理解NLP中的屏蔽语言模型(MLM)和因果语言模型(CLM)

来源:DeepHub IMBA 本文约1100字,建议阅读7分钟 本文与你讨论两种流行的训练前方案,即MLM和CLM。
大多数现代的NLP系统都遵循一种非常标准的方法来训练各种用例的新模型,即先训练后微调。在这里,预处理训练的目标是利用大量未标记的文本,在对各种特定的自然语言处理任务(如机器翻译、文本摘要等)进行微调之前,建立一个通用的语言理解模型。

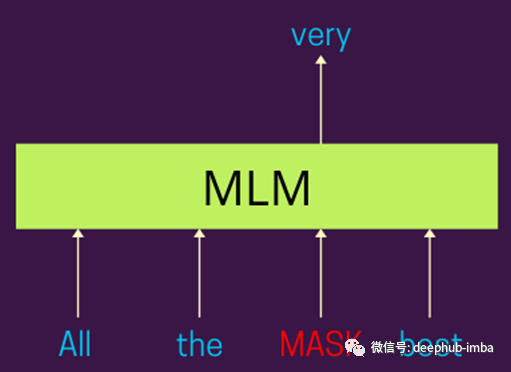
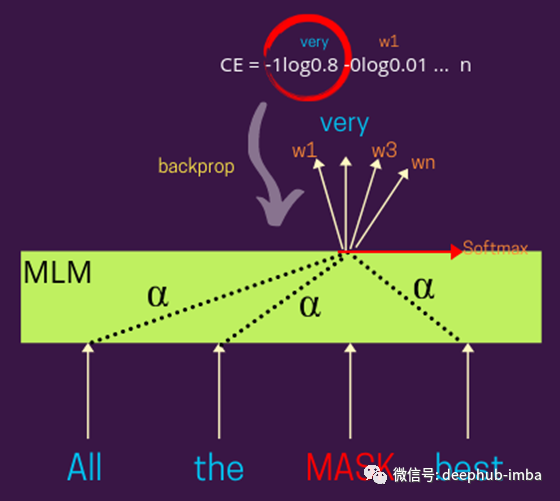
屏蔽语言模型解释
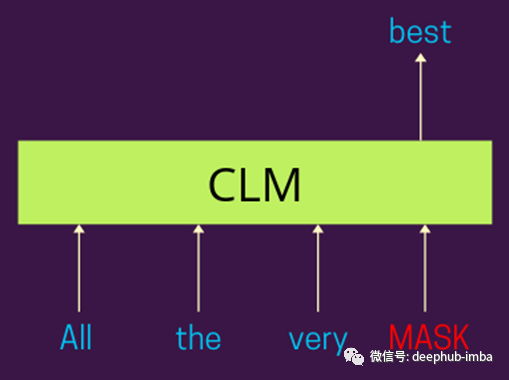
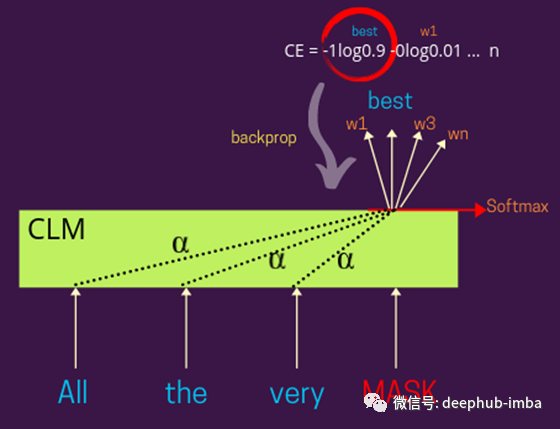
因果语言模型解释
何时使用?
编辑:黄继彦
评论
 下载APP
下载APP来源:DeepHub IMBA 本文约1100字,建议阅读7分钟 本文与你讨论两种流行的训练前方案,即MLM和CLM。
编辑:黄继彦