
真·异地多活架构怎么实现?使用PolarDB-X!
点击下方“IT牧场”,选择“设为星标”

来源:https://zhuanlan.zhihu.com/p/364240552
异地多活是近几年比较热门的一种系统架构。一般来讲,要做到异地多活,是一个系统性的事情,需要接入层、应用层、数据层都做一些事情。
同时有一些场合我们可能会把两地三中心等容灾架构也算作了异地多活(单纯的应用层多活),本文所讲的异地多活,是指所有数据中心的数据库都会承担写流量的"真·异地多活"。
今天我们这篇文章重点来说一下,对于一个分布式数据库,在异地多活架构中,起到了一个什么样的角色;对于其中的问题,解法是什么。
淘宝的异地多活
从国内互联网上能找到的资料来看,淘宝网是提出异地多活这个概念比较早的公司,所以我们先简单了解下淘宝的异地多活。
诞生
先看动机,淘宝做异地多活的架构的动机是比较明确的:
杭州机房容量开始不足 13年杭州出现过限电,让人开始担心杭州机房整体无法服务的情况
从容量与容灾两个角度考虑,自然提出了将整个系统部署到异地的多个机房中,并且多个机房能同时提供服务。
从动机出发,可以提出主要两个需求:
机房之间要有足够远的距离,例如目前淘宝的深圳、张家口机房之间相距1000公里以上(代表30-60ms的网络延迟)。但是,整个系统的响应时间要得到保证,不能因为机房之间的距离而增加系统的响应时间。下图是在淘宝的张家口机房ping深圳机房,41ms的延迟:

每个机房平时都要承担业务流量,处于“活”的状态。同时,每个机房要能按照百分比承担业务流量,并且能够动态的进行调整
不能是一个冷备的状态,这样才能提供1+1>1的容量 一个时刻活着的机房,出问题的时候才敢去切 切流是一个日常性的操作,例如对机房进行的大规模运维、升级等操作,都会先将流量切走
单元封闭
对于淘宝来说,我们选择将买家的响应时间作为第一优先级考虑的问题。如果买家的操作,例如查看商品详情、查看订单、下单等操作,需要跨越多个机房,那响应时间是无法接受的。淘宝的下单操作,实际上,涉及到上百次的服务调用。
因此我们需要考虑,将买家的操作,能够“封闭”在一个机房内,这也是淘宝提的“单元封闭”的概念。
要做到单元封闭,业务系统是要做很多改造的,需要确保这些服务调用都能够在本机房内完成。对于无状态的服务来说,相对简单,但是对于有状态的服务,例如数据库、消息队列、缓存等等,就会需要做一些事情。
单元切分的维度
从数据库角度来看,要实现单元封闭,就要将数据按照一个特定的维度进行划分,部署在该单元的服务尽可能的只访问部署在该单元的数据库。
因此,一个异地多活的系统,一定少不了一个“单元维度”的概念。所谓单元维度,简言之就是用来划分一个业务请求属于哪个单元的依据,对于数据库来说,就是某个表的某个列。
在淘宝,买家(交易、订单)、卖家(商品由于是卖家发布的,因此和商品相关的库存、评价,也是卖家维度的数据)是两大最主要的数据维度,一个下单操作,会涉及这两大维度的数据(查商品、下订单、减库存)。为了最大限度的保证买家的响应时间,淘宝选择了使用买家id来作为单元维度。
与用户地理位置无关的异地多活
淘宝将买家的操作按照买家id,分到不同的单元去。实际上,淘宝的具体做法是,将userid对10000取模,不同的区间属于不同的单元,例如:
0< userid % 10000 <=999 属于单元1,代表单元1包含了
999< userid % 10000 <=1999 属于单元2 非常简单的一个划分。
这里能看出淘宝在国内业务的一个特点,用户所在的地理位置和他的下单操作在哪个机房处理是无关的,并不存在一个就近的关系。例如,如果你的userid取模后落到了深圳机房的区间内,那么即使你在上海,你离上海机房更近,你的下单操作都由深圳机房完成。
为什么这样,这也是和淘宝的业务特点相关,下单是一个比较重的业务逻辑,上面提到过内部有上百次的服务调用,这些服务调用加起来的耗时,要远高于客户端到机房的网络延迟。所以只要保证这些服务调用内部都在一个机房内完成即可,至于客户端在哪里,其实并不重要(我们这里不涉及静态的在CDN中的内容)。
所以在这种异地多活方案里,切流操作是与用户的地理位置无关的。它只需要按百分比将一大批userid进行切换即可,并不需要关注他们实际的地理位置在哪。
淘宝异地多活的特点
我们简单总结下淘宝风格的异地多活有哪些特点,以及响应的,对数据库有哪些要求。
需要能随时按比例进行切流。如果我们采用类似这样的架构,每个单元各有一套数据库,但他们之间的数据毫无重叠,那当需要切流的时候,再去迁移数据吗?这个显然是不对的,所以这一点实际上要求每个单元的数据库必须有全量的数据,这样才有切流的基础。
业务响应时间要求高。既然每个单元都要有全量的数据,那就涉及到一个问题,如何去做单元之间数据的复制?抛开具体的实现方式不谈(通过binlog也好,通过paxos也好),简单分为同步和异步两种类型。
同步复制的方式(例如PAXOS的LEADER-FOLLOWER这种复制),我们有机会做到 RPO=0,但这样数据库的写入响应时间会非常的高(想想我们前面说到的,间距1000公里的机房代表30-60ms的的延迟),除非业务做全面的异步化改造,不然是很难接受如此高的响应时间的。
异步复制的方式(例如使用binlog,或者PAXOS的LEADER-LEARNER间的复制),可以完全不受机房之间距离的影响,响应时间可以做的很低。但相应的代价是, 机房之间数据是一种不一致的状态。这种不一致在计划内的切流数据库层是可以直接解决的,但如果是灾难下(机房挂掉)的切流,单纯数据库层是无法处理这种问题的,这就需要业务层做一些手段(例如对账),来保证数据的一致性。
从淘宝的业务特点来说,响应时间是第一优先级,选择的是异步复制的方式。
机房与用户地理位置无关。这个特点要求数据库只需要提供分片级的切换能力即可,并不需要更细粒度的切换。
PolarDB-X实现异地多活
基于PolarDB-X实现淘宝风格的异地多活,我们可以提出这样的架构图: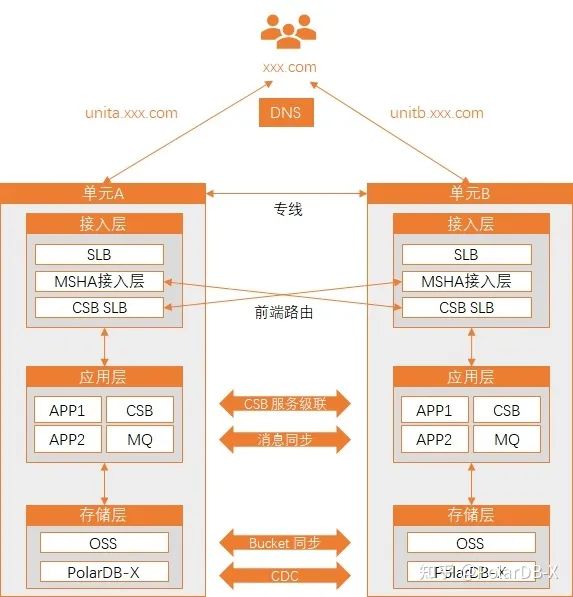
用户流量经过 DNS、SLB 进行进入系统后,会在应用层根据切分维度进行第一次路由(例如在阿里云可以使用 MSHA、CSB 等中间件来做这件事情)。在尽可能的同单元的应用调用后,将数据写入本单元的数据库。
我们重点关注数据库的部分: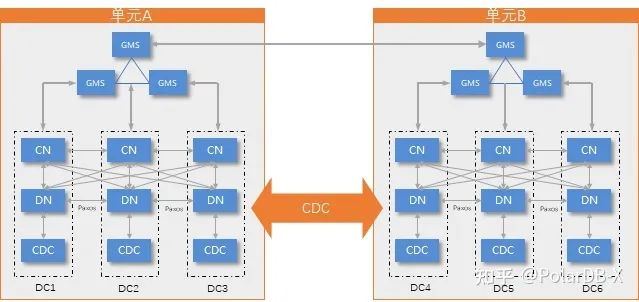
使用PolarDB-X CDC关联多个单元的实例
这里有一个非常重要的角色,PolarDB-X的CDC组件。可以简单理解为他提供两个功能:
提供PolarDB-X的binlog服务
订阅另一个PolarDB-X的binlog,从而建立起两个PolarDB-X之间的复制链路
PolarDB-X CDC 属于 PolarDB-X 内核的一部分,能屏蔽掉你能想到的常见的使用第三方组件(例如DTS、Cannal等)同步两个分布式数据库的坑,例如DDL、扩缩容、系统表等等,是一个非常帅气的组件。
有了PolarDB-X CDC之后,我们在每个单元创建一个PolarDB-X实例,并且使用PolarDB-X的CDC组件将这些实例之间建立起复制链路。
之后,这些PolarDB-X实例将不再“独立”,他们将共享同一份元数据、能感知到彼此的存在,例如,DDL操作可以在任意一侧进行。
为不同的分区设置不同的主单元(Primary Unit)
我们需要选择好单元切分的维度,例如userid,并将其作为分区表的分区键:
create table t1 (...) partition by hash(userid);
我们给不同的分区设置不同的主单元(PRIMARY UNIT),此时不在主单元的分区将变为只读(或者允许配置成禁止访问,视业务需求,这个也是有很大的业务意义的):
alter table t1 partition0 primary unit ‘unit-a’;
alter table t1 partition1 primary unit ‘unit-b’
alter table t1 partition2 primary unit ‘unit-a’
由于共享一份元数据,以上对分区的设置可以在任意的PolarDB-X实例上进行。
切换到分区视角: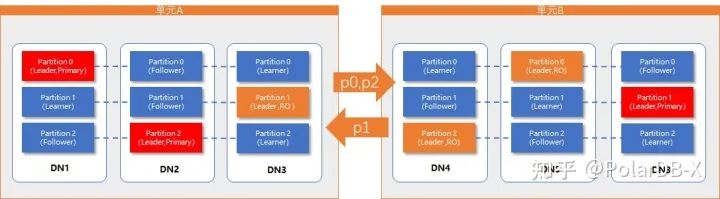
其中,partition0 与 partition2 的主单元在单元A,在单元A可读可写,在单元B只读;partition1 的主单元在单元B,在单元A只读,在单元B可读可写。
切流
PolarDB-X提供原生的计划内的分区级切换主单元的操作,切流操作会对分区做阻塞写(不报错)的操作,待数据一致之后进行切换并放开写入。
由于异地多活是一个设计整个链路的架构,流量分配需要在应用、数据库、消息队列、缓存等等组件做到步调一致。所以一般情况下,业务层会有类似MSHA等中间件来做整体的切流调度。PolarDB-X将分区级切换主单元的操作提供给这些系统,即可统一进行流量调度管理。
某运营商客服系统的案例
这是某运营商的客服系统基于PolarDB-X实现异地多活的一个案例: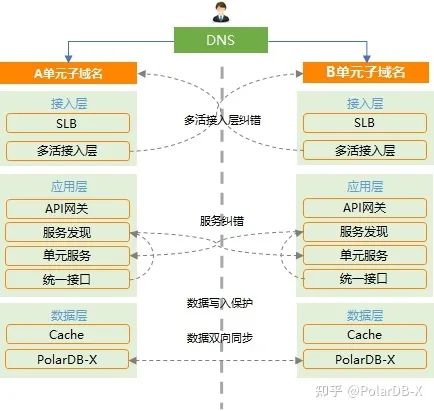
在这个例子中,单元切分维度为省份。DNS按地域分流,接入层按照路由规则判断和纠错。应用层单元化部署,服务发现实现双中心的服务同步能力。两个单元的PolarDB-X实例进行双向同步,实现数据最终一致性。
最终的效果:
客服系统的多个业务实现按地域多活分流 实现多次容灾演练,秒级完成切换,数据0丢失 客户常态两个单元均承载业务流量,充分利用两单元的资源
行级Paxos带来的新的想象
目前PolarDB-X实现的是是分区级的Paxos,因此对主单元的切换是分区级的。
如果我们的多活系统想实现这样的需求:比如我们有上海、深圳两个单元,希望用户如果今天在杭州,就由上海机房来处理,如果明天飞往了广州,就由深圳机房来处理。
这个需求对数据库的核心诉求其实是更细的复制粒度。一个分区上会有很多的用户,基于分区级的复制,我们只能对这一个分区上的所有用户做整体的一个切换。由于分区数一般是比较多的(例如淘宝的用户分区数在上万的量级),因此这种方式做百分比的切流是够用的。但是如果我们要做用户级的切流,这种方式就做不到了。
我们在探索的一种技术称为行级 Paxos(有时也称为行级多点写技术),简单理解为可以设定每一行的Paxos Group。如下图:
变成了行级的Paxos Group之后,我们就不需要再去指定每个分区的主单元了,而是通过自动调度的方式,用户通过哪个单元访问数据,我们可以自动的将所访问的数据的主单元调度到当前的单元(从应用来说看起来的效果类似于在各单元都可以对所有的数据做修改,所以才被称为行级多点写技术,但实际上和单机上的并发写完全不一样的代价)。从而达到更彻底的就近访问的目的。
不过,即使有了这种技术,异地多活也依然有它的一些门槛或者说限制。例如,虽然可以自动的做行级的主单元调度,但是这个调度过程是有代价的(调度时间至少是两地网络的延迟),所以我们依然需要避免同时从多个机房对同一行数据做修改(例如这一刻在上海机房修改了用户的记录,主单元调度到了上海,下一秒请求路由到了深圳,主单元又要被调度到上海),两地并发的对同样的数据做修改的响应时间会超过网络的延迟。因此我们依然要遵循异地多活架构下应用本身需要做流量的分区的原则,确保数据库的请求不会高频率的飘来飘去。
同时,由于整个业务系统里,有状态的组件不仅包含数据库,还包含缓存、文件存储、消息队列等等各种各样存有状态的组件,这些组件必须也支持类似数据库行级Paxos的调度能力,才能充分利用行级Paxos带来的优势(开个玩笑,如果你的应用只使用了数据库,没有使用其他带状态的组件,这件事可能就很简单了)。
总结
异地多活,是一个非常吸引人的架构。真正的实现异地多活,对系统的整体设计是一个很大的挑战,涉及的领域方方面面。选择合适的数据库层方案,能让整个过程事半功倍。
PolarDB-X通过内核内置的CDC组件、统一的元数据组件GMS、Paxos一致性协议、分区级的主单元技术等,能让业务更容易的实现异地多活。
此外,本文主要针对淘宝下单链路的异地多活提出的方案(例如低响应时间、百分比切流等特征)。异地多活的设计是一个跟应用特点关联性极强的事情,例如,有的应用可能不需要切流,单元划分是完全固定的;有的应用可能对响应时间不敏感。结合上这些特点,我们能设计出各种各样的异地多活方案。即使在同样的一个业务系统内,不同的应用可能也需要使用不同的多活方案(例如淘宝的库存,使用的就是另一种内部称为COPY类型单元化的方案)。选择最适合的才是最好的。
欢迎大家持续关注!
干货分享
最近将个人学习笔记整理成册,使用PDF分享。关注我,回复如下代码,即可获得百度盘地址,无套路领取!
•001:《Java并发与高并发解决方案》学习笔记;•002:《深入JVM内核——原理、诊断与优化》学习笔记;•003:《Java面试宝典》•004:《Docker开源书》•005:《Kubernetes开源书》•006:《DDD速成(领域驱动设计速成)》•007:全部•008:加技术群讨论
加个关注不迷路
喜欢就点个"在看"呗^_^