
先进计算发展研究报告
共 4423字,需浏览 9分钟
·
2021-11-04 08:42


超算改变计算系统架构,E级超算时代,HPC会带来多少可能?AI已经走进各行各业,详情参阅麦肯锡报告。
计算设备和计算系统在外观形态、部署方式、应用特性等方面虽发生了翻天覆地的变化,但体系结构依然遵从冯诺依曼架构,计算设备的主要组成部件以及彼此之间的交互机制也相对稳定。与数据处理相关的运算器和控制器、与数据存储相关的各类存储模块、以及数据在上述两大单元间实现交互的通信类接口和模块是构成计算设备和计算系统的主要功能模块,也是构成计算技术体系的三大重点单元。
下载链接:先进计算发展研究报告
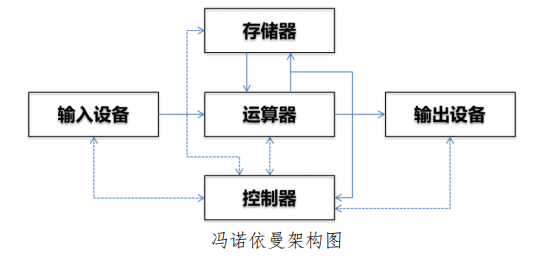
CPU、GPU、FPGA 是目前通用计算领域的三大主流计算芯片。CPU芯片兼顾控制和计算,是构成笔记本、智能终端及服务器计算硬件主体。
三大计算芯片技术创新依然活跃。一方面持续挖掘传统架构技术潜力。CPU 不断优化现有架构技术能力,采用乱序执行、超标量流水线、多级缓存等技术提升整体性能表现;GPU 持续探索高效的图形处理单元、流处理单元和访存存取体系等,并优化编程框架降低 GPU 编程和应用程序移植难度;FPGA 不断强化应用功能的丰富完善,升级芯片内部组件以适应广泛的加速场景,并发展基于 C/C++、OpenCL 等软件工具开发生态,降低开发者门槛。另一方面均通过引入专用计算能力迎合人工智能等新兴领域的计算需求。
AI ASIC 现已成为专用计算加速芯片创新的典型代表。专用集成电路(ASIC)意指针对特定领域、特定算法需求设计的电路,与通用芯片相比面积小、性能高、功耗低,大规模量产后具备成本优势,可广泛应用在市场需求量大的专用领域。目前为满足人工智能应用计算需求的 AI ASIC 是创新的焦点所在,升级重点围绕指令集、计算架构、访存体系、交互通信等四大方面。
指令集方面,主要针对深度学习算法中高频、高耗时的矩阵、向量等逻辑运算进行优化,并简化与算法无关的分支跳转、缓存控制等逻辑控制指令。
计算架构方面,多选择众核等高并行架构进行设计,并集成矩阵乘加等专用运算单元增强针对深度学习算法共性计算需求的支撑能力。如谷歌将张量处理单元(TPU)引入脉动阵列架构,实现数据高效复用功能,提升并行处理能力;集成超过6 万个计算核心单元组成专用矩阵乘加模块,提升深度学习算法计算效率。
存储方面,应用高带宽内存等新型技术提升内存带宽,结合片上内存、数据复用、模型压缩等手段降低内存存取频次。如寒武纪公 司早期学术论文中即提出可采用大量的片上存储设计来降低片外存储访问需求和数据访问功耗,这一设计方案目前也被谷歌等众多企业广泛采用。
互联方面,配置新型 PCIe 5、CCIX 等高速易扩展的异构互联总线,通过带宽加速缓解海量数据频繁读取所导致的高延时问题。
结合场景需求和算法特征定向优化,AI ASIC 芯片差异化创新加 速。由于人工智能的不同应用场景间差异性较大,难以通过一款通用人工智能芯片适合所有领域,随着各应用场景定位和需求的逐步明确,AI ASIC 呈现多技术路线分化态势。深度学习计算主要分为训练和推理两个阶段。
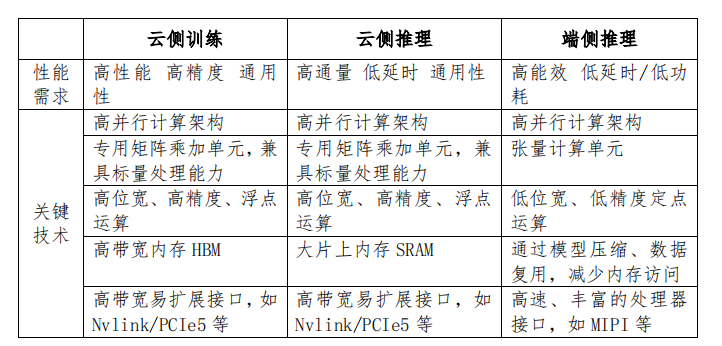
其中,深度学习模型训练以高性能、高精度、通用化的计算能力为主,芯片需堆叠大量高精度浮点运算单元、高带宽内存和专用计算单元等提升训练效率,但受限于高能耗目前多集中在云端部署实施。推理阶段则因应用场景的不同而各具差异,云端推理芯片多应用低位宽定点运算单元、片上内存等实现高通量、低延时、通用化的推理能力;端侧推理芯片则需要深度耦合特定场景和神经网络算法,利用低位宽低精度运算、模型压缩等技术实现低时延或低功耗等差异化场景需求。
数据存储技术发展迅速,现有体系不断演进。自“存储程序”的计算机体系确立起来,存储单元始终与数据处理单元同步升级。
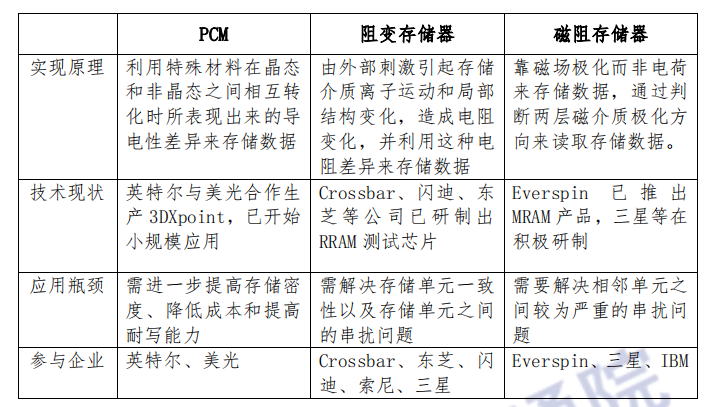
半导体存储器根据是否需要供电实现数据保存可分为易失性存储器和非易失性存储器,其中,易失性存储器以 DRAM 内存为代表,广泛应用于移动设备和服务器设备中,并通过架构创新、TSV 先进封装等不断提升存储密度、降低延时;
非易失性存储器以 NAND 闪存为代表,以其为介质的固态硬盘正替代传统机械硬盘,成为数据中心的主流存储器件,现阶段围绕 3D 集成、层数堆叠等方向升级存储容量。
此外,相变存储器、磁阻式存储器、阻变式存储器、磁畴壁存储器等新型非易失性存储器,因兼具密度高、功耗低、读写快、反复操作耐受力强等优势,备受业界关注。
非易失性内存等新型存储技术创新活跃,或将变革现有存储层次结构。现有计算设备和系统中数据存储单元是由片上缓存、片外内存、固态硬盘等构成的多级存储架构,通过多级存储弥补处理器和存储器间巨大的速度差异,但一旦需跨多级读取数据就会带来大量的数据传输层数和 I/O 调度的额外开销。
高带宽和直接内存访问是目前缓解冯诺依曼瓶颈、提升计算效率的重要创新方向。除了提升总线和以太网交换速度等传统升级手段外,板卡级和系统级数据交换分别以内存共享、远程直接内存访问(RDMA)等为方向提升内存存取性能。
板卡级层面,通过引入统一的虚拟内存(UVA)和 NVLink 高速总线技术,可实现“CPU+GPU”异构并行计算中跨节点内存操作,以缓解 GPU 因单节点本地内存不足而降低并行效率的问题:一方面 UVA 允许多个 GPU 节点之间合并共享彼此的显存空间,并允许 GPU 直接访问并利用系统内存,另一方面从 PCIe 总线升级到 NVLink 总线,提升内存空间数据传输速度,可实现数据交换总体效率提升接近 10 倍。
系统级层面,传统的 TCP/IP 网络通信是通过内核发送消息,并经过一系列多层网络协议的数据包处理工作,由此会带来高额的 I/O 处理开销,限制了跨服务器间传输的带宽及灵活性。RDMA 技术在无需操作系统介入情况下,实现数据从系统内存直接传输到远程系统存储器,消除了外部存储器复制和上下文切换的开销,实现了高吞吐、低延时的网络数据通信,目前 InfiniBand、iWARP、 RoCE 等常见高速互联传输技术均支持 RDMA 技术。
CPU+GPU、CPU+MIC、CPU+FPGA 是目前三大主流的异构计算技术。端侧异构已较为普及,云侧成为下阶段发展的重点。数据中心异构体系开启由 GPU 到 FPGA 的新变革。
异构计算硬件先行,软件作用日趋凸显。随着大数据时代的到来,异构计算已成为突破计算能力和功耗瓶颈的有效途径之一。异构计算共历经四大发展阶段,分别是单纯挖掘并行潜力、添加专用加速单元、针对特定应用领域定制、多种平台的高效融合。
目前异构计算的发展重心已经从硬件开发转移到深化应用、软硬件融合创新阶段,软件对异构计算的支撑作用越来越明显。计算系统会应用到多种硬件体系结构,例如搜索、解析等有大量控制代码的程序主要运行在 CPU上;
大量数据处理的程序适合运行在 GPU、DSP 等矢量体系结构处理芯片上;大量专用计算的应用适合在 FPGA、ASIC 等针对应用进行优化的芯片上执行。为了提高程序执行性能,需要 OpenCL 等标准化的异构编程框架,来完成跨平台的并行编程任务,从而实现对底层多种硬件平台的高效利用。
目前全球 TOP500 HPC 中 有 100 家使用 GPU 加速,96%采用了英伟达的 Tesla 系列 GPU 产品;百度、谷歌、Facebook 等超大规模云计算中也部署了 GPU 密集计算能力。利用 FPGA、ASIC 等提升云端异构计算能力仍在不断深化,如英特尔已提供整合 Altera 的异构平台方案,赛灵思也与 IBM 合作加速布局,预计 2020 年 1/3 的云服务商将采用 FPGA;谷歌 TPU 开放 1000个云 TPU 服务集群,每个云 TPU 最高可达 180TFLOP/s 浮点计算,配 备 64GB 带宽内存。
分布式计算是一种共享软硬件资源的计算形式。分布式计算正由中心能力集聚向边缘融合扩充发展。内存内计算是目前最主流的内存计算方式。SAP HANA 和 Apache Spark 分别是当前较主流的商业和开源内存内计算技术。
多数云数据中心是集中化的,离终端设备和用户比较远,对于实时性要求高的计算服务通常会引起长距离往返延时、网络拥塞、服务质量下降等问题。而边缘计算是将数据在边缘网络进行本地化处理,包括终端设备、边缘设备、边缘服务器等,强调计算的去中心化/去本地化部署,计算服务需求响应更快。
Hadoop、Spark 和 Storm 是目前最重要的三大分布式计算系统。三者作为目前较为主流的分布式计算框架,有各自的适用场景,其中Hadoop 通过将数据切片分别计算来处理大量的离线数据,常用于海量数据的离线分析处理;
Spark 是一个基于内存计算的开源集群计算系统,运算速度超过 Hadoop100 倍,但不能用于处理需长期保存数据,常用于对离线数据的快速分析;
Storm 侧重流式计算,不进行数据收集和存储,通过网络实时接收和处理数据,实时传回结果,可实现对大数据流的实时处理,常用于在线实时的大数据处理。
下载链接:
1-曾庆存-中国科学院地球系统(动力学)模式CAS-ESM.pdf
2-邬江兴_打造AI时代集成电路标志性的芯物种20200928.pdf
3-新形势下高性能计算发展面临的挑战和任务-钱德沛.pdf
4-高性能计算机的存储优化:实践与经验-卢凯.pdf
5-陈健-中国超算应用行业分析和技术服务模式.pdf
6-付昊桓-太湖之光-应用软件研发.pdf"
1、基于LNet的多网络互联实践.pdf
2、面向非易失性存储器的Lustre客户端持久性缓存.pdf
3、面向云计算的高性能重复数据删除技术.pdf
4、神威太湖之光上的动态IO转发资源调度方法.pdf
5、曙光高性能计算并行存储系统技术及应用探究.pdf
6、新挑战下Lustre文件系统的功能演进和结构嬗变.pdf
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
