
你可能也会掉进这个简单的 String 的坑
/**
* @param status
* @param result, the size should less than 1000 bytes
* @throws Exception
*/
public XXResult(boolean status, String result) {
if (result != null && result.getBytes().length > 1000) {
throw new RuntimeException("result size more than 1000 bytes!");
}
......
}
result 也不是什么关键性的东西,你有限制,我直接 trim 一下不就行了?
解决方案
trim 方法,支持传不同参数按需 trim,代码如下:/**
* 将给定的字符串 trim 到指定大小
* @param input
* @param trimTo 需要 trim 的字节长度
* @return trim 后的 String
*/
public static String trimAsByte(String input, int trimTo) {
if (Objects.isNull(input)) {
return null;
}
byte[] bytes = input.getBytes();
if (bytes.length > trimTo) {
byte [] subArray = Arrays.copyOfRange(bytes, 0, trimTo);
return new String(subArray);
}
return input;
}
trimAsByte 方法,一顿操作连忙上线,一切完美~
灾难现场


trimAsByte("WeChat:tangleithu", 8)
WeChat:tangleithu 太长了,只 trim 到剩下 8 个字节,对应的字节数组是从 [87,101,67,104,97,116,58,116,97,110,103,108,101,105,116,104,117] 变为了 [87,101,67,104,97,116,58,116],字符串变成了 WeChat:t ,结果正确。trimAsByte("程序猿石头", 8)

程序猿石头,3 个字节一个汉字,一共 15 个字节 [-25,-88,-117,-27,-70,-113,-25,-116,-65,-25,-97,-77,-27,-92,-76],trim 到 8 位,剩下前 8 位 [-25,-88,-117,-27,-70,-113,-25,-116] 也正确。再 new String,又变成3 个 “中文” 了,虽然第 3 个“中文”,咱也不认识,咱也不敢问到底读啥,总之再转换成字节数组,长度多了 1 个,变成 9 了。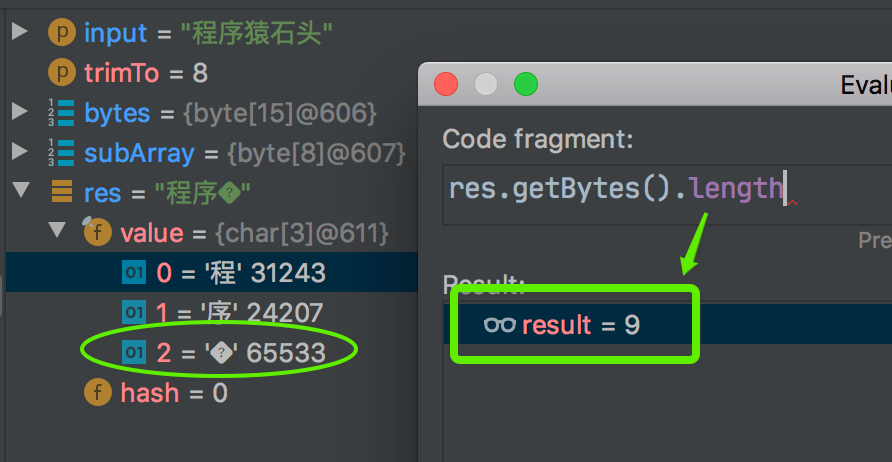
不禁要问,为什么?
/**
* Constructs a new {@code String} by decoding the specified array of bytes
* using the platform's default charset. The length of the new {@code
* String} is a function of the charset, and hence may not be equal to the
* length of the byte array.
*
*The behavior of this constructor when the given bytes are not valid
* in the default charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @since JDK1.1
*/
public String(byte bytes[]) {
//this(bytes, 0, bytes.length);
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}

[-25,-88,-117,-27,-70,-113,-25,-116,-65,-25,-97,-77,-27,-92,-76] 仍然用这串字节数组来实验,这串字节数组,如果用 “UTF-8” 编码去解释,那么其想表达的语义就是中文“程序猿石头”,从上文标注的 1,2,3 中可以看出来,没有写即用了系统中的默认编码“UTF-8”。� 是不是似曾相识;� 其实是 UNICODE 编码方式中的一个特殊的字符,也就是 0xFFFD(65535),其实是一个占位符(REPLACEMENT CHARACTER),用来表达未知的、没办法表达的东东。上文中在进行编码转换过程中,出现了这个玩意,其实也就是没办法准确表达含义,会被替换成这个东西,因此信息也就丢失了。你可以试试前面的例子,比如把前 8 个字节中的最后一两个字节随便改改,都是一样的。
总结
trim 方法,其实很容易写个单元测试就能尽早发现有问题;有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论