
Redis缓存问题-缓存雪崩、缓存击穿、缓存穿透
一、缓存雪崩
1、什么是缓存雪崩?
缓存雪崩是指缓存中大批量数据在同一时间过期,这一瞬间Redis跟没有一样,所有的请求都打到数据库上,会导致数据库压力过大甚至宕机。
2、举例说明
以淘宝平台为例,假设某位研发同学将淘宝首页所有商品在缓存中的过期时间设置为同一时间,双十一零点抢购,大量用户涌入,访问淘宝(见缓存雪崩示意图,此时M大概有几千万),倒霉的是此时首页所有商品的缓存在这一刻都过期了,那么这几千万的访问请求都落到了数据库上,在如此高的并发量下,数据库必然扛不住,可能会挂掉。
3、如何避免缓存雪崩?
(1)、事发前:保证Redis的高可用,主从架构+Sentinel(哨兵),或者Redis Cluster(Redis集群),一旦主节点挂掉,其他节点可以继续提供服务。如果Redis是集群部署,将热点数据均匀分布在不同的Redis库中,也可避免全部失效的问题。
(2)、事发中:限流降级组件,如果服务和接口都有限流机制,就算缓存全部失效了,但是请求的总量是有限制的,可以在承受范围之内,这样短时间内系统响应慢点,但不至于挂掉,影响整个系统。
常见的限流降级组件有Hystrix(SpringCloud断路器)和Sentinel(阿里巴巴开源的限流降级组件)。
(3)、事发后:Redis持久化(RDB + AOF组合策略),万一Redis真的挂了,重启Redis从磁盘加载数据到内存,快速恢复缓存数据。
(4)、优化缓存过期时间:设计缓存时,为每一个 key 设置不同的过期时间(一般是给每个Key的失效时间都加个随机值),避免大量的 key 在同一时刻集中失效。
setRedis(Key,value,time + Math.random() * 10000);
(5)、热点数据设置永不过期,有更新操作则更新缓存即可。
二、缓存击穿
1、什么是缓存击穿?
缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,会导致数据库压力过大甚至宕机。
2、缓存击穿和缓存雪崩
缓存击穿和缓存雪崩有点像,二者的区别如下:
缓存雪崩:大量的数据在同一时间过期,所有的请求打到数据库,导致数据库压力过大。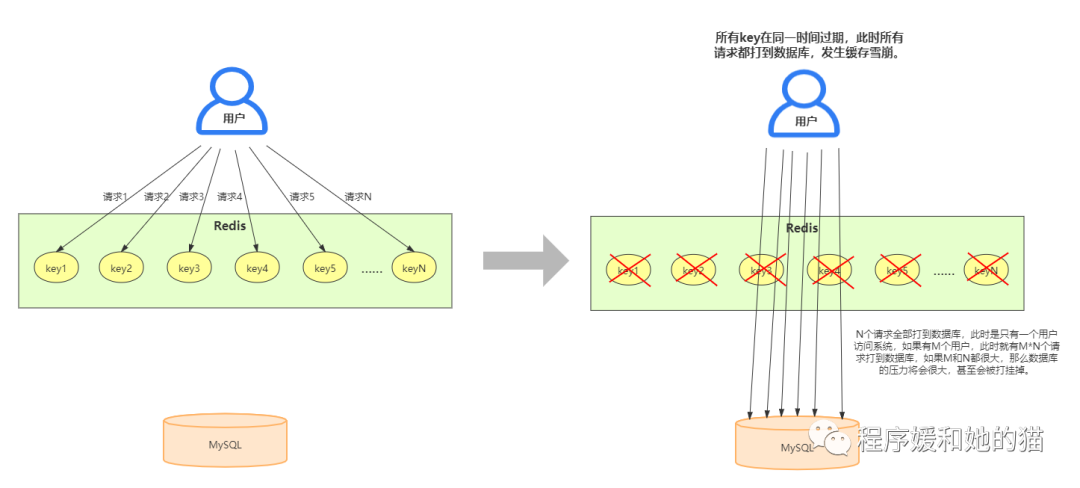 缓存雪崩示意图
缓存雪崩示意图
缓存击穿:并发请求同一个数据(热点数据),这个数据在某一瞬间失效,所有的并发请求打到数据库,导致数据库压力过大。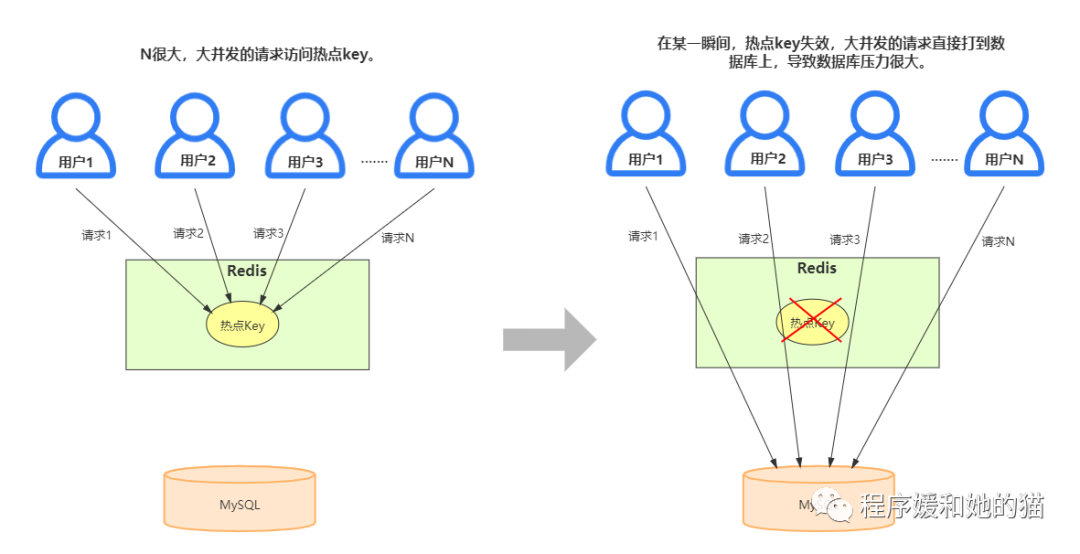
缓存击穿示意图
3、举例说明
李佳琪今晚24点抖音直播,Lamer面霜做活动,前500名打3折,这么便宜,想必很多小仙女都会去抢购,24点到了,大家都涌进直播间抢购商品,如果这个时候,该商品在缓存中过期了,那么这么高的请求全部都打到数据库上了,数据库可能承受不了压力,一下子就崩了,完了,一件也没卖出去,用户对平台的印象分也大大降低。
4、如何避免缓存击穿?
(1)、可以将热点数据的过期时间设置为永久有效(有人可能会问,万一这个热点商品下架了,这个缓存不就成了了脏数据吗?其实会有这种场景存在,主要还是具体情况具体分析,看业务场景吧)。
(2)、使用互斥锁:当在缓存中拿不到数据时,只让一个线程去查询数据库,拿到数据后,重新设置到缓存中,其他线程等到缓存重建完,直接从缓存中读取数据即可。
如果是单机,可以用synchronized或者Lock来处理,如果是分布式环境可以用分布式锁。
// 单机锁
public synchronized String getValue(String key) {
String value = redis.get(key);
if (value == null) {
value = db.get(key);
redis.set(key, value);
}
return value;
}
// 分布式锁
public String getValue(key) {
String value = redis.get(key);
if (value == null) {
// 使用setnx做分布式锁
// 设置3分钟的超时,是为了防止由于del操作失败,后续线程一直操作数据库而降低效率。
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) {// 加锁成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else {
// 获取到分布式锁的线程已经重建好缓存了,其他线程直接从缓存中获取即可。
sleep(50);
value = get(key);
}
} else {
return value;
}
}
三、缓存穿透
1、什么是缓存穿透?
缓存穿透是指访问缓存和数据库中都没有的数据,这样的话,每次请求都会打到数据库上,如果是高并发的请求(一般是黑客故意攻击),就会导致数据库压力过大甚至宕机。

2、举例说明
还是拿淘宝平台举例,假设某位研发同学在开发一个接口的时候,默认当在缓存中查询不到数据,就从数据库中查询。
我们数据库的 id 都是1开始自增上去的,黑客抓住这个漏洞,如果他想恶意攻击,写一个脚本,将查询 id 为 -1 的请求循环发送100w次,那么由于缓存和数据库不会存在这条数据,那么这100w请求都会打到数据库,数据库承受不住压力,可能就挂掉了。
3、如何避免缓存穿透?
(1)、使用布隆过滤器(Bloom Filter)在缓存前进行拦截,过滤一些异常的请求,将数据库中存在的数据写入布隆过滤器,那么当用户访问一个数据库中不存在的数据,在布隆过滤器那块就被拦截了。
(2)、针对在数据库中找不到记录的,我们仍然将该空数据存入缓存中(key对应的value设置成null、“稍后重试”等),当然一般会设置一个较短的过期时间。
(3)、对请求参数做校验,例如可以用正则,比如上面的那个例子,id <=0 的请求直接返回。