
盘点python数据工程师需要掌握的18个库
大家好,欢迎来到Crossin的编程教室!
Python的一大优势是具有丰富的第三方库,可以帮你节省大量的开发工作。很多同学学习Python的目的都是为了进行数据分析。今天我们就来整理一下Python中在数据分析领域使用最广泛的一些库。掌握这些库,进行数据分析相关任务时就可以随心所欲了!
目录数据获取
Selenium
Scrapy
Beautiful Soup
数据清洗
Spacy
NumPy
Pandas
数据可视化
Matplotlib
Pyecharts
数据建模
Scikit-learn
PyTorch
TensorFlow
模型检查
Lime
音频数据处理
Librosa
图像数据处理
OpenCV-Python
Scikit-image
数据通信
Pymongo
数据分析结果web部署
Flask
Django
数据获取
Selenium
 Selenium是一个Web测试自动化框架,最初是为软件测试人员创建的。它提供了Web驱动程序API,供浏览器与用户操作交互并返回响应。它运行时会直接实例化出一个浏览器,完全模拟用户的操作,比如点击链接、输入表单,点击按钮提交等。所以我们使用它可以很方便的来登录网站和爬取数据。
Selenium是一个Web测试自动化框架,最初是为软件测试人员创建的。它提供了Web驱动程序API,供浏览器与用户操作交互并返回响应。它运行时会直接实例化出一个浏览器,完全模拟用户的操作,比如点击链接、输入表单,点击按钮提交等。所以我们使用它可以很方便的来登录网站和爬取数据。可以使用
brew install selenium的方式来快速安装selenium。
数据获取
Scrapy
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。其吸引人的地方在于任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。我们可以启用选择器(例如XPath,CSS)从网页中提取数据。
我们需要先安装Twisted,因为直接安装scrapy的话,安装会失败。所以使用pip install Twisted-18.9.0-cp37-cp37m-win32.whl来安装,然后使用pip install scrapy来安装scrapy就可以了
数据获取
Beautiful Soup

可以使用
brew install beautifulsoup4的方式来快速安装bf4。
数据清洗
Spacy
数据清洗
NumPy

NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。对数组执行数学运算和逻辑运算时,NumPy 是非常有用的。在用 Python 对 n 维数组和矩阵进行运算时,NumPy 提供了大量有用特征。
数据清洗
Pandas

pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
数据可视化
Matplotlib

matplotlib是受MATLAB的启发构建的。MATLAB是数据绘图领域广泛使用的语言和工具。MATLAB语言是面向过程的。利用函数的调用,MATLAB中可以轻松的利用一行命令来绘制,然后再用一系列的函数调整结果。它有一套完全仿照MATLAB的函数形式的绘图接口,在matplotlib.pyplot模块中。这套函数接口方便MATLAB用户过度到matplotlib。
数据可视化
Pyecharts
Echarts 是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,当 Python 遇到了 Echarts,就变成了 PyEcharts,目的就是为了与 Python 进行对接,方便在 Python 中直接使用数据生成图。
数据建模
Scikit-learn

scikit-learn包含众多顶级机器学习算法,主要有六大基本功能,分别是分类、回归、聚类、数据降维、模型选择和数据预处理。scikit-learn拥有非常活跃的用户社区,基本上其所有的功能都有非常详尽的文档供用户查阅。可以研读scikit-learn的用户指南及文档,对其算法的使用有更充分的了解。
数据建模
Pytorch

PyTorch是美国互联网巨头Facebook在深度学习框架Torch的基础上使用Python重写的一个全新的深度学习框架,它更像NumPy的替代产物,不仅继承了NumPy的众多优点,还支持GPUs计算,在计算效率上要比NumPy有更明显的优势;不仅如此,PyTorch还有许多高级功能,比如拥有丰富的API,可以快速完成深度神经网络模型的搭建和训练。
数据建模
Tensorflow

TensorFlow是一个采用数据流图(data flow graphs),用于数值计算、机器学习、神经网络的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
模型检查
Lime
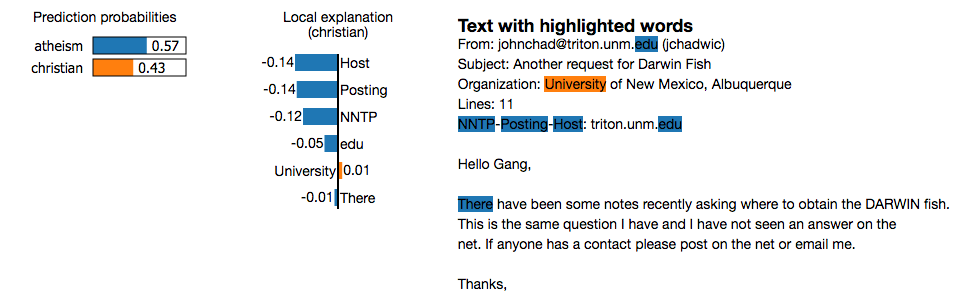
LIME能够解释所有我们可以获得预测概率的模型(在R中,也就是每一个与预测(type=“prob”)一起工作的模型)。它利用了这样一个事实,即线性模型很容易解释,因为它们基于特征和类标签之间的线性关系:将复模型函数用局部拟合线性模型逼近原训练集的排列。
音频数据处理
Librosa

librosa是一个非常强大的python语音信号处理的第三方库,用于音频、音乐分析、处理和些常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大。学会librosa后再也不用用python去实现那些复杂的算法了,只需要一句语句就能轻松实现。
图像数据处理
OpenCV

OpenCV是计算机视觉领域应用最广泛的开源工具包,基于C/C++,支持Linux/Windows/MacOS/Android/iOS,并提供了Python,Matlab和Java等语言的接口,因为其丰富的接口,优秀的性能和商业友好的使用许可,不管是学术界还是业界中都非常受欢迎。
可以在 anaconda 中来安装OpenCV
图像数据处理
Scikit-imag

scikit-image 是一种开源的用于图像处理的 Python 包。它包括分割,几何变换,色彩操作,分析,过滤等算法。它用作集成到python运算环境结合一些科学运算库(Numpy,Scipy)
安装
sudo apt-get install python-skimage源码
git clone https://github.com/scikit-image/scikit-image.git
数据库相关
Pymongo

MongoDB是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活。而要使用python进行操作就需要pymongo。
安装
pip3 install pymongo连接
client = pymongo.MongoClient(host='localhost', port='ip')
数据分析结果可视化部署
Flask

Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。另外,Flask还有很强的定制性,用户可以根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,其强大的插件库可以让用户实现个性化的网站定制,开发出功能强大的网站。
数据分析结果可视化部署
Django

Django是高水准的Python编程语言驱动的一个开源模型.视图,控制器风格的Web应用程序框架,它起源于开源社区。使用这种架构,程序员可以方便、快捷地创建高品质、易维护、数据库驱动的应用程序。另外,在Django框架中,还包含许多功能强大的第三方插件,使得Django具有较强的可扩展性。
安装
pip install Django文档
https://docs.djangoproject.com/en/3.0/
作者:刘早起早起 来源:早起Python
_往期文章推荐_
46个常用Pandas方法速查表