
记一次 Druid 超时配置的问题,引发对 Druid 时间配置项的探究
开心一刻
一天在路边看到一个街头采访
记者:请问,假如你儿子娶媳妇,给多少彩礼合适呢
大爷:一百万吧,再给一套房,一辆车
大爷沉思一下,继续说到:如果有能力的话再给老丈人配一辆车,毕竟他把女儿养这么大也不容易
记者:那你儿子多大了?
大爷:我没有儿子,有两个女儿

问题背景
最近生产环境出现了一个问题,错误日志类似如下:
Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 1010, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user日志信息提示的很明显:获取 JDBC Connection 失败,因为从 Druid 连接池获取 connection 超时了。

上图的意思是:执行 select * from tbl_user 之前,需要从 druid 连接池中获取一个 connect
而此时连接池的状态是:一共 10 个激活的 connect ,连接池最大创建 10 个 connect ,正在执行 SQL 的 connect 也是 10 个。
所以不能创建新的 connect 那就等呗。一共等了 1010 毫秒,还是拿不到 connect ,就抛出 GetConnectionTimeoutException 异常。
简单点说就是,连接池中连接数不够,在规定的时间内拿不到 connect。
那有人就说了:连接池的最大数量设置大一点,问题不就解决了吗?
最大连接数设置大一点只能降低问题发生的概率,不能完全杜绝问题。因为网络条件、硬件资源的使用情况等等都是不确定因素。
今天要讲的不是连接池大小问题,而是超时设置问题。我们慢慢往下看。
问题复现
我们先来模拟下上述问题:
MySQL 版本:5.7.21 ,隔离级别:RR
Druid 版本:1.1.12
spring-jdbc 版本:5.2.3.RELEASE
DruidDataSource 初始化
为了方便演示,就手动初始化了:

多线程查询
线程数多于连接池中 connect 数。

模拟慢查询
如果查询飞快,15 个查询可能都用不上 10 个 connect ,所以我们需要简单处理下。
很简单,给表加写锁:
LOCK TABLES tbl_user WRITE给表 tbl_user 加上写锁,然后跑线程去查询 tbl_user 的数据。
异常演示
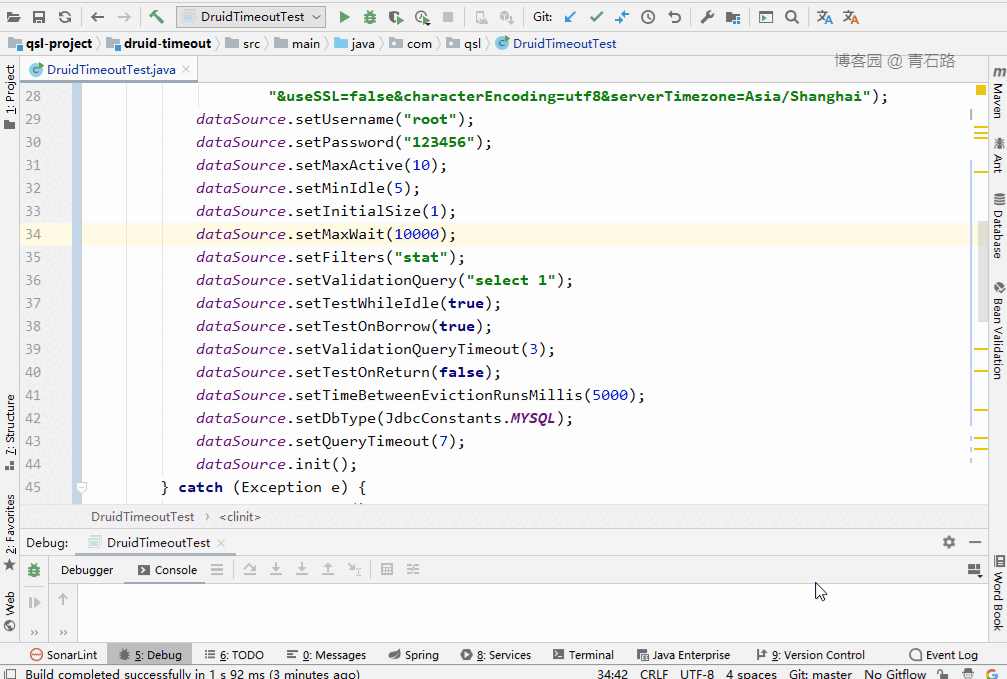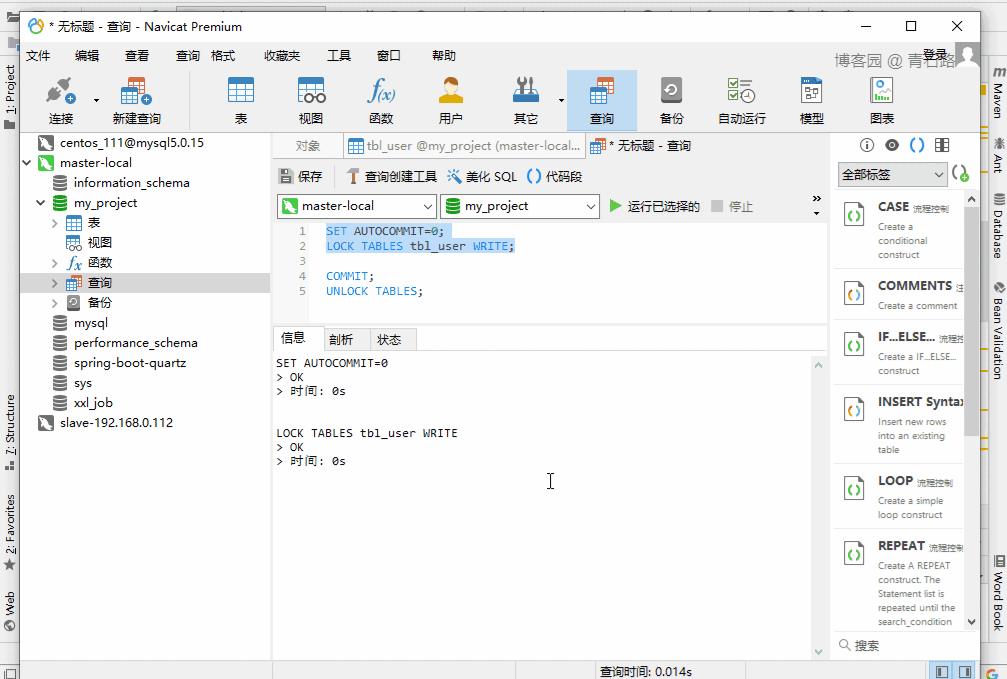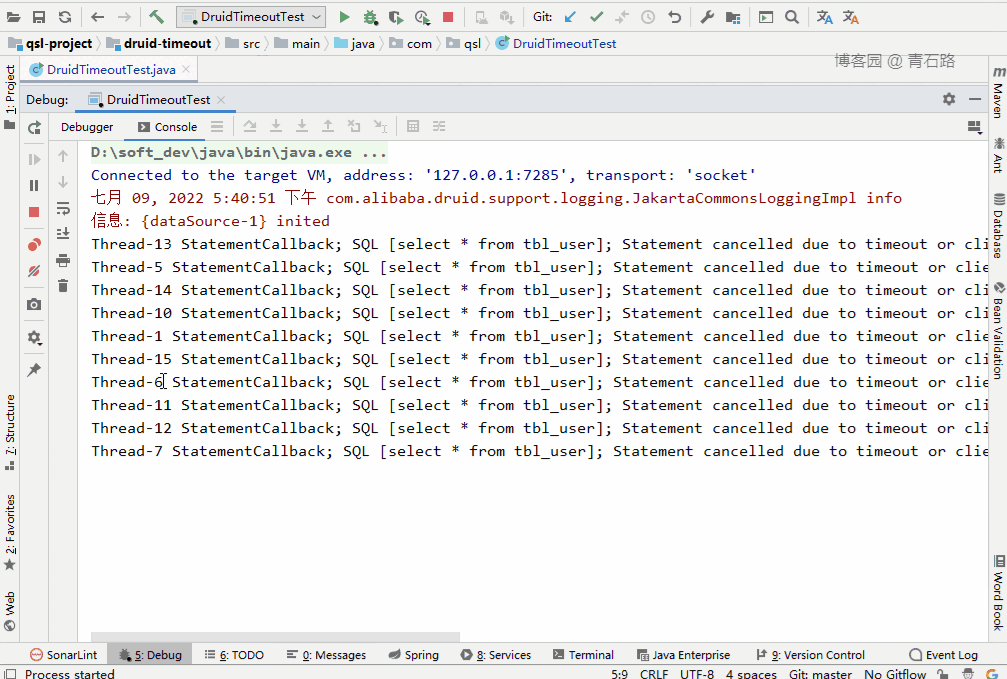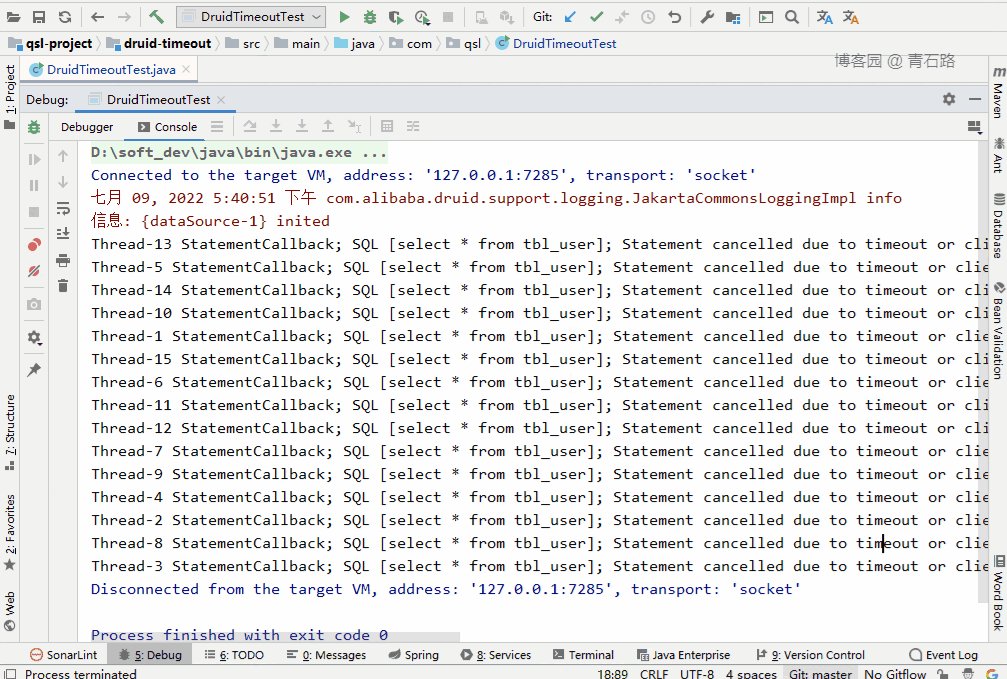
先锁表,再启动程序
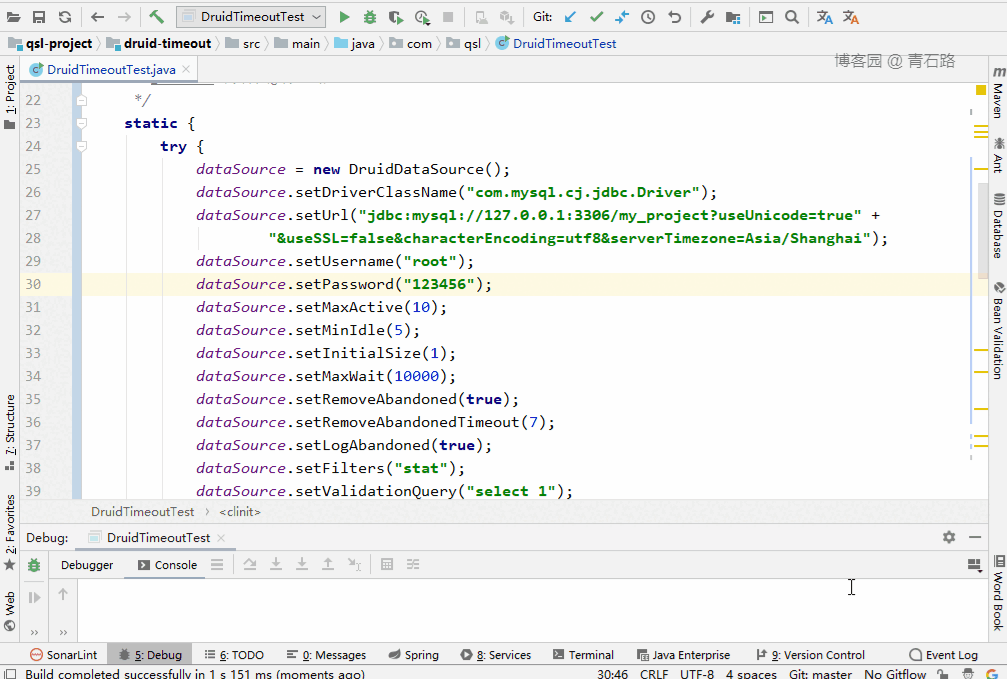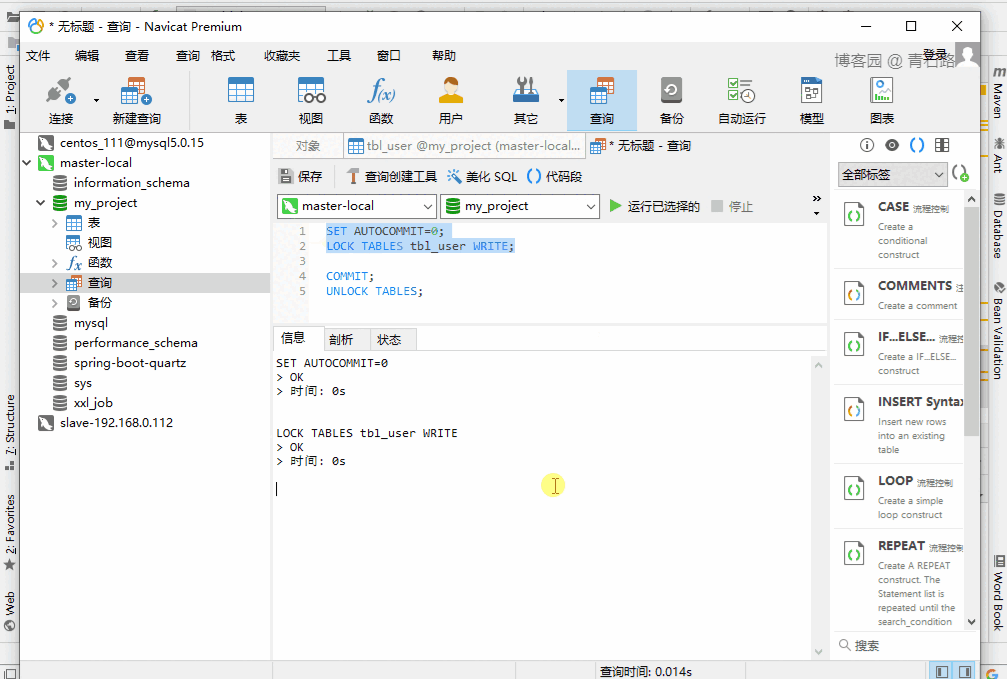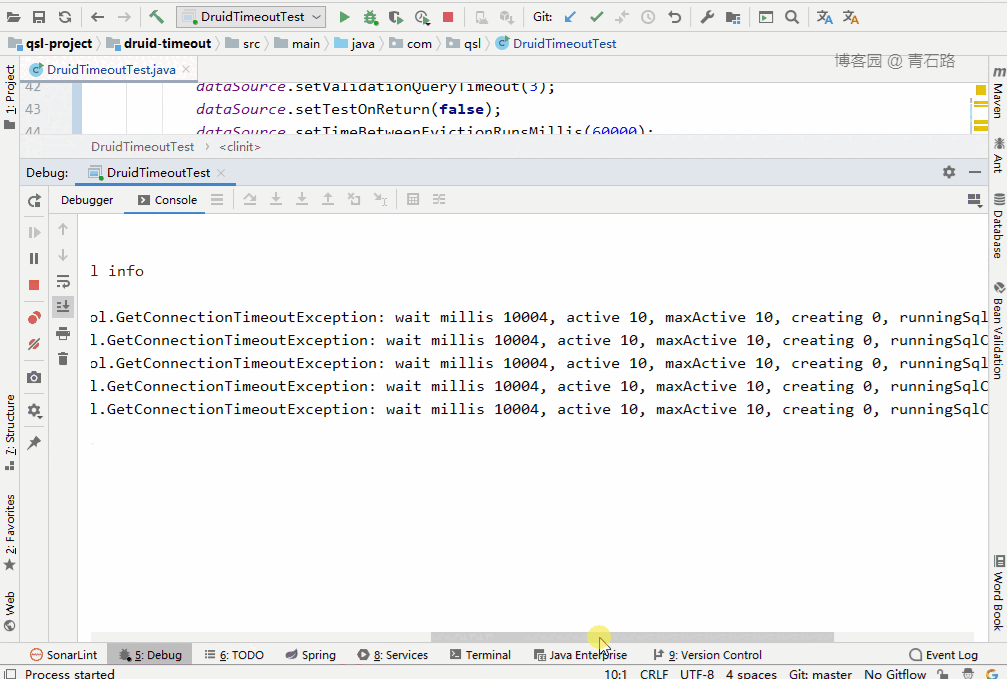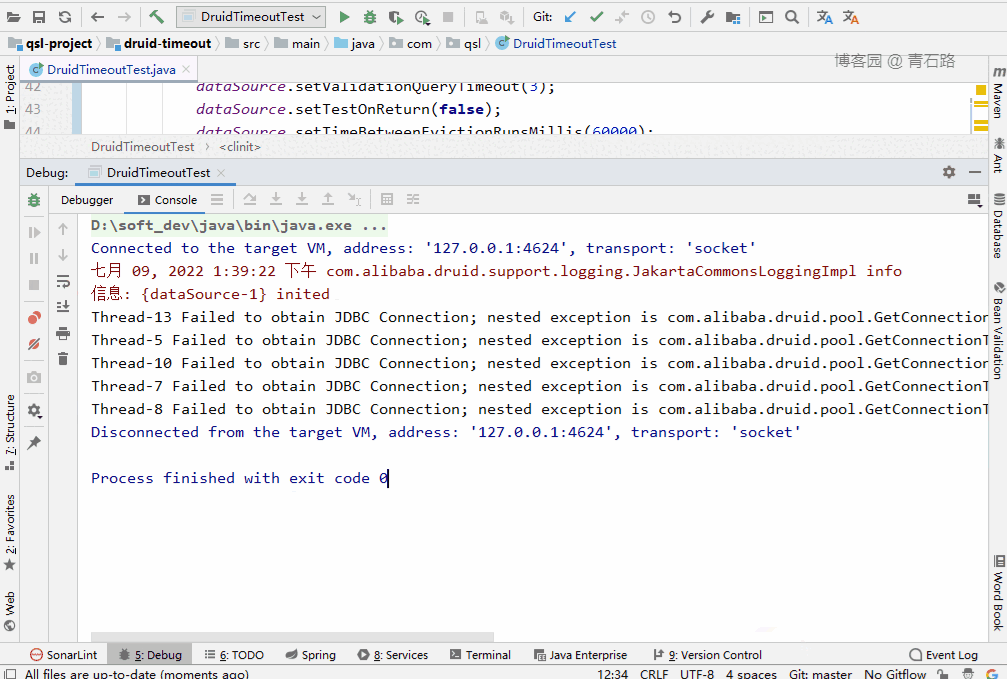
可以看到,15 个线程中,有 5 个线程获取 connect 失败:
Thread-13 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-5 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-10 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-7 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-8 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user
示例代码:druid-timeout
https://gitee.com/youzhibing/qsl-project/tree/master/druid-timeout
时间配置项
Druid 中关于时间的配置项有很多,我们我们重点来看下如下几个:
maxWait
最大等待时长,单位是毫秒,-1 表示无限制。
从连接池获取 connect;
如果有空闲的 connect ,则直接获取到;
如果没有则最长等待 maxWait 毫秒;
如果还获取不到,则抛出 GetConnectionTimeoutException 异常。
removeAbandonedTimeout
设置 Druid 强制回收连接的时限,单位是秒。
从连接池获取到 connect 开始算起,超过此值后, Druid 将强制回收该连接。
官网也有说明:连接泄漏监测。
https://github.com/alibaba/druid/wiki/%E8%BF%9E%E6%8E%A5%E6%B3%84%E6%BC%8F%E7%9B%91%E6%B5%8B
validationQueryTimeout
检测连接是否有效的超时时间,单位是秒,-1 表示无限制。
Druid 内部的一个检测 connect 是否有效的超时时间,需要结合 validationQuery 来配置。
timeBetweenEvictionRunsMillis
检查空闲连接的频率,单位是毫秒, 非正整数表示不进行检查。
空闲连接检查的间隔时间, Druid 池中的 connect 数量是一个动态从 minIdle 到 maxActive 扩张与收缩的过程。
connect 使用高峰期,数量会从 minIdle 扩张到 maxActive 。使用低峰期, connect 数量会从 maxActive 收缩到 minIdle 。
收缩的过程会回收一些空闲的 connect ,而 timeBetweenEvictionRunsMillis 就是检查空闲连接的间隔时间。
queryTimeout
执行查询的超时时间,单位是秒,-1 表示无限制。
最终会应用到 Statement 对象上,执行时如果超过此时间,则抛出 SQLException 。
transactionQueryTimeout
执行一个事务的超时时间,单位是秒。
minEvictableIdleTimeMillis
最小空闲时间,单位是毫秒,默认 30 分钟。
如果连接池中非运行中的连接数大于 minIdle ,并且某些连接的非运行时间大于 minEvictableIdleTimeMillis ,则连接池会将这部分连接设置成 Idle 状态并关闭。
maxEvictableIdleTimeMillis
最大空闲时间,单位是毫秒,默认 7 小时。
如果 minIdle 设置的比较大,连接池中的空闲连接数一直没有超过 minIdle ,那么那些空闲连接是不是一直不用关闭?
当然不是。
如果连接太久没用,数据库也会把它关闭(MySQL 默认 8 小时),这时如果连接池不把这条连接关闭,程序就会拿到一条已经被数据库关闭的连接。
为了避免这种情况, Druid 会判断池中的连接状态。如果非运行时间大于 maxEvictableIdleTimeMillis ,也会强行把它关闭,而不用判断空闲连接数是否小于 minIdle 。
再看问题
其实前面的示例中设置了。

获取 connect 的最大等待时长是 10000 毫秒,也就是 10 秒。
而 removeAbandonedTimeout 设置是 7 秒。
照理来说 connect 如果 7 秒未执行完 SQL 查询,就会被 Druid 强制回收进连接池,那么等待 10 秒应该能够获取到 connect 。
为什么会抛出 GetConnectionTimeoutException 异常了?
这也就是文章标题中的超时设置问题。
源码探究
很显然,我们从 dataSource.init(); 开始跟源码,会看到如下一段代码:

我们继续跟 createAndStartDestroyThread():

重点来了,我们看下 DestroyTask 到底是怎么样一个逻辑:

我们接着跟进 removeAbandoned ,关键代码:

如果 connect 正在运行中是不会被强制回收进连接池的。
回到我们的示例:connect 都是在运行中,只是都在进行慢查询,所以是无法被强制回收进连接池的,那么其他线程自然在 maxWait 时间内无法获取到 connect 。
至此,文章标题中的问题的原因就找到了。
那么问题又来了:removeAbandonedTimeout 作用在哪?
我们再仔细阅读下:连接泄漏监测
https://github.com/alibaba/druid/wiki/%E8%BF%9E%E6%8E%A5%E6%B3%84%E6%BC%8F%E7%9B%91%E6%B5%8B
Druid 提供了 RemoveAbandanded 相关配置,目的是监测连接泄露,回收那些长时间游离在连接池之外的空闲 connect。
可能因为程序问题,导致申请的 connect 在处理完 SQL 查询后,不能回到连接池的怀抱。那么这个 connect 处理游离态,它真实存在,但后续谁也申请不到它,这就是连接泄露。
而 removeAbandoned 的设计就是为了帮助这些泄露的 connect 回到连接池的怀抱。
解决问题
开启 removeAbandoned 对性能有影响,官方不建议在生产环境使用。
那么我们接受官方的建议,不开启 removeAbandoned (不配置即可,默认是关闭的)。
为了不让慢查询占用整个连接池,而拖垮整个应用,我们设置查询超时时间 queryTimeout 。
有两种方式,一个是设置 DataSource 的 queryTimeout ,另一个是设置 JdbcTemplate 的 queryTimeout 。
如果两个都设置,最终生效的是哪个,为什么?大家自己去分析,权当是给大家留个一个作业。
这里就配置 DataSource 的 queryTimeout ,给大家演示下效果:
可以看到,所有线程都获取到了 connect。
总结
Druid 的 removeAbandoned 对性能有影响,不建议开启。removeAbandoned 的开启后的作用要捋清楚,而非简单的过期强制回收;
Druid 的时间配置项有很多,不局限于文中所讲,但常用的就那么几个,其他的保持默认值就好。配置的时候一定要弄清楚各个配置项的具体作业,不要去猜!
查询超时 queryTimeout 即可在 DataSource 配置,也可在 JdbcTemplate 配置。
转自:青石路,
链接:cnblogs.com/youzhibing/p/16458860.html
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)