
NewSQL 数据库分库分表全链路实践
最近与同行科技交流,经常被问到分库分表与分布式数据库如何选择,网上也有很多关于中间件+传统关系数据库(分库分表)与NewSQL分布式数据库的文章,但有些观点与判断是我觉得是偏激的,脱离环境去评价方案好坏其实有失公允。
本文通过对两种模式关键特性实现原理对比,希望可以尽可能客观、中立的阐明各自真实的优缺点以及适用场景。
- NewSQL 数据库为什么更好用? -

首先关于“中间件+关系数据库分库分表”算不算NewSQL分布式数据库问题,国外有篇论文是pavlo-newsql-sigmodrec。
如果根据该文中的分类,Spanner、TiDB、OB算是第一种新架构型,Sharding-Sphere、Mycat、DRDS等中间件方案算是第二种(文中还有第三种云数据库,本文暂不详细介绍)。
基于中间件(包括SDK和Proxy两种形式)+传统关系数据库(分库分表)模式是不是分布式架构?
我觉得是的,因为存储确实也分布式了,也能实现横向扩展。但是不是"伪"分布式数据库?从架构先进性来看,这么说也有一定道理。
"伪"主要体现在中间件层与底层DB重复的SQL解析与执行计划生成、存储引擎基于B+Tree等,这在分布式数据库架构中实际上冗余低效的。为了避免引起真伪分布式数据库的口水战,本文中NewSQL数据库特指这种新架构NewSQL数据库。
NewSQL数据库相比中间件+分库分表的先进在哪儿?画一个简单的架构对比图:
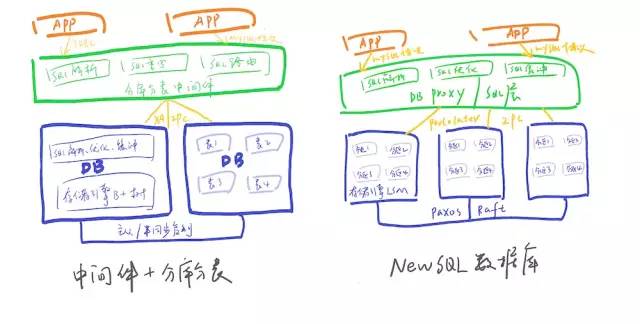
传统数据库面向磁盘设计,基于内存的存储管理及并发控制,不如NewSQL数据库那般高效利用。 中间件模式SQL解析、执行计划优化等在中间件与数据库中重复工作,效率相比较低; NewSQL数据库的分布式事务相比于XA进行了优化,性能更高; 新架构NewSQL数据库存储设计即为基于paxos(或Raft)协议的多副本,相比于传统数据库主从模式(半同步转异步后也存在丢数问题),在实现了真正的高可用、高可靠(RTO<30s,RPO=0) NewSQL数据库天生支持数据分片,数据的迁移、扩容都是自动化的,大大减轻了DBA的工作,同时对应用透明,无需在SQL指定分库分表键。
首先要说的就是分布式事务:这是一把双刃剑。
- CAP 限制 -
推荐一篇关于分布式系统有趣的文章,站在巨人的分布式肩膀上,其中提到:分布式系统中,您可以知道工作在哪里,或者您可以知道工作何时完成,但您无法同时了解两者;两阶段协议本质上是反可用性协议。
- 完备性 -
两阶段提交协议是否严格支持ACID,各种异常场景是不是都可以覆盖?
- 性能 -
传统关系数据库也支持分布式事务XA,但为何很少有高并发场景下用呢?
因为XA的基础两阶段提交协议存在网络开销大,阻塞时间长、死锁等问题,这也导致了其实际上很少大规模用在基于传统关系数据库的OLTP系统中。
SI是乐观锁,在热点数据场景,可能会大量的提交失败。另外SI的隔离级别与RR并无完全相同,它不会有幻想读,但会有写倾斜。
解决分布式事务是否只能用两阶段提交协议? oceanbase1.0中通过updateserver避免分布式事务的思路很有启发性 ,不过2.0版后也变成了2PC。
业界分布式事务也并非只有两阶段提交这一解,也有其它方案its-time-to-move-on-from-two-phase(如果打不开,国内有翻译版https://www.jdon.com/51588)
- HA 与异地多活 -
主从模式并不是最优的方式,就算是半同步复制,在极端情况下(半同步转异步)也存在丢数问题
目前业界公认更好的方案是基于paxos分布式一致性协议或者其它类paxos如raft方式,Google Spanner、TiDB、cockcoachDB、OB都采用了这种方式,基于Paxos协议的多副本存储,遵循过半写原则,支持自动选主,解决了数据的高可靠,缩短了failover时间,提高了可用性,特别是减少了运维的工作量,这种方案技术上已经很成熟,也是NewSQL数据库底层的标配。
分布式一致性算法本身并不难,但具体在工程实践时,需要考虑很多异常并做很多优化,实现一个生产级可靠成熟的一致性协议并不容易。例如实际使用时必须转化实现为multi-paxos或multi-raft,需要通过batch、异步等方式减少网络、磁盘IO等开销。
- Scale 横向扩展与分片机制 -
paxos算法解决了高可用、高可靠问题,并没有解决Scale横向扩展的问题,所以分片是必须支持的。NewSQL数据库都是天生内置分片机制的,而且会根据每个分片的数据负载(磁盘使用率、写入速度等)自动识别热点,然后进行分片的分裂、数据迁移、合并,这些过程应用是无感知的,这省去了DBA的很多运维工作量。以TiDB为例,它将数据切成region,如果region到64M时,数据自动进行迁移。
分库分表模式也能做到在线扩容,基本思路是通过异步复制先追加数据,然后设置只读完成路由切换,最后放开写操作,当然这些需要中间件与数据库端配合一起才能完成。
- 分布式 SQL 支持 -
常见的单分片SQL,这两者都能很好支持。NewSQL数据库由于定位与目标是一个通用的数据库,所以支持的SQL会更完整,包括跨分片的join、聚合等复杂SQL。中间件模式多面向应用需求设计,不过大部分也支持带拆分键SQL、库表遍历、单库join、聚合、排序、分页等。但对跨库的join以及聚合支持就不够了。
NewSQL数据库往往选择兼容MySQL或者PostgreSQL协议,所以SQL支持仅局限于这两种,中间件例如驱动模式往往只需做简单的SQL解析、计算路由、SQL重写,所以可以支持更多种类的数据库SQL。
这里也可以看出中间件+分库分表模式的架构风格体现出的是一种妥协、平衡,它是一个面向应用型的设计;而NewSQL数据库则要求更高、“大包大揽”,它是一个通用底层技术软件,因此后者的复杂度、技术门槛也高很多。
- 存储引擎 -
传统关系数据库的存储引擎设计都是面向磁盘的,大多都基于B+树。B+树通过降低树的高度减少随机读、进而减少磁盘寻道次数,提高读的性能,但大量的随机写会导致树的分裂,从而带来随机写,导致写性能下降。
NewSQL的底层存储引擎则多采用LSM,相比B+树LSM将对磁盘的随机写变成顺序写,大大提高了写的性能。
不过LSM的的读由于需要合并数据性能比B+树差,一般来说LSM更适合应在写大于读的场景。当然这只是单纯数据结构角度的对比,在数据库实际实现时还会通过SSD、缓冲、bloom filter等方式优化读写性能,所以读性能基本不会下降太多。
NewSQL数据由于多副本、分布式事务等开销,相比单机关系数据库SQL的响应时间并不占优,但由于集群的弹性扩展,整体QPS提升还是很明显的,这也是NewSQL数据库厂商说分布式数据库更看重的是吞吐,而不是单笔SQL响应时间的原因。
- 成熟度与生态 -
分布式数据库是个新型通用底层软件,准确的衡量与评价需要一个多维度的测试模型,需包括发展现状、使用情况、社区生态、监控运维、周边配套工具、功能满足度、DBA人才、SQL兼容性、性能测试、高可用测试、在线扩容、分布式事务、隔离级别、在线DDL等等。
虽然NewSQL数据库发展经过了一定时间检验,但多集中在互联网以及传统企业非核心交易系统中,目前还处于快速迭代、规模使用不断优化完善的阶段。
对于互联网公司,数据量的增长压力以及追求新技术的基因会更倾向于尝试NewSQL数据库,不用再考虑库表拆分、应用改造、扩容、事务一致性等问题怎么看都是非常吸引人的方案。
对于传统企业例如银行这种风险意识较高的行业来说,NewSQL数据库则可能在未来一段时间内仍处于探索、审慎试点的阶段。
- 总结 -
如果看完以上内容,您还不知道选哪种模式,那么结合以下几个问题,先思考下NewSQL数据库解决的点对于自身是不是真正的痛点:
强一致事务是否必须在数据库层解决? 数据的增长速度是否不可预估的? 扩容的频率是否已超出了自身运维能力? 相比响应时间更看重吞吐? 是否必须做到对应用完全透明? 是否有熟悉NewSQL数据库的DBA团队?
如果你还未做出抉择,不妨再想想下面几个问题:
最终一致性是否可以满足实际场景? 数据未来几年的总量是否可以预估? 扩容、DDL等操作是否有系统维护窗口? 对响应时间是否比吞吐更敏感? 是否需要兼容已有的关系数据库系统? 是否已有传统数据库DBA人才的积累? 是否可容忍分库分表对应用的侵入?
作者:蚊子squirrel
来源:https://www.jianshu.com/p/9131edd8fd2c
