
Uber JVM Profiler分布式追踪工具
JVM Profiler 是 Uber Engineering 团队开源的一个分布式探查器,用于收集性能和资源使用率指标为进一步分析提供服务。尽管它是为 Spark 应用而构建的, 但它的通用实现使其适用于任何基于 JVM 的服务或应用。
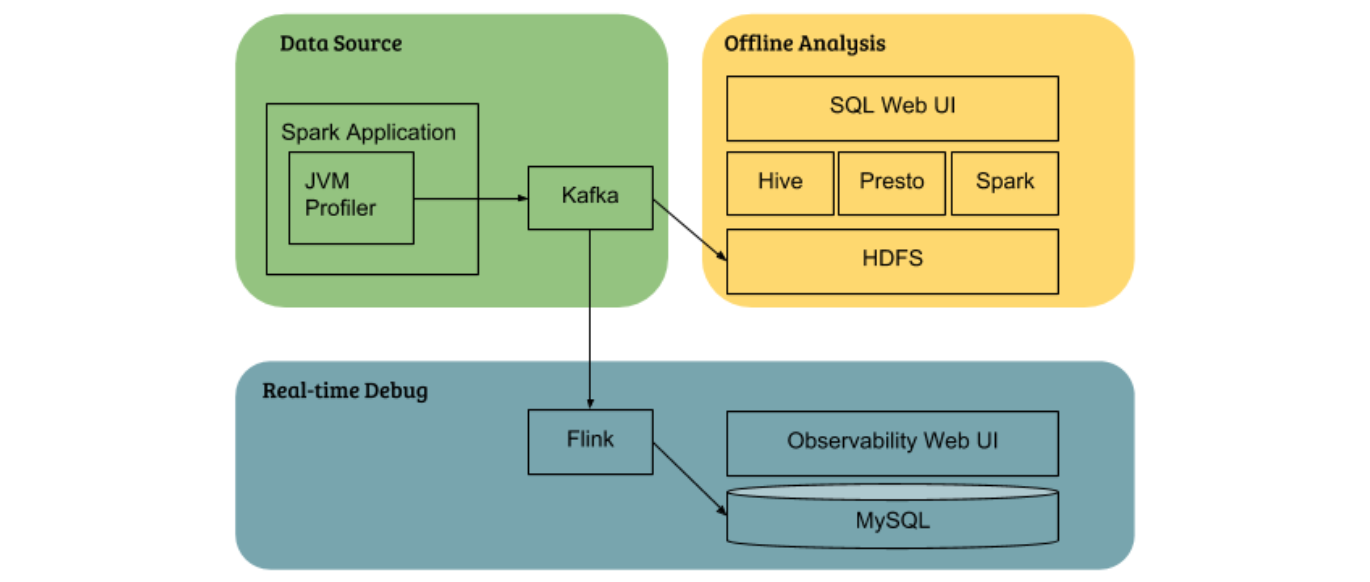
JVM Profiler 由三项主要功能组成, 它使收集性能和资源使用率指标变得更容易, 然后可以将这些指标 (如 Apache Kafka) 提供给其他系统进行进一步分析:
代理功能 ( java agent ) : 支持用户以分布式的方式收集各种指标 (例如如 CPU/内存利用率) ,用于 JVM 进程的堆栈跟踪。
高级分析功能(Advanced profiling capabilities): 支持跟踪任意 Java 方法和用户代码中的参数, 而不进行任何实际的代码更改。此功能可用于跟踪 Spark 应用的 HDFS NameNode RPC 调用延迟, 并标识慢速方法调用。它还可以跟踪每个 Spark 应用读取或写入的 HDFS 文件路径, 用以识别热文件后进一步优化。
数据分析报告( Data analytics reporting ): 使用 JVM Profile 可以将指标数据推送给 Kafka topics 和 Apache Hive tables , 提高数据分析的速度和灵活性。
典型用例
JVM Profiler 支持各种用例, 最典型的是能够检测任意 Java 代码。基于简单的配置, JVM Profiler 就可以附加到 Spark 应用中的每个执行者(executor)收集 Java 方法运行时度量。下面, 我们对其中的一些用例进行讨论:
Right-size executor : JVM Profiler 中的内存度量支持跟踪每个执行者的实际内存使用情况。借此 可以在 Spark 应用中 ”executor-memory” 设置最优参数。
监视 HDFS NameNode RPC 延迟: 例如在 Spark 应用中对类 org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB 的方法进行了分析并确定 NameNode 调用的延迟。Uber 每天都要监控5万多个 Spark 应用, 其中有数以亿计的这种 RPC 调用。
监视驱动程序丢弃的事件: 例如监视 org.apache.spark.scheduler.LiveListenerBus.onDropEvent, 跟踪 Spark 驱动程序事件队列太长、队列删除事件。
跟踪数据沿袭: 例如分析 Java 方法上的文件路径参数 ( org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getBlockLocations , org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock ) , 可以跟踪哪些文件是由 Spark 应用读取和写入的。
介绍来源:RiboseYim