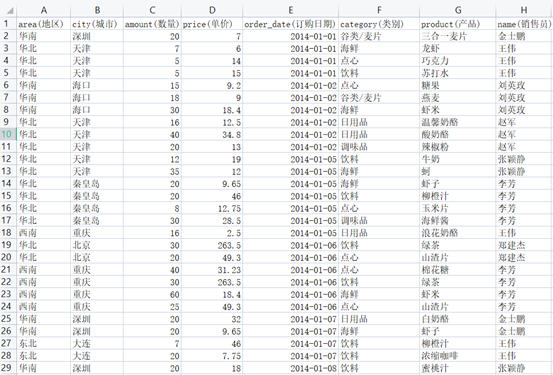
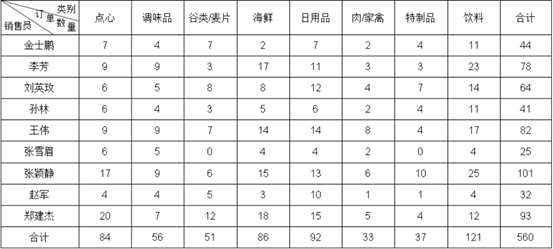
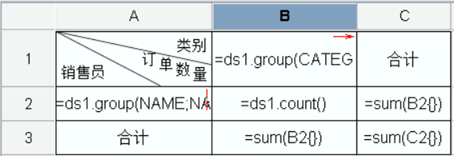
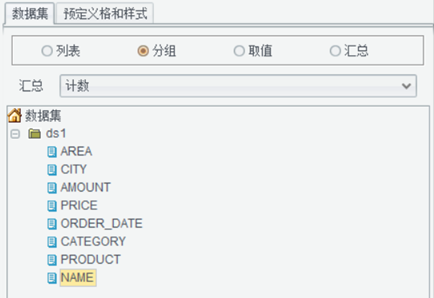
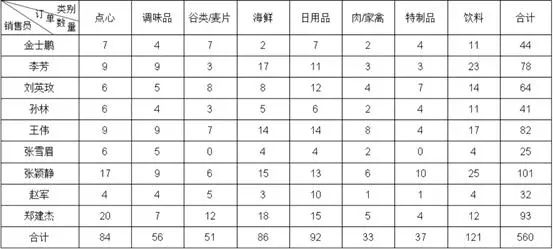
根据如下数据表,制作报表按销售员、类别统计订单数量,并增加合计,结果报表:制作过程数据集设置ds1: select * from orderlist报表模板设计A2:=ds1.group(NAME;NAME:1),按照销售员分组,可以手动输入公式,也可以报表设计器右下角选择分组方式拖拽:B1:=ds1.group(CATEGORY;CATEGORY:1),操作方式同 A2,设置扩展方式为横向B2:设计器右下角,选择汇总,汇总方式选择“计数”,拖拽任意字段到 B2 单元格B3、C2、C3:合计单元格,表达式手动输入:=sum(B2{})报表结果对于这类简单报表,各工具效率上基本没有什么差异,润乾报表是直接写表达式(也可以拖拽),其他工具有写表达式的,也有拖拽做的,都比较简单。有些工具的可视化的点击操作做得更人性化,体验更好,更适合初级学习人员
示例 2:带条件的分组
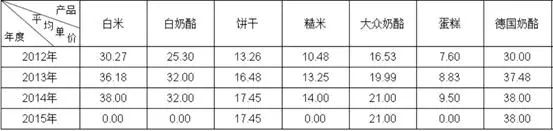
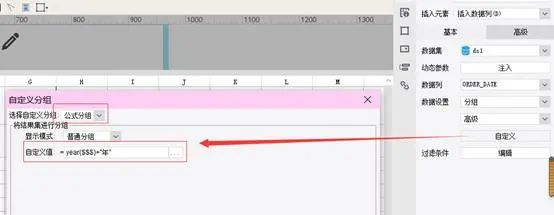
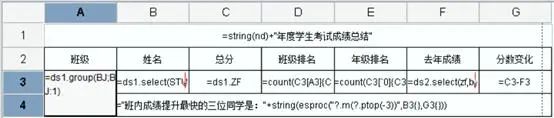
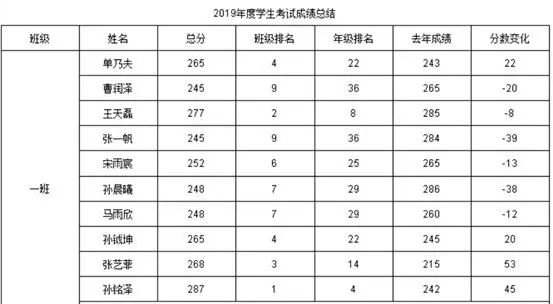
基于同一个数据表,我们改一下表样,稍微增加一些难度,根据日期字段中的年来分组,看看不同产品的操作上有什么变化按照年度统计产品的平均售价,单笔采购数量不同、采购时间不同,产品的单价可能不同,产品平均单价 = 总金额 / 总数量结果表样:制作过程数据集设置ds1:SELECTORDERLIST.ORDER_DATE,ORDERLIST.PRODUCT,ORDERLIST.PRICE,ORDERLIST.AMOUNT FROM ORDERLIST报表模板设计A2:=ds1.group(year(ORDER_DATE);ORDER_DATE:1)+“年”,取字段的年并分组B1:=ds1.group(PRODUCT;PRODUCT:1),按产品字段分组并设置横向扩展B2:=ds1.sum(PRICEAMOUNT)/ds1.sum(AMOUNT),先通过 PRICEAMOUNT 算出金额,再进行汇总,然后除以总数量。难度稍微增加以后,润乾报表还是只要在单元格里写简单的表达式就可以了,依旧简单。但有些工具不支持格子里自由写公式和条件,只能在对话框里设置,结果就是拖拽完基础表达式以后,还得打开对话框设置一下条件才可以,比如这个按年分组从这个报表就已经可以看出一些端倪了,ds1.group(year(ORDER_DATE);ORDER_DATE:1)+"年" 是写一个这样的表达式,还是每次都多点几步对话框去设置,哪种方法的工作效率更高呢?只考察最简单的情况是看不出这些区别的
示例 3:再复杂一些的分组
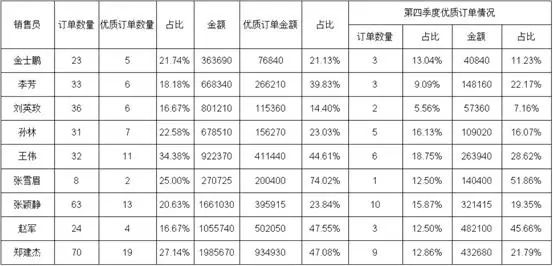
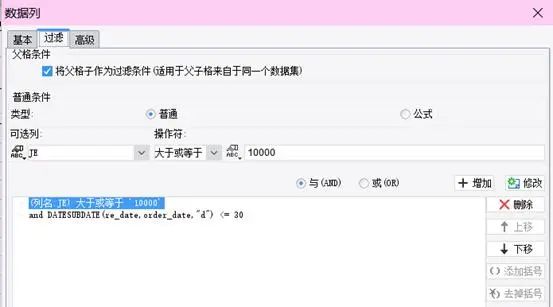
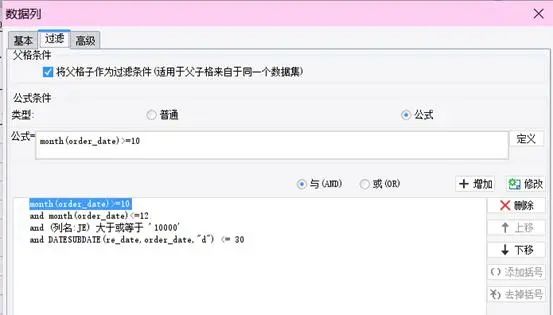
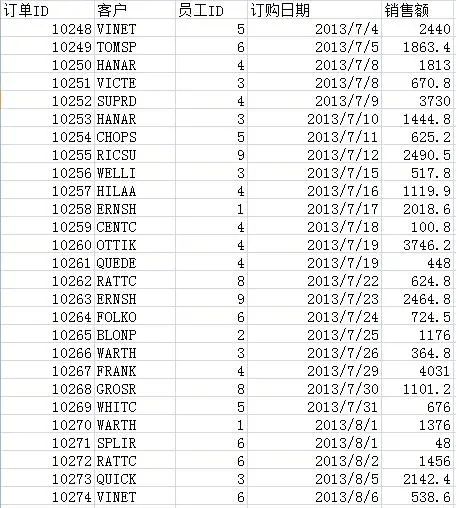
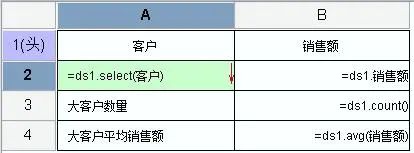
还是基于这个数据表,我们做个一个格式再复杂一些的表样按销售人员统计优质订单的情况,优质订单指:回款日期在订单日期 30 日内且单笔订单金额 >=10000制作过程数据集设置ds1:select order_date,price,amount,name,re_date from orderlist where substr(order_date,0,4)=‘2012’报表模板设计A3:=ds1.group(NAME;NAME:1),可以鼠标拖拽,也可以手动输入B3:=ds1.count()C3:=ds1.count(price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30)D3:=C3/B3,设置显示格式为“#0.00%”E3:=ds1.sum(PRICE*amount)F3:=ds1.sum(PRICE*amount,price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30),条件表达式和 C3 一样,可以在 =ds1.sum(PRICE*amount) 基础上,直接将条件表达式复制过来G3:将 D3 直接复制到 G3,单元格引用名称自动变化,显示格式保留H3:=ds1.count(price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30 and month(ORDER_DATE)>=10 and month(ORDER_DATE)<=12),在 C3 的基础上增加季度判断条件I3:=H3/B3,设置显示格式为“#0.00%”J3:=ds1.sum(PRICE*amount,price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30 and month(ORDER_DATE)>=10 and month(ORDER_DATE)<=12),在 E3 的基础上,直接将 H3 的条件表达式复制过来K3:将 I3 直接复制到 K3,单元格引用名称自动变化,显示格式保留到这个例子,是不是已经感觉这些表达式写起来也没有多困难了,即使是初学者,也能轻易看懂并写出来了,是的,有这样的感觉就对了,对于搞计算机的同学,这确实不难再来看看其他的一些只能通过对话框来设置条件的工具处理这样的情况会怎样每增加一个条件,一个 and,就得点一次增加,如果要修改,删除,同样得挨个去点,每次设置还都得打开、关闭一次对话框如果每次都得这样,估计初学者也不会觉得简单而是会感到麻烦了,更别说熟练的老同学了这样无端端多出了好多没必要的操作,会浪费很多的时间,减少很多产出懂了表达式以后,还是直接写表达式更快更好,可视化操作看上去很美,但效率并不会高






 下载APP
下载APP