
机器学习数学基础:从奇异值分解 SVD 看 PCA 的主成分
今天我们来看一个在数据分析和机器学习领域中常用的降维方法,即主成分分析(PCA)。它是探索性数据分析(EDA)和机器学习算法对数据的基本处理方法。
1引言
首先,我们来看一下机器学习中数据的表示形式。如下图所示,一般用一个矩阵
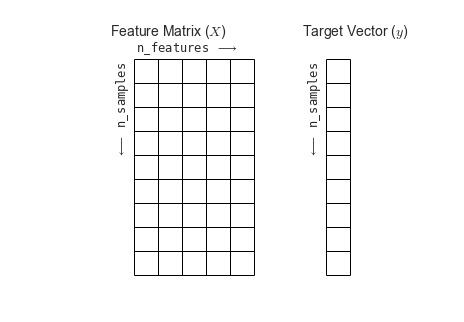
为什么要对
嫌 长得太胖穿得太多,一下看不清。让它减减肥,好观察啊。
用行话说就是,特征太多,让人迷失,需要精简,才能在屏幕上展现数据的整体样貌。
嫌 长得没啥特点,没有棱角,总之看了没留下啥印象。
用行话可以说是,特征不典型,特征之间线性相关,不利于对数据的后续处理和分析。
总之,嫌数据矩阵
2主成分分析
今天主要看的 PCA 方法就是试图在原始高维数据矩阵中找到特征的线性组合以构造更具代表性的数据特征表示形式,在降维的同时让数据更有精气神。
降维问题本身可以看作最优化问题,但本篇主要是从奇异值分解的角度来解读 PCA,因此对于降维问题的描述不作详细展开。简而言之,PCA 降维的目标为,
一方面为了减少数据的特征数,因此要挑选出最具代表性的一些特征。
保持特征的可分性,即在原来空间中有明显差异的数据在降维后也希望尽量保持差异。换句话说,保持数据间的线性结构,比如在原始空间中离得远的数据在降维后也希望离得远,近的自然也一样。
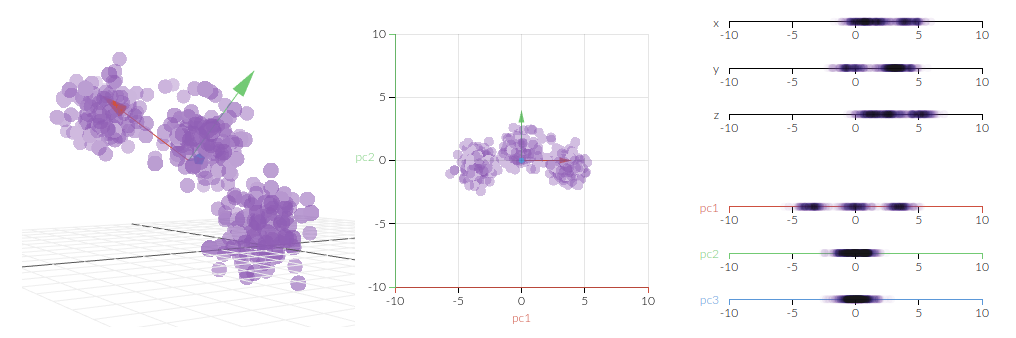
我们结合一个简单例子来阐述一下 PCA。如上图所示,给你一百个数据,每个数据只用两个特征(比如身高和体重),这里为了可视化,分别将它们看成
PCA 的目的之一是从这些数据自身出发,找出新的相互正交的坐标轴(将它们看成新的特征),希望这些特征之间不线性相关。这些正交轴也称为数据特征空间中的主成分(PC),最后将数据点投影到这些 PC 上得到新的坐标表示。
我们假设只用一个特征来刻画上面这批数据,也就是说只需要找出一个坐标轴,即一个 PC。这些数据坐标往这个 PC 投影得到新的坐标,而且每个数据只有一个坐标了。那么你怎么选这个 PC 呢?
为了让新坐标尽量能够区分开不同的数据,我们希望沿着这个 PC 能捕获到数据中最大的差异。看下面的动图,我们假设 PC 经过数据集的中心点,然后这些数据点往不同的 PC 上投影,最终都投到一条直线上,那么哪条线将这些数据分开得最好呢?
相信大家能感觉出哪个方向好。但是问题来了,怎么用数学公式来量化不同方向的好差呢?
对了,可以用方差。再加上如果考虑多个 PC 之间的相关性的话,那就是协方差矩阵。
.协方差矩阵
在机器学习中,计算两个特征
式中
而由两个特征
如果有多个特征,记为
协方差矩阵衡量的是数据的不同坐标分量两两之间一起变化的程度。如果它是一个对角矩阵,说明特征之间没有线性相关性,这也是 PCA 所追求的目标之一。
简化形式
如果将这些特征
接下来我们用两种方法来得到 PC。
.特征分解
由于协方差矩阵是一个半正定对称矩阵,因此我们可以对它作特征分解,
可以看到,协方差矩阵被分解为由特征向量按列组成的矩阵
这里需要注意的是,这些特征向量和特征值不是随便排列的,例如,特征值在
然后,我们可以将数据投影到这些 PC 上去,即
新特征的协方差矩阵是对角矩阵,而且,对角线上的方差是从大到小排列的,这重要吗?是的,不要忘了,我们还要降维,因此将数据点投影到前
而且,这些保留的前
.奇异值分解
我们也可以用奇异值分解来计算 PC,但不是分解协方差矩阵,而是分解特征矩阵。
先对
然后代入协方差矩阵,
现在的 PC 是矩阵
跟上面特征分解的协方差矩阵比较可得,
但这里好像没有用到它们啊。其实不然,一般来说,大佬是在幕后操作的,这里处在 C 位的奇异值或者特征值们也一样。
要知道,我们最后得到的 PC 都是按大佬们的大小来排座位的。
.换个角度
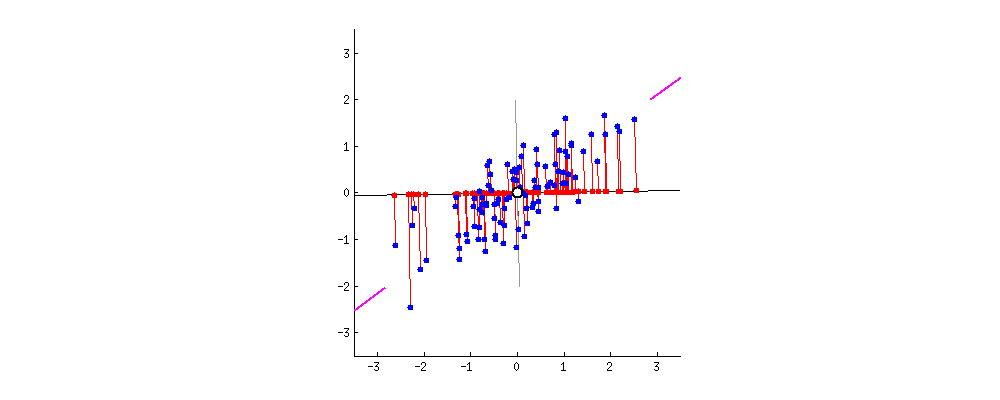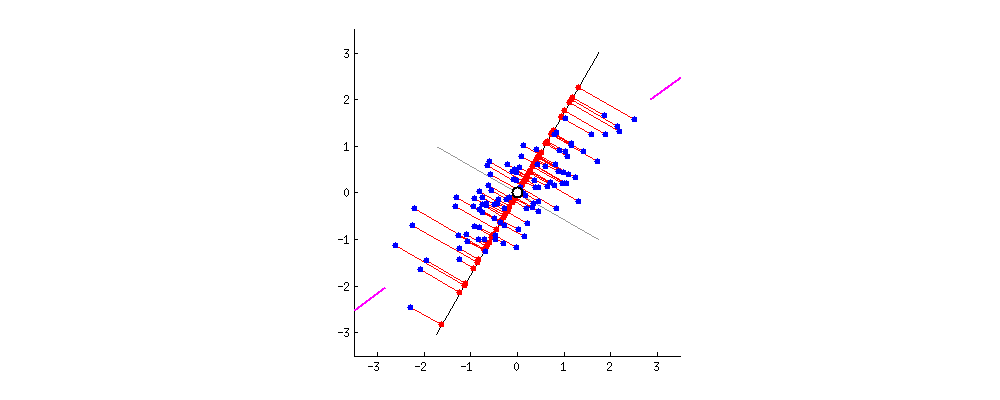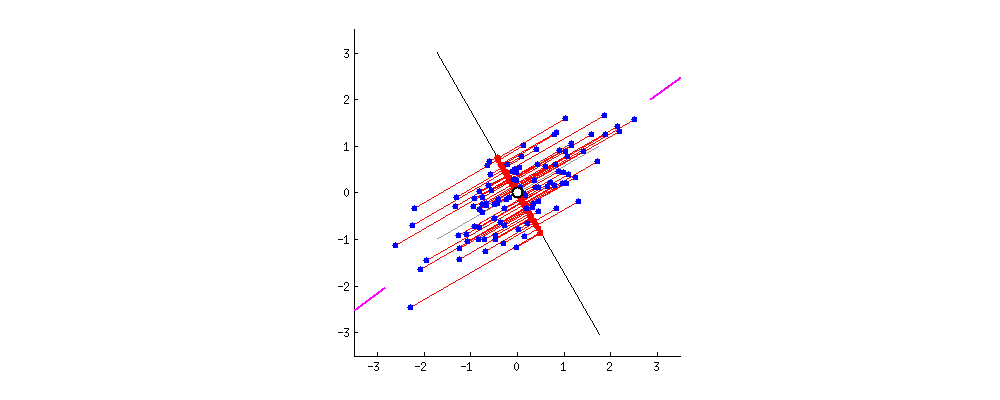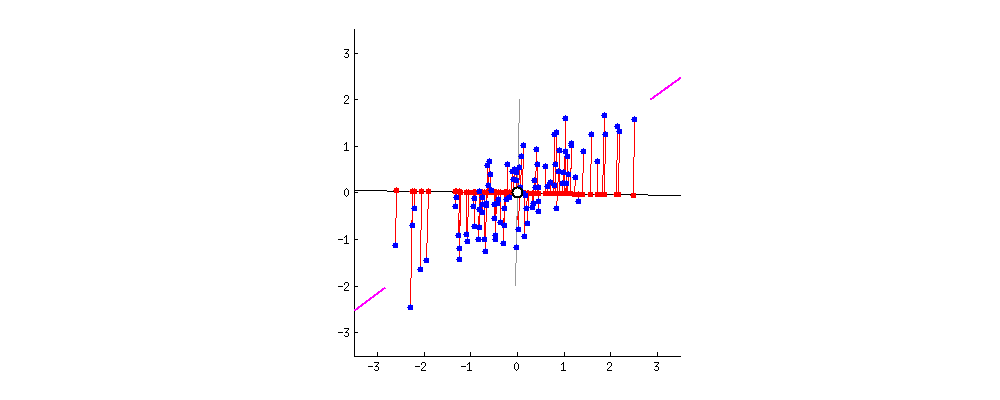
除了从方差角度考虑外,也可以从数据点到 PC 轴的垂直距离来考虑问题。
你可以想象下图中的黑线是实心杆,而每条红线表示弹簧。弹簧的能量与它的长度平方成正比(物理学上称为胡克定律),因此,如果所有弹簧长度平方之和达到最小时,杆子将处于平衡状态。下图模拟了达到平衡状态的过程,
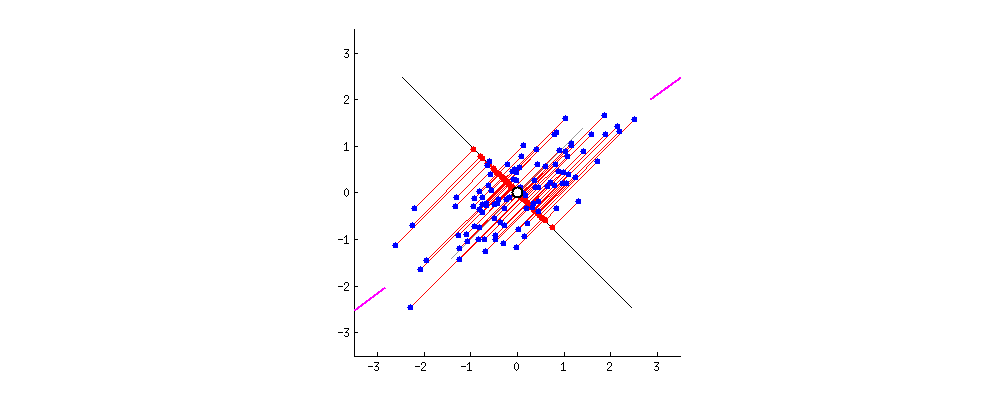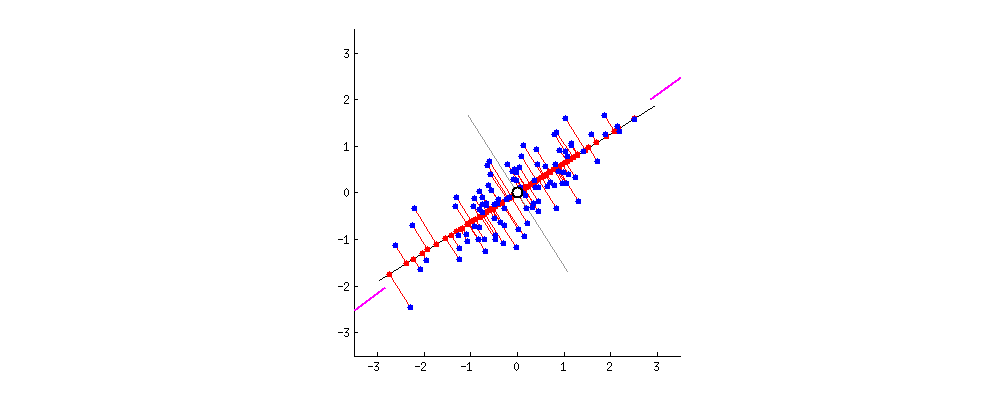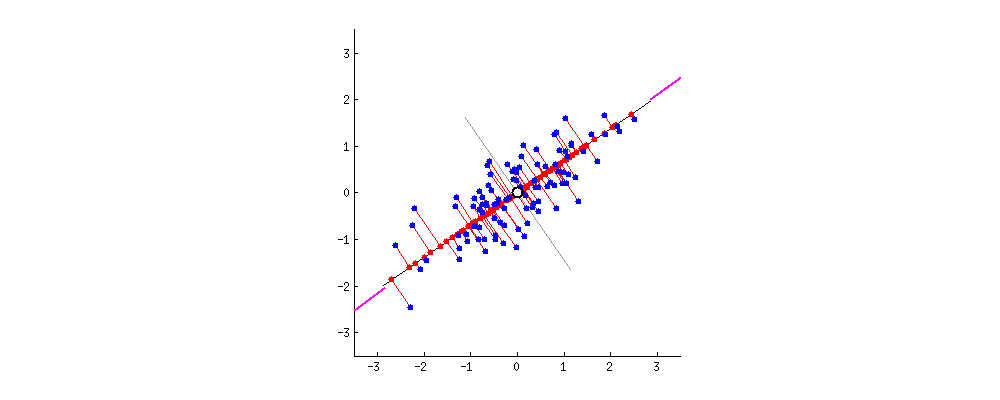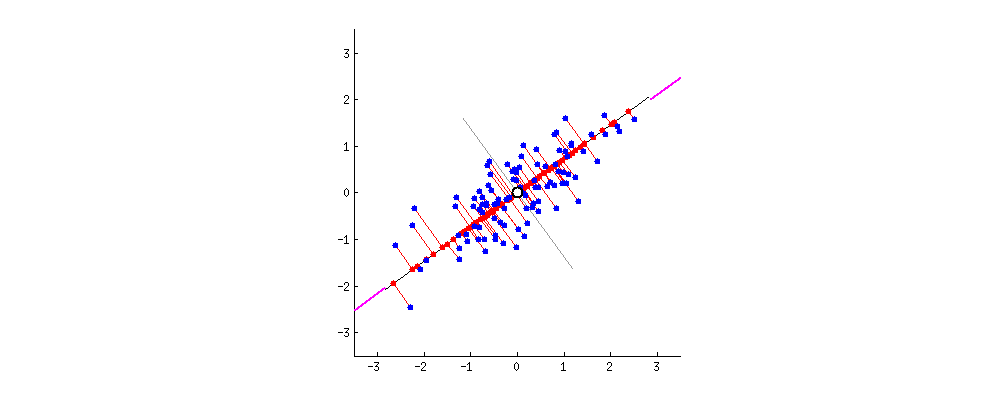
这里其实想说的是,PCA 方法可以从多个角度去理解,那么对应的数学问题也会有所不同,但这个不是本篇的重点。
3降维实战
import numpy as np
import seaborn as sns
.小型数据集
iris = sns.load_dataset('iris')
先看一眼数据,显示前五行。
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
Iris 鸢尾花数据集是一个经典数据集。
数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这 4 个特征预测鸢尾花卉的品种。上面五列对应的特征说明,
sepal_length花萼长度sepal_width花萼宽度petal_length花瓣长度petal_width花瓣宽度species品种(共 setosa, versicolour, virginica 三类)
.特征矩阵
我们把最后一列去掉,只取前四列,可以拿来预测最后一列。因此,特征矩阵定义如下,
X = iris.values[:,:-1]
X = X.astype(np.float64)
# 查看前五行数据
X[0:5]
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]])
# 1、对特征矩阵零中心化
X -= np.mean(X, axis=0)
看一下协方差矩阵
cov_XTX = X.T@X
cov_XTX
array([[102.16833333, -6.32266667, 189.873 , 76.92433333],
[ -6.32266667, 28.30693333, -49.1188 , -18.12426667],
[189.873 , -49.1188 , 464.3254 , 193.0458 ],
[ 76.92433333, -18.12426667, 193.0458 , 86.56993333]])
.降维
# 2、对特征矩阵进行 SVD 分解
U, Sigma, VT = np.linalg.svd(X, full_matrices=False)
U.shape, Sigma.shape, VT.shape
((150, 4), (4,), (4, 4))
由于上面我们设置参数 full_matrices=False,所以得到的矩阵
我们来构造新的特征,但要注意,上面函数 np.linalg.svd 返回的矩阵 VT 是指
Y = X@VT.T
再看一下这个新特征矩阵的协方差矩阵
cov_YTY = Y.T@Y
cov_YTY
array([[ 6.30008014e+02, -8.12751455e-14, -1.46101800e-14,
-6.74844752e-14],
[-8.12751455e-14, 3.61579414e+01, -8.02807470e-15,
9.98660131e-15],
[-1.46101800e-14, -8.02807470e-15, 1.16532155e+01,
-8.45168460e-16],
[-6.74844752e-14, 9.98660131e-15, -8.45168460e-16,
3.55142885e+00]])
非对角线上的协方差都是极小了吧,当零看,因此是个对角矩阵。
4左奇异向量
从前文中,大家已经看到了 PCA 和 SVD 之间的联系了。最后,我们来试图对最终得到的 PC 从奇异值分解的角度作进一步的解读。
我们知道,新的特征矩阵可以这么计算,
如果最终只想要
这就是将
我们只知道现在确实已经去除了新特征之间的线性相关性(协方差为零)。但是,得到的新坐标
另外,这里好像没有左奇异向量什么事情呀。甚至连处在 C 位的矩阵之芯也没有直接出场,只用到右奇异向量。这貌似总感觉不舒服,难道辛辛苦苦分解出仨,你就用了边上一个就完事了?
我们回到奇异值分解,
发现了吧,这就是新坐标
好了,这样来看的话,正是处在 C 位的矩阵之芯和左奇异向量联手打造出了新的特征。
这样子是不是可以更好地理解新生成的特征呢?我们不妨用前一篇中的理论来试着解读一番。
.画龙点睛
那就是特征矩阵
而
如果要降维到
特征变换
如何从数据的特征矩阵
由
可知,其中 是对原来的特征矩阵的列(特征)进行线性组合,再用 的对角元素分别缩放,构造出了最终的新特征。 如果把特征矩阵
看成线性变换,那就是,
5小结
矩阵
矩阵作为变换的化身,往往是以
这样的形式发挥作用。给人感觉矩阵以这种身份出现的情况更多? 矩阵仅仅表示数据,并不是用来变换别人。这种场景也不少,比如本篇里的例子,它是以列向量集合的形式出现。
但不管它是什么身份,都可以对矩阵作奇异值分解,而且分解以后可以得到更好的解读,不管是变换也好,还是数据表示也好。
