
Jeff Dean领衔AI助力芯片设计效率革命!6小时内完成布局设计,新一代TPU已用上
大数据文摘
共 5117字,需浏览 11分钟
·
2021-06-17 21:57

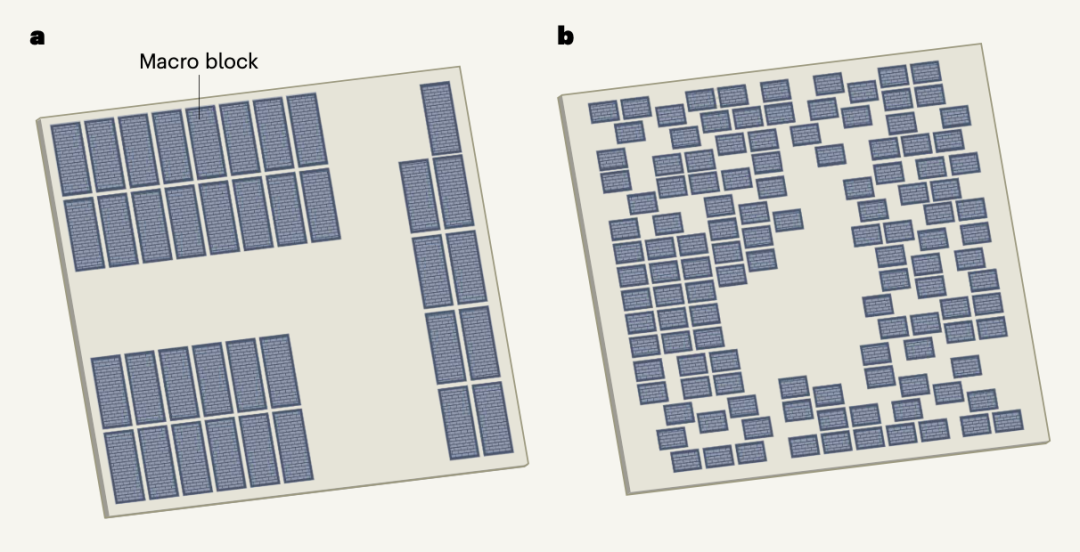

基于分区的方法(partitioning-based methods);
随机/爬山方法(stochastic/hill-climbing approaches);
解析解算器(analytic solvers)。
基于分区的方法为了扩展到更大的网表而牺牲了全局解决方案的质量,而一个糟糕的早期分区可能会导致一个无法解决的最终结果;
随机/爬山方法具有较低的设计收敛率,不能扩展到具有数百万乃至数十亿节点的现代芯片网表;
解析解算器是一种主流方法,但它只能优化可微损失函数,这意味着它们不能有效地优化关键指标,如路由拥塞或时序冲突等。


评论