
HorovodTensorFlow 分布式深度学习框架
Horovod 是 Uber 开源的针对 TensorFlow 的分布式深度学习框架,旨在使分布式深度学习更快速,更易于使用。
Horovod 吸取了 Facebook 的 Training ImageNet in 1 Hour(一小时训练 ImageNet) 论文与百度 Ring Allreduce 的优点,为用户实现分布式训练提供帮助。该项目主要是想能够轻松采用单个 GPU TensorFlow 程序,同时也能更快地在多个 GPU 上成功地对其进行训练。使用 Horovod 我们可以不需要再去担心或学习很多东西,如 tf.Server()、tf.ClusterSpec()、tf.train.SyncReplicasOptimizer()、tf.train.replicas_device_setter()等等。
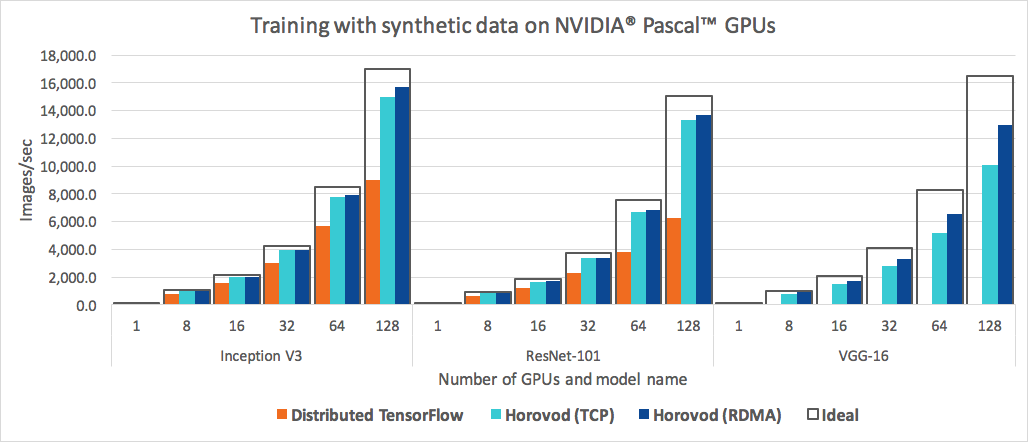
除了易于使用,Horovod 的速度也很快。下图为 Inception V3 和 ResNet-101 TensorFlow 模型在 25GbE TCP 上使用不同数量的 NVIDIA Pascal GPU 时,使用标准分布式 TensorFlow 和 Horovod 运行分布式训练工作每秒处理的图像数量对比。
评论