
从缺陷率到质效工作的本质 | IDCF

来源:圆小豆的美梦工场 作者:于晓南
讨论来自一个社区朋友。
一、缺陷率迷思

1.1 千行代码缺陷率被废弃
千行代码缺陷率 = Bug数量 / 千行代码数
这是一个经典指标,以前在研发侧经常用来衡量代码质量,近年被逐渐弃用。
原因是这个指标有负面的引导,似乎不鼓励写高质量的简洁代码,而稀释代码或造轮子则能带来比较好看的数据,这与指标设置的初衷“提升代码质量”相悖。
因此,该指标不建议横向比较,不建议作为绩效指标。但可以作为代码质量指导基线,或作为工程师的自我修养,用于自我评估和改进。
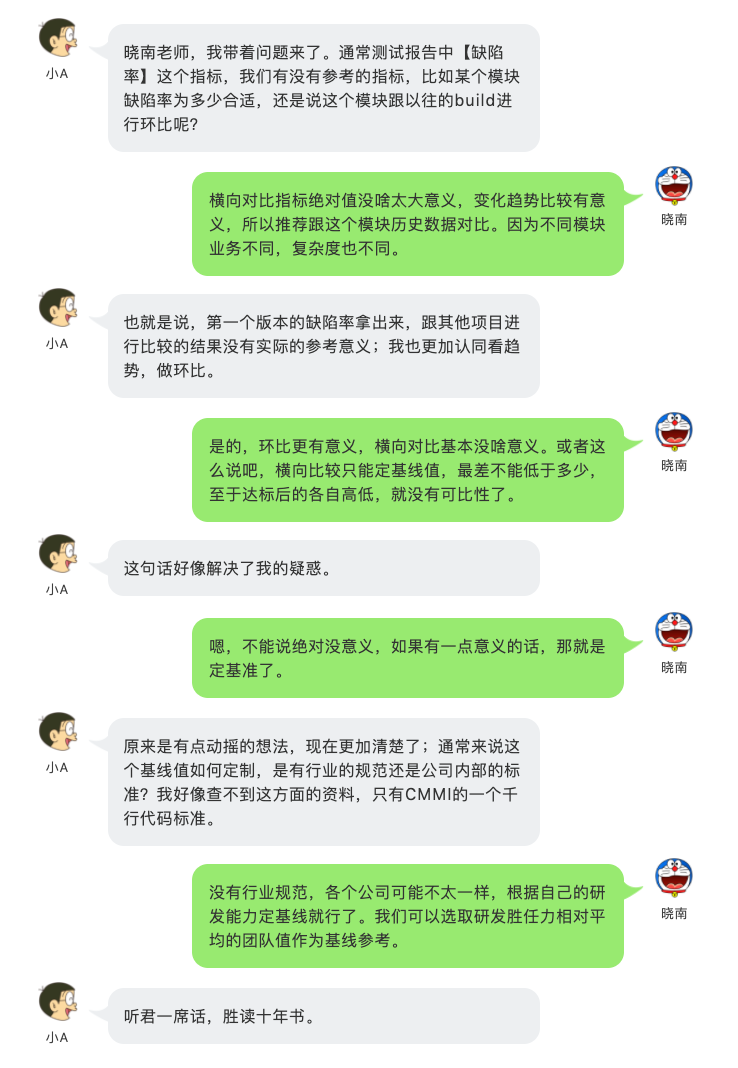
附上在CMMI里对千行代码缺陷率的标准,不难看出缺陷率还是以一个满足该等级的基线值存在的,也就是说它不能用来衡量代码质量有多好,但可以用来衡量代码质量最差不能低于什么水平。

1.2 缺陷率无法体现软件质量
缺陷率 = 失败的用例数 / 执行的用例总数
从字面意义上理解,这个指标看着像是衡量软件质量的。但放入研发体系内思考,通常在不同版本间,执行的用例总数是变化的,失败的用例数也取决于用例执行者的判断,而失败的用例又不一定会以缺陷的形式来跟踪。所以这个指标很难有确定的标准,那么它还是有意义的吗?
我认为是有意义的,意义在于它揭示了测试设计的质量,即经过设计的测试用例能否有效发现缺陷。从这个维度上讲,这个指标恐怕叫“用例有效率”更恰当一点。
不管是千行代码缺陷率,还是测试统计的缺陷率,统计时难免会陷入数据的迷思。片面追求数据好看,对团队的副作用很大,结果可能是既不经济、也没成效,平白做了很多无用功。思考质效工作如何经济又高效,有助于避开局部优化的泥沼。
二、质效管理投资回报
2.1 不是指标的锅,而是思路偏差
由上面的讨论容易得出以下结论:
第一,从度量引导团队改进的意义角度来看:指标数量绝对值 < 指标的环比(无任何时间间隔,连续周期内的变化),应更多关注团队指标的变化趋势,以及思考是什么原因引起的变化,该如何改进; 第二,团队内的任何投资,都需要考虑投入产出比 ROI,为了得到结果而付出巨大的代价,本身就是一种失效。尤其当资源被投入到“质效提升或管理”这类成本高见效慢的活动时,考虑是否经济尤为重要。
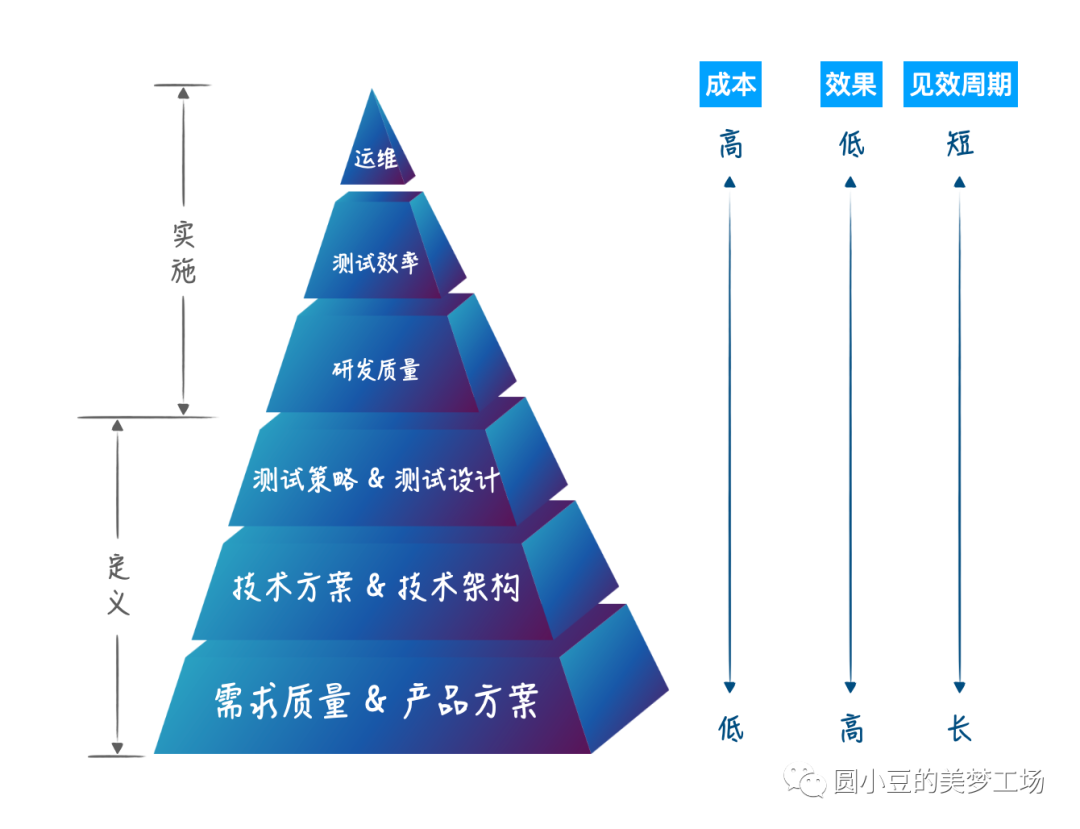
在定义阶段发力,成本低、见效期长,但治理效果最好,问题根因也往往会追溯到此; 在实施阶段发力,成本高、见效期短,但治理效率偏低,数据好看但治标不治本。

三、质效工作本质是打造高效高响应系统

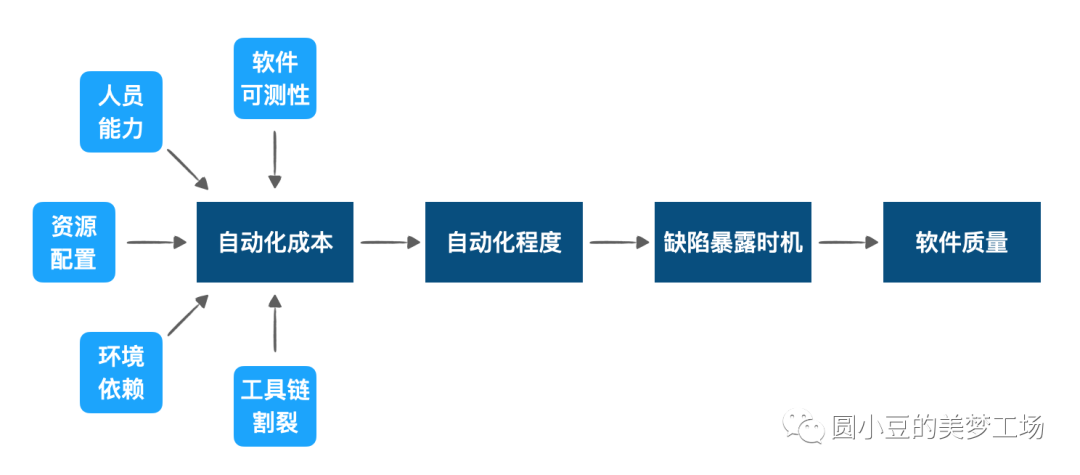
软件本身的可测性:当软件可测性较低时,自动化成本就会飞升,甚至根本不具备可自动化的条件。而这个因素的可控性受制于软件的架构设计,在软件成熟期不具备可改进的灵活性。因此建议在做架构设计时就充分考虑软件可测性,否则后续的自动化测试会难以开展。 人员能力:这里不仅仅指自动化测试的编码能力,更要求测试人员具备一定的测试设计能力。能够充分理解测试分层,不同层的测试服务于什么目标,解决什么问题,以及测试的框架选型等能力。 资源配置:指团队的研发节奏,能否有余力进行充分的自动化测试。 环境依赖:自动化测试如果不能持续运行,就会失去尽早暴露缺陷的时机,而持续运行依赖于能排除干扰的稳定环境。 工具链割裂:指团队的工具链体系是否支持自动化测试持续集成,或者不同层级的自动化测试工具是否具备一致性。这在一定程度上影响自动化测试的可维护性。




评论