您的阅读,以后有机会我会对研发效能度量的话题做更多的分享。IDCF DevOps黑客马拉松,独创端到端DevOps体验,精益创业+敏捷开发+DevOps流水线的完美结合,2021年仅有的3场公开课,数千人参与并一致五星推荐的金牌训练营,追求卓越的你一定不能错过!11月6-7日,深圳站,企业组队参赛&个人参赛均可,一年等一回,错过等一年,赶紧上车~👇