
36张图学HTTP,稳了呀
本文公众号来源:我没有三颗心脏
作者:我没有三颗心脏
本文已收录至我的GitHub
 HTTP文章回顾
HTTP文章回顾
前言
当您网上冲浪时,HTTP 协议无处不在。当您浏览网页、获取一张图片、一段视频时,HTTP 协议就正在发生。
本篇将尽可能用简短的例子和必要的说明来让您了解基础的 HTTP 知识。

目录:
-
什么是 HTTP? -
HTTP 简史; -
HTTP 与 HTTPS;
Part 1. 什么是 HTTP?
互联网是有关 web 客户端和 web 服务器之间的通信。
HTTP(HyperText Transfer Protocol)又叫超文本传输协议。本质上就是一个协定好双方如何进行交流沟通的约定。
这就好比我在一起玩游戏的朋友群里发送一条 「1?」 的消息,朋友们就立即知道是在询问今晚是不是要一起游戏的意思。
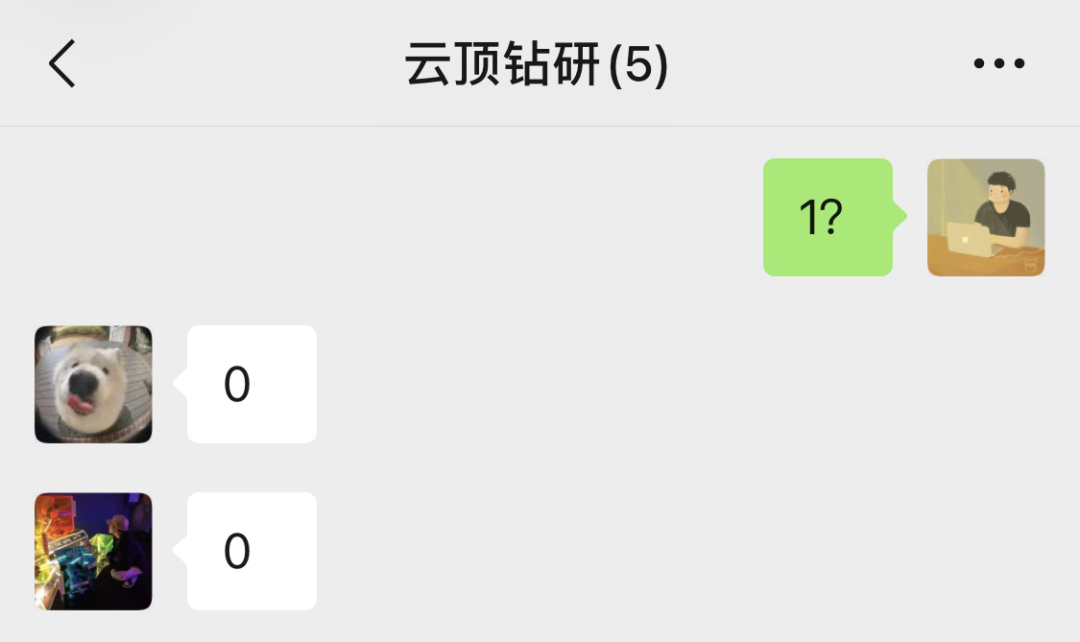
但是如果我给其他人发送 「1?」 就可能出现问题:他们不知道我在说什么。

本质上,这就是 HTTP 协议所代表的含义。我们已经同意,如果我们以特定的方式发送消息,则服务器就会理解消息的意图并作出回应。
Part 2. HTTP 简史
1989 年 3 月,互联网还只属于少数人。在这一互联网的黎明期,HTTP 诞生了。
HTTP / 0.9 - 单行协议
1989年,当时还在欧洲核子研究组织(CERN)工作的蒂姆·伯纳斯·李(Tim Berners-Lee)提出了一种能让远隔两地的研究者们共享知识的设想。

最开始称为 Mesh,后来在 1990 年实施期间将其重命名为 World Wide Web(万维网)。它基于现有的 TCP/IP 协议构建,包括 4 个部分:
-
一种表示超文本文档的文本格式,即超文本标记语言(HTML); -
一种用于交换这些文档的简单协议,即 HyperText 传输协议(HTTP); -
一个客户端可以显示这些文档,第一个 Web 浏览器称为 WorldWideWeb。 -
一个可以访问文档的服务器;
这四部分在 1990 年底完成。虽然此时 Web 页面只能显示单纯的文本内容,浏览器也只能显示呆板的文字信息,不过这已经基本满足了建立 Web 站点的初衷,实现了信息资源共享。
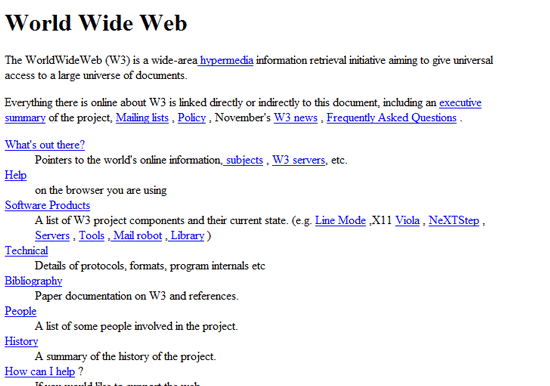
以下就是 HTTP/0.9 的请求内容:
GET /page.html
用唯一可用的 GET 方法向目标服务器获取指定的文档。(一旦连接到服务器,协议、服务器、端口号这些都不是必须的)
响应也极其简单:只包含文档本身。
<HTML>
网页的内容
</HTML>
这意味着 HTTP/0.9 只能够传输 HTML 文件。一旦出现问题,一个特殊的包含问题描述信息的 HTML 文件将被发回,供人们查看。
HTTP/1.0 - 构建可扩展性
由于 HTTP/0.9 协议的应用十分有限,加之 HTTP 使用量和 HTML 的高速发展,浏览器和服务器迅速扩展其内容使其用途更广:
-
协议版本信息会随着每一次请求发送;
----------HTTP/0.9请求----------
GET /page.html
----------HTTP/1.0请求----------
GET /page.html HTTP/1.0 -> 新增协议版本
-
服务器在响应时回复状态码,使浏览器能了解请求执行成功或失败,并相应调整行为(如更新或失败);
----------HTTP/0.9响应----------
<HTML>
....
</HTML>
----------HTTP/1.0响应----------
200 OK -> 新增状态码
<HTML>
....
</HTML>
-
引入了 HTTP 头的概念,无论是请求还是响应,允许传输其他信息,使协议更灵活以及更具扩展性;

-
在 HTTP 头的帮助下,具备了除传输纯文本的 HTML 文件以外,还可以传输其他类型文档的能力(归功于 Content-Type头);

HTTP/0.9 规范大约只有一页,而 HTTP/1.0 在 RFC-1945 中定义的规范则足足有 60 页。这说明 HTTP 已经成长为一个重要的工具。
尽管 HTTP/1.0 从 HTTP/0.9 有了很大的飞跃,但仍然存在许多必须解决的已知缺陷。例如与 TCP 协议交互不良、没有充分考虑缓存等问题。
拿与 TCP 协议交互不良举例。由于 HTTP 是基于 TCP 建立的,所以通讯之前需要建立连接,通讯结束之后需要断开连接。

HTTP/1.0 每一次的通讯都需要建立并断开连接,这无疑增加了无谓的通信开销。
HTTP/1.1 - 标准化的协议
文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,并不是官方标准。所以实际运用起来非常地混乱。所以实际上自 1995 年开始,即 HTTP/1.0 文档发布的下一年,就开始修订 HTTP 的第一个标准化版本。
HTTP/1.1 在 1997 年 1 月以 RFC 2068 文件发布。HTTP/1.1 消除了大量歧义内容并引入了多项改进:
-
连接可以复用,节省了多次打开 TCP 连接加载网页文档资源的时间;

-
增加管线化技术,允许在第一个应答被完全发送之前就发送第二个请求,以降低通信延迟;

-
支持响应分块;
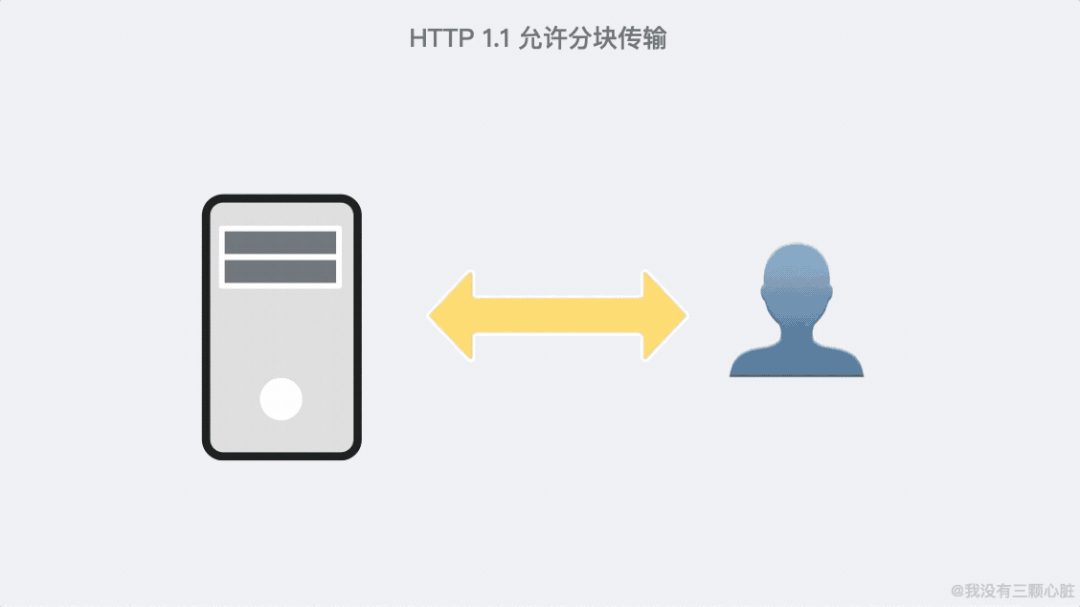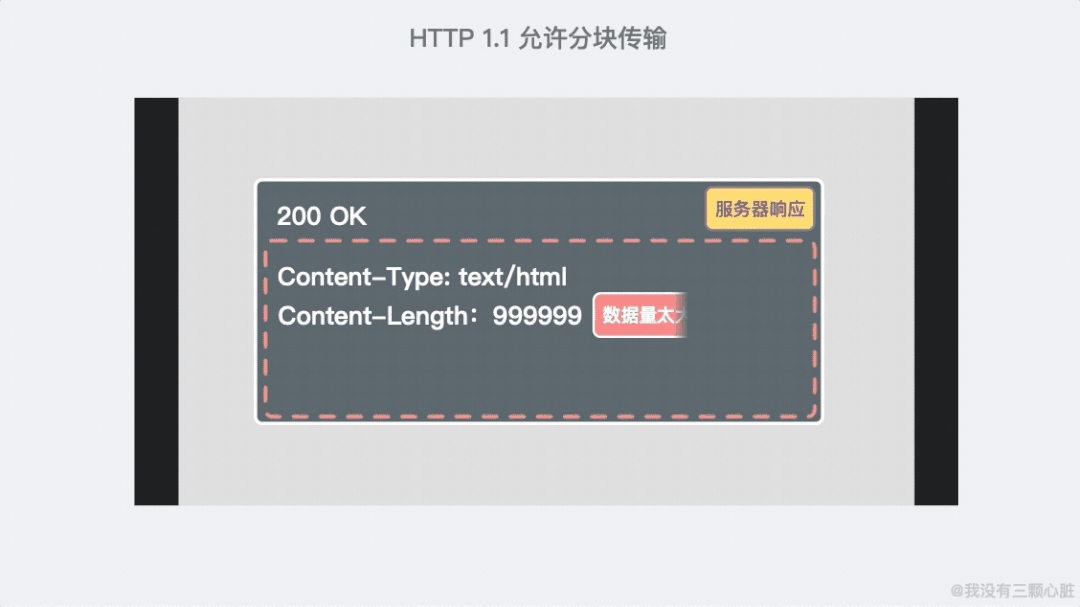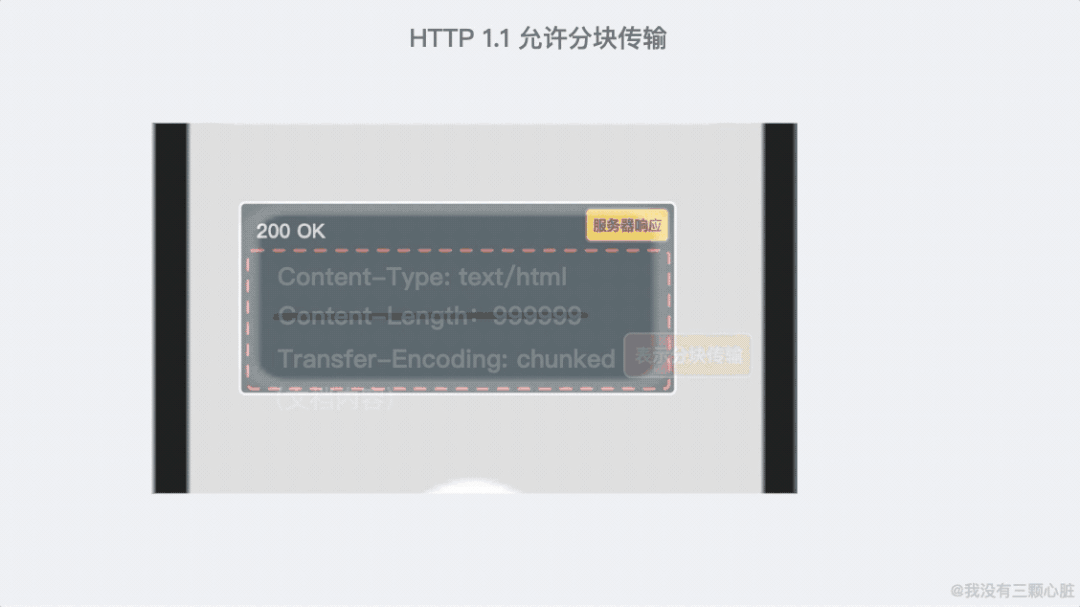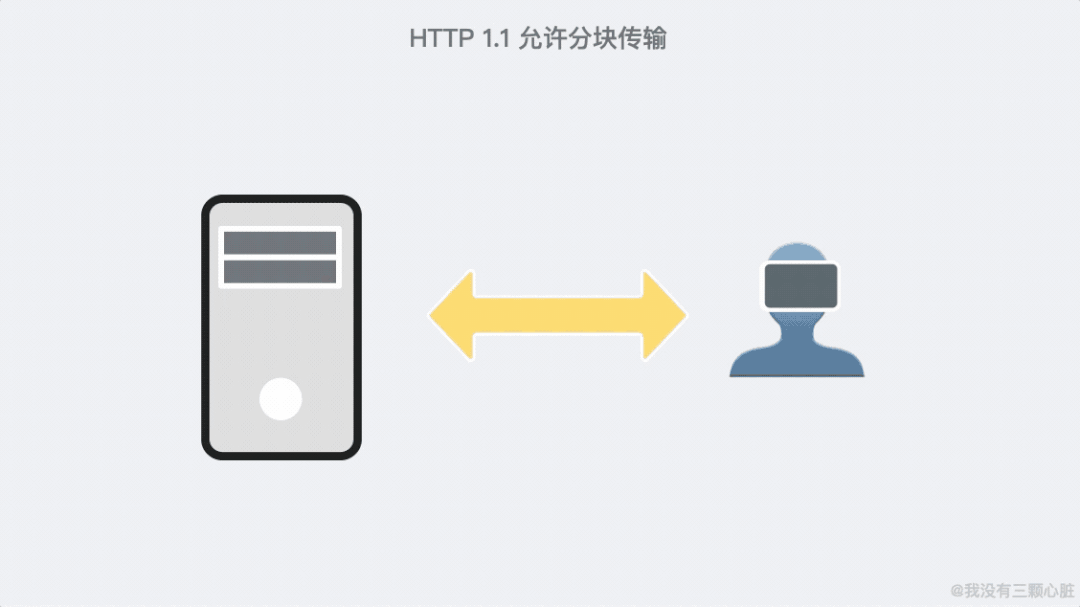
-
引入额外的缓存控制机制,在 HTTP
Cache-Control标头中引入了很多可以选择的选项; -
引入内容协商机制,包括语言,编码,类型等,并允许客户端和服务器之间约定以最合适的内容进行交换;
-
能够使不同域名配置在同一个 IP 地址的服务器上。
一个典型的请求流程, 所有请求都通过一个连接实现,看起来就像这样:

超过 15 年的扩展
由于 HTTP 的可扩展性——创建新的头部和方法是很容易的——HTTP 协议稳定使用了超过 15 年。期间不断对 HTTP/1.1 协议进行修订(RFC 2616、RFC 7230、RFC 7235),为 HTTP/2.0 作了十足的铺垫。
HTTP/2.0 - 为更优异的表现
这些年来,网页愈渐变得复杂,甚至演变成了独有的应用,可见媒体的播放量,增进交互的脚本大小也增加了许多:更多的数据通过 HTTP 请求被传输。
在 2010 年到 2015 年,谷歌通过实践证明了实验性的 SPDY 协议的可行性,这成为了后来 HTTP/2 协议的基础。

HTTP/2 在 HTTP/1.1 有几处基本的不同:
-
HTTP/2 是二进制协议而不是文本协议,不再可读。头信息和数据体都是二进制(体积更小),并且统称为帧(frame)。

-
这是一个复用协议,可以多路复用。并行的请求能在同一个链接中处理,移除了 HTTP/1.x 中顺序和阻塞的约束;

*注:这里 HTTP/2 并不是合并成一个包,而是分成多个 Stream 发送,这里只是为了绘画方便。
大家可以通过点击这里直观感受到 HTTP/2 比 HTTP/1.1 快了多少。
-
压缩了 Headers。因为 Headers 在一系列请求中常常是相似的,其移除了重复和传输重复数据的成本。实现这一功能的算法被称为 HPACK 算法;
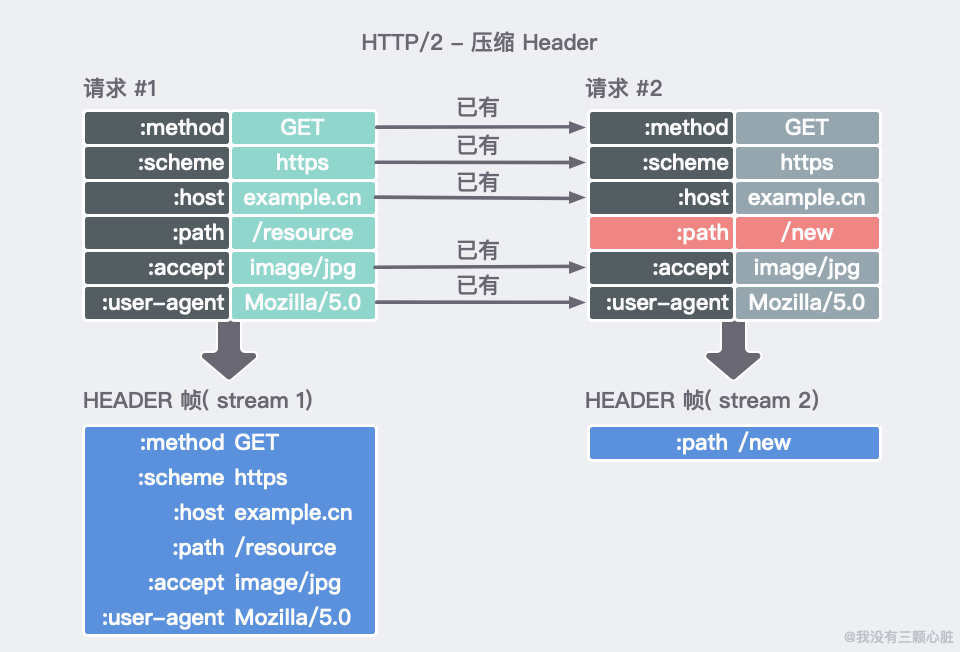
-
其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求;
详细的 HTTP/2 优秀的地方可以参看下 4 链接
在 2015 年 5 月正式标准化后,HTTP/2 取得了极大的成功,在 2016 年 7 月前,8.7% 的站点已经在使用它。高流量的站点最迅速普及,在数据传输上节省了可观的成本和支出。
这种迅速的普及率很可能是因为 HTTP2 不需要站点和应用做出改变:使用 HTTP/1.1 和 HTTP/2 对他们来说是透明的。
拥有一个最新的服务器和新点的浏览器进行交互就足够了。只有一小部分群体需要做出改变,而且随着陈旧的浏览器和服务器的更新,而不需 Web 开发者做什么,用的人自然就增加了。
后 HTTP/2 进化
随着 HTTP/2 的发布,就像先前的 HTTP/1.x 一样,HTTP 没有停止进化。HTTP 的扩展性依然被用来添加新的功能。
HTTP 的进化证实了它良好的扩展性和简易性,释放了很多应用程序的创造力并且情愿使用这个协议。
HTTP/3 - 更好的未来
HTTP/3 是即将到来的第三个主要版本的 HTTP 协议。与前任协议不同,在 HTTP/3 中,将弃用 TCP 协议,改为使用 UDP 协议和 QUIC 协议实现。

此变化主要为了解决 HTTP/2 中存在的队头阻塞问题。由于 HTTP/2 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。
截至 2021 年 1 月,HTTP/3 仍然是草案状态。
小结
-
HTTP/0.9 只能传输单一的 HTML 纯文本,不够灵活; -
HTTP/1.x 有连接无法复用、队头阻塞、协议开销大和安全因素等多个缺陷; -
HTTP/2 通过多路复用、二进制流、Header 压缩等等技术,极大地提高了性能,但是还是存在着问题的; -
QUIC 基于 UDP 实现,是 HTTP/3 中的底层支撑协议,该协议基于 UDP,又取了 TCP 中的精华,实现了即快又可靠的协议;
Part 3. HTTP 与 HTTPS

为什么需要 HTTPS
HTTP 协议在设计之初就没有充分考虑安全性的问题。所以基于 HTTP 的这些应用都承担着如下的几个风险:
-
使用明文(不加密)进行通信,内容可能会被窃听; -
不验证通信方的身份,通信方的身份有可能是伪装的; -
无法验证信息的完整性,也就是说信息可能是被篡改过的;
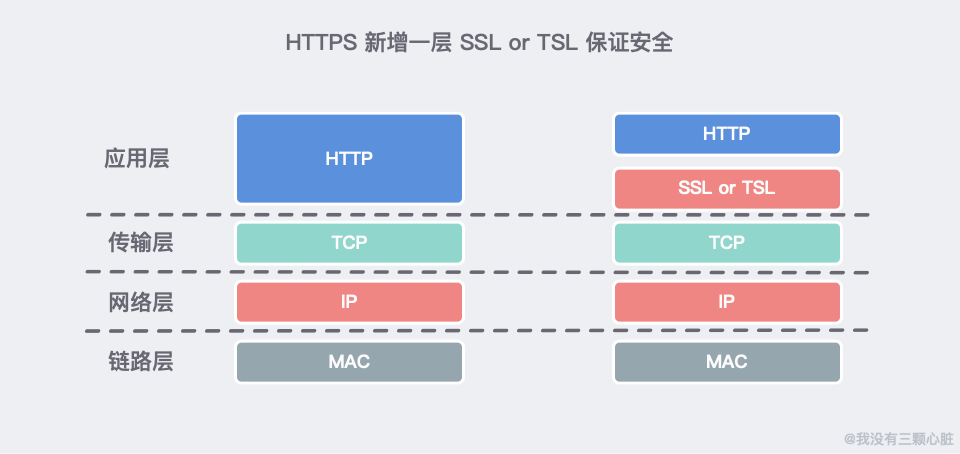
HTTPS(HTTP over SSL)采取嵌套新一层安全套接字层(Secure Socket Layer,SSL)来解决网络传输的安全性问题。
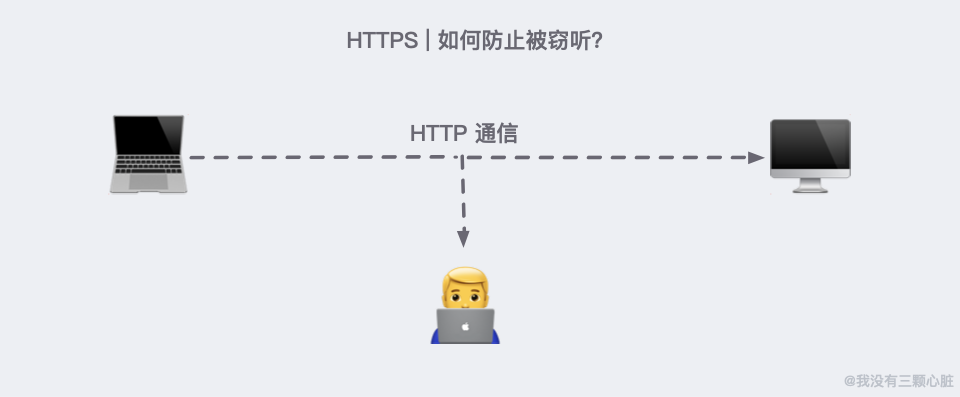
如何防止被窃听?
加密是很容易联想到的解决方法。但如何保证传输加密方法的过程不被窃听呢?
这时候非对称加密的出现解决了这一大难题。它把密码革命性地分成公钥和私钥,由于两个秘钥并不相同,所以称为非对称加密。
举个例子,假设我们现在需要加密的字符是 520,我们加密的方法是把这个数乘以 91,并把结果的最后三位公布出来:
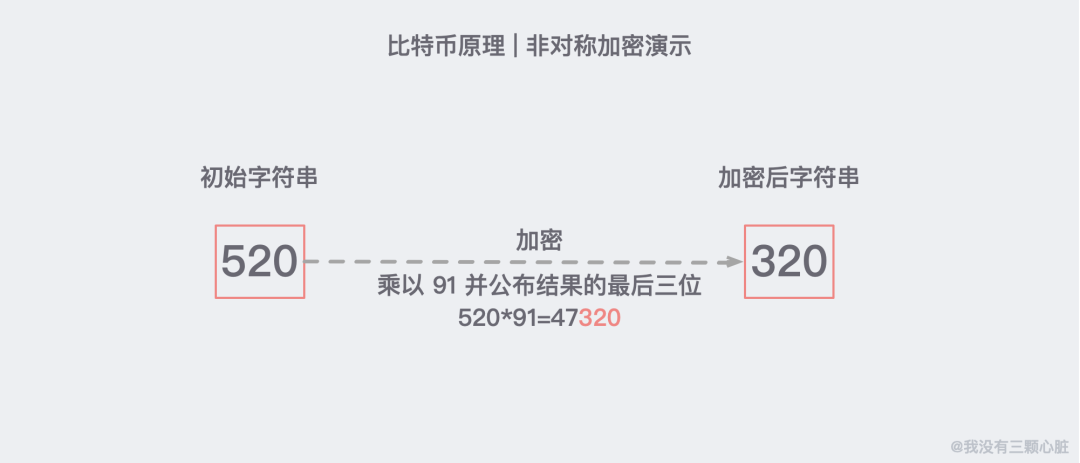
注:这里的 91 相当于公钥,任何人都可以知道。
解密我们当然不能通过除以 91 来完成,而是通过 x11,取出结果后三位来还原:
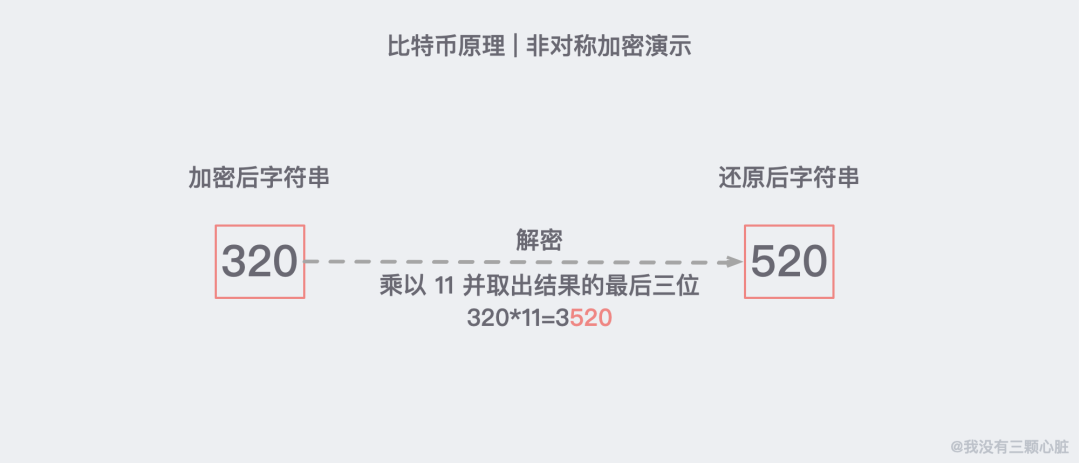
注:这里的 x11 相当于私钥,只有解密方才知道。
这是因为 91*11=1001,任何一个三位数乘以 1001 显然后三位是不会变的。这大概就是非对称加密的原理了,基于这个原理我们通信的双方就可以各自生成自己的公钥私钥并进行相对安全的通信了。
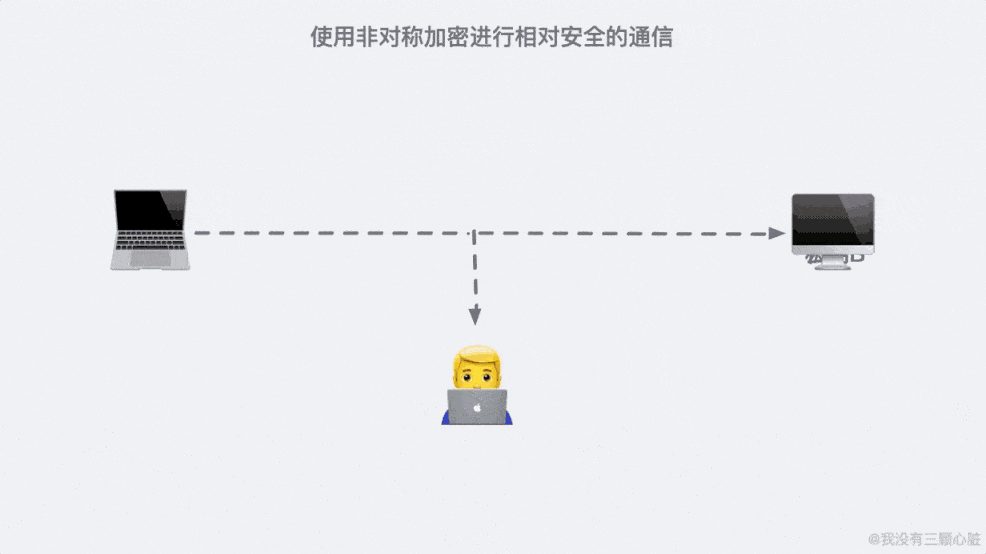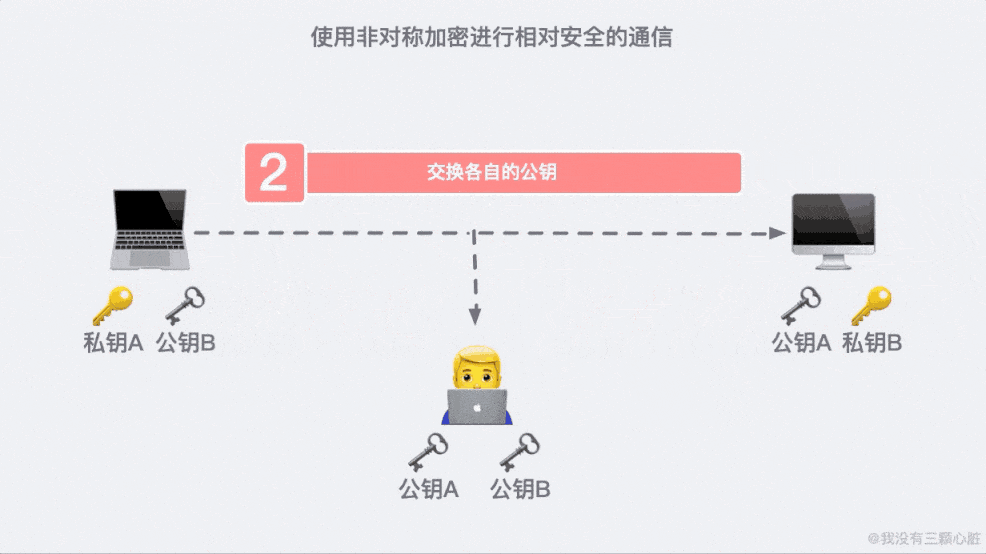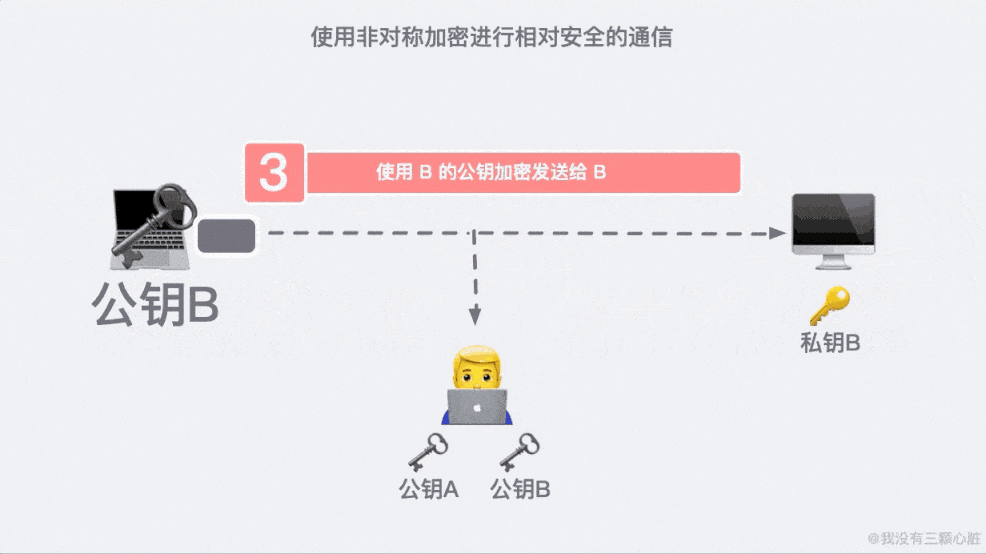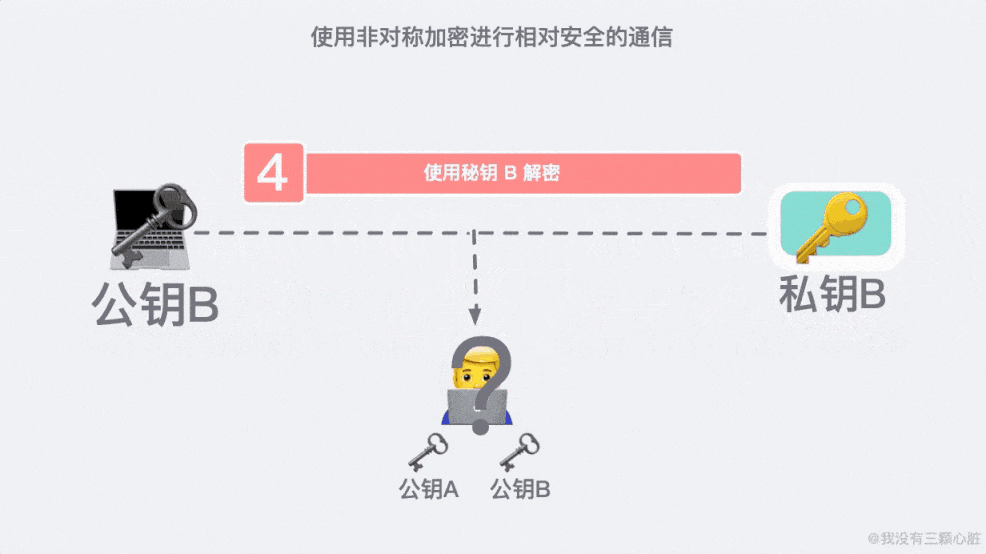
如何验证对方身份?
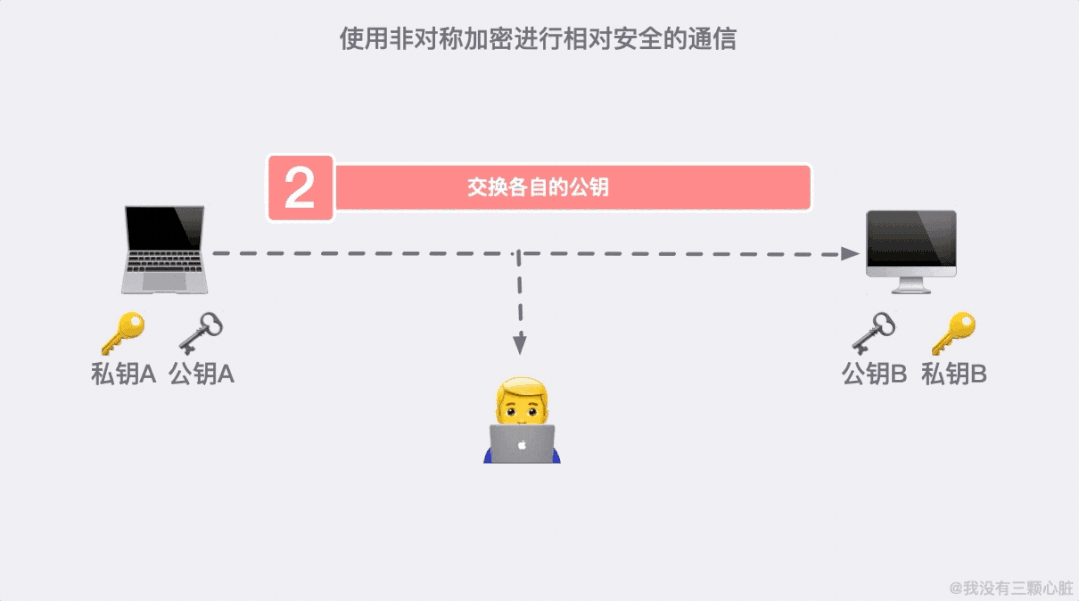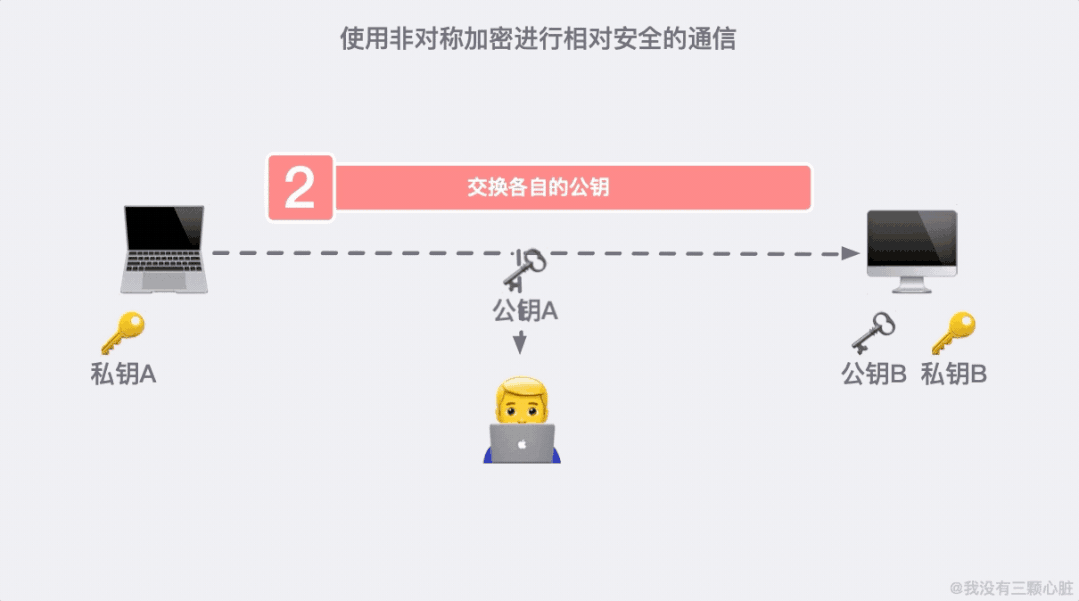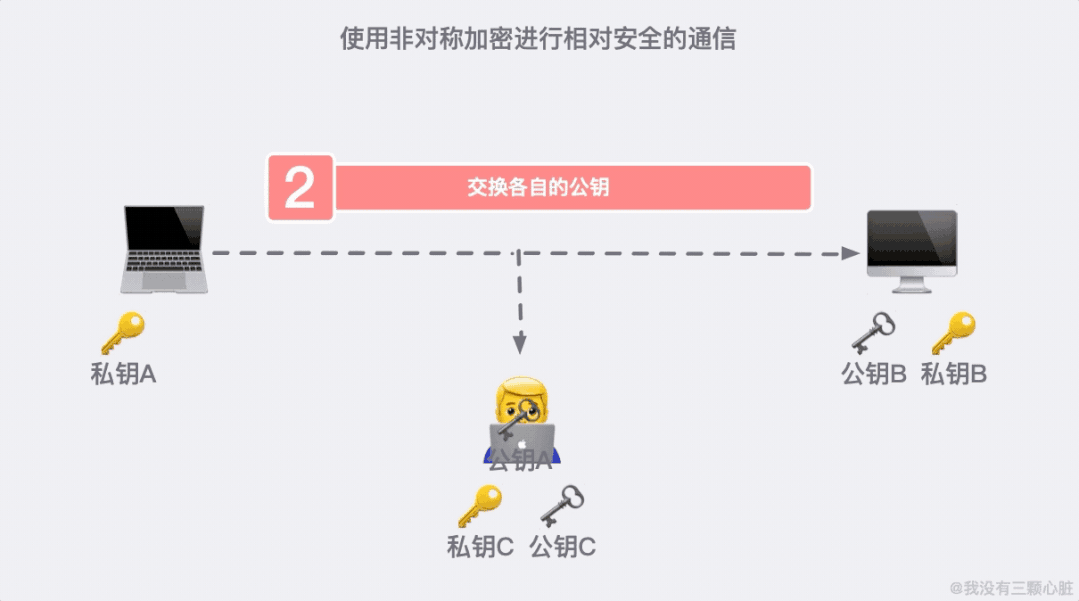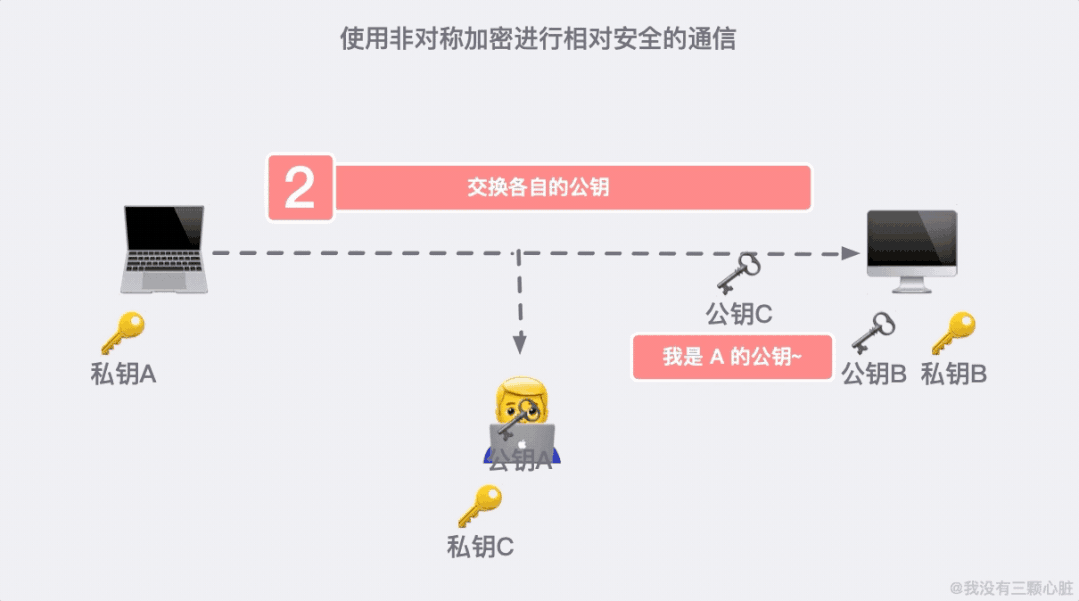
上面的过程看似无懈可击,但在 TCP/IP 的端到端的通信里,路途遥远,夜长梦多。
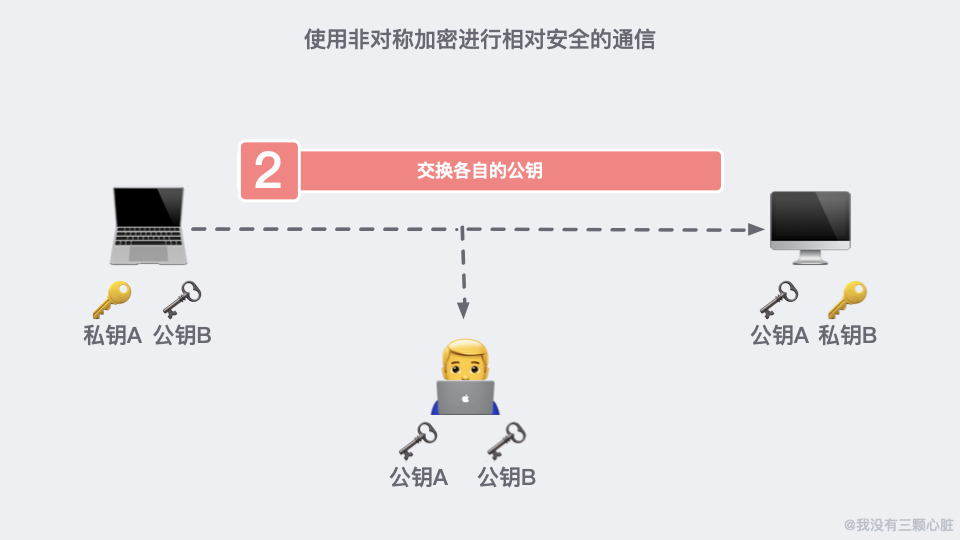
如果在第二步的时候,信息被黑客截取,在严刑拷打之下知道了这是传输公钥的信息。那么完全可以自己生成一对密钥和公钥,冒充是彼此来传输自己的秘钥。
加密危机之后,又产生了信任危机。我们需要一个有公信力的组织来证明身份,这个问题就得到了解决。
这个可信的组织就是颁发 HTTPS 证书的组织 CA(Certificate Authority)。每次有客户端或者服务端想要公开自己的公钥时,都需要向 CA 做出申请,通过后 CA 会颁发一个与公开公钥绑定的数字证书。(了解更多证书)

进行 HTTPS 通信时,服务器会把证书发送给客户端,客户端取得其中的公开密钥之后,先进行验证,如果验证通过,就可以开始通信。

如何防止被篡改?
在之前介绍比特币原理的时候,我们提到过一种哈希算法。它的作用是能把任意长度的输入编程固定长度的二进制输出。

注:为了简化右边为 16 进制数
在 HTTPS 中,有一种新的摘要算法,可以简单理解为是对于内容的一种压缩。所以但凡内容变化一丁点,哪怕是一个标点符号,压缩之后的数字哈希也不对。
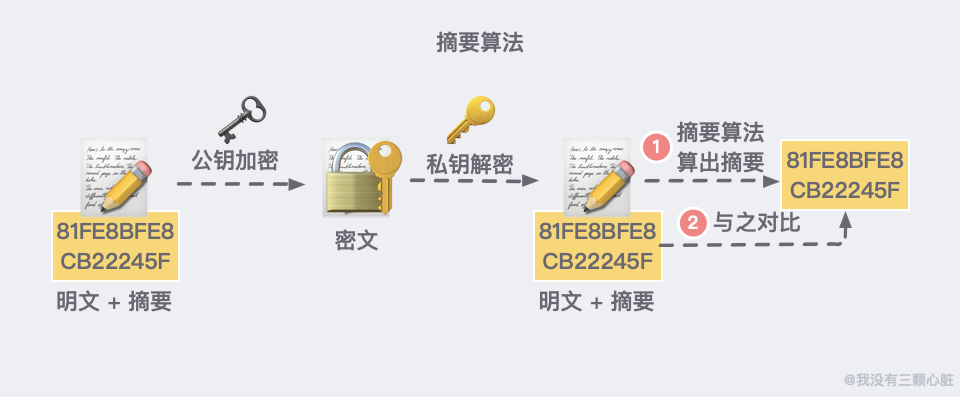
客户端在发送明文之前会通过摘要算法算出明文的 「指纹」,发送的时候把 「指纹 + 明文」 一同加密成密文后,发送给服务器。
服务器解密后,用相同的摘要算法算出发送过来的明文,通过比较客户端携带的 「指纹」 和当前算出的 「指纹」 做比较,若 「指纹」 相同,说明数据是完整的。
HTTP 与 HTTPS 有什么不同?
尽管听上去 HTTPS 就是更安全的 HTTP,但也有许多细节方面的不同:
-
HTTP 明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输; -
HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输; -
HTTP 的端口号是 80,HTTPS 的端口号是 443; -
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的;
后记
HTTP 协议是纷繁复杂的网络世界的基础,它保证了各个应用之间的"交流无阻碍"。本篇也尽可能使用动图的形式清晰地表达,希望大家能用餐愉快。

至此,我们对 HTTP 协议已经有了相当的了解了。后续也会继续跟大家一起学习计算机网络的基础知识,也会尝试着跟着后端学习路线图的脚步跟着大家一起学习进阶。

好消息,好消息!《对线面试官》系列目前已经连载17篇啦!欢迎持续关注
-
【对线面试官】Java注解 -
【对线面试官】Java泛型 -
【对线面试官】 Java NIO -
【对线面试官】Java反射 && 动态代理 -
【对线面试官】多线程基础 -
【对线面试官】 CAS -
【对线面试官】synchronized -
【对线面试官】AQS&&ReentrantLock -
【对线面试官】线程池 -
【对线面试官】ThreadLocal -
【对线面试官】List -
【对线面试官】Map -
【对线面试官】SpringMVC -
【对线面试官】Spring基础 -
【对线面试官】SpringBean生命周期 -
【对线面试官】Redis基础
点击小卡片关注【面试造火箭】
关注后回复「888」还可获取【面试资料】网盘地址哟!