
缓存穿透、缓存击穿、缓存雪崩解决方案
前言
我一个QPS不到10的项目,天天问我缓存穿透、缓存击穿、缓存雪崩,我是真滴难。

可能大家经常会有这种感受,但是只要是面试要问的题目,就算用不上,我们也要去学习和了解,谁叫我们穷了。

正文
缓存穿透
描述:访问一个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。
此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用。
解决方案:
1、接口校验。在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
2、缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
3、布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
布隆过滤器
布隆过滤器的特点是判断不存在的,则一定不存在;判断存在的,大概率存在,但也有小概率不存在。并且这个概率是可控的,我们可以让这个概率变小或者变高,取决于用户本身的需求。
布隆过滤器由一个 bitSet 和 一组 Hash 函数(算法)组成,是一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。
在初始化时,bitSet 的每一位被初始化为0,同时会定义 Hash 函数,例如有3组 Hash 函数:hash1、hash2、hash3。
写入流程
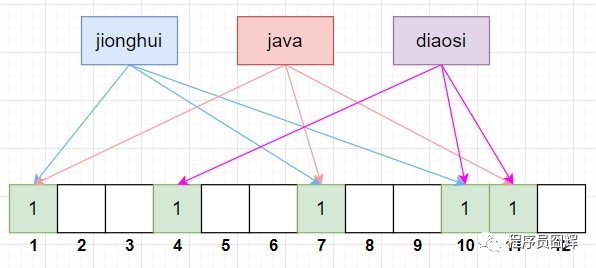
当我们要写入一个值时,过程如下,以“jionghui”为例:
1)首先将“jionghui”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)将 bitSet 的这3个下标标记为1。
假设我们还有另外两个值:java 和 diaosi,按上面的流程跟 3组 Hash 函数分别计算,结果如下:
java:Hash 函数计算 bitSet 下标为:1、7、11
diaosi:Hash 函数计算 bitSet 下标为:4、10、11
查询流程
当我们要查询一个值时,过程如下,同样以“jionghui”为例::
1)首先将“jionghui”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)查看 bitSet 的这3个下标是否都为1,如果这3个下标不都为1,则说明该值必然不存在,如果这3个下标都为1,则只能说明可能存在,并不能说明一定存在。
其实上图的例子已经说明了这个问题了,当我们只有值“jionghui”和“diaosi”时,bitSet 下标为1的有:1、4、7、10、11。
当我们又加入值“java”时,bitSet 下标为1的还是这5个,所以当 bitSet 下标为1的为:1、4、7、10、11 时,我们无法判断值“java”存不存在。
其根本原因是,不同的值在跟 Hash 函数计算后,可能会得到相同的下标,所以某个值的标记位,可能会被其他值给标上了。
这也是为啥布隆过滤器只能判断某个值可能存在,无法判断必然存在的原因。但是反过来,如果该值根据 Hash 函数计算的标记位没有全部都为1,那么则说明必然不存在,这个是肯定的。
降低这种误判率的思路也比较简单:
1)一个是加大 bitSet 的长度,这样不同的值出现“冲突”的概率就降低了,从而误判率也降低。
2)提升 Hash 函数的个数,Hash 函数越多,每个值对应的 bit 越多,从而误判率也降低。
布隆过滤器的误判率还有专门的推导公式,有兴趣的可以去搜相关的文章和论文查看。
HashMap 和 布隆过滤器
估计有同学看了上面的例子,会觉得使用 HashMap 也能实现。
确实,当数据量不大时,HashMap 实现起来一点问题都没有,而且还没有误判率,简直完美,还要个鸡儿布隆过滤器。

不过,当数据量上去后,布隆过滤器的空间优势就会开始体现,特别是要存储的 key 占用空间越大,布隆过滤器的优势越明显。
Guava 中的 BloomFilter 在默认情况下,误判率接近3%,大概要使用5个 Hash 函数。
也就是说一个 key 最多占用空间就是 5 bit,而且当多个 key 填充同一个 bit 时,会进一步降低使用空间。
布隆过滤器占用多少空间,主要取决于 Hash 函数的个数,跟 key 本身的大小无关,这使得其在空间的优势非常大。
缓存击穿
描述:某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
解决方案:
1、加互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
关于互斥锁的选择,网上看到的大部分文章都是选择 Redis 分布式锁(可以参考我之前的文章:面试必问的分布式锁,你懂了吗?),因为这个可以保证只有一个请求会走到数据库,这是一种思路。
但是其实仔细想想的话,这边其实没有必要保证只有一个请求走到数据库,只要保证走到数据库的请求能大大降低即可,所以还有另一个思路是 JVM 锁。
JVM 锁保证了在单台服务器上只有一个请求走到数据库,通常来说已经足够保证数据库的压力大大降低,同时在性能上比分布式锁更好。
需要注意的是,无论是使用“分布式锁”,还是“JVM 锁”,加锁时要按 key 维度去加锁。
我看网上很多文章都是使用一个“固定的 key”加锁,这样会导致不同的 key 之间也会互相阻塞,造成性能严重损耗。
使用 redis 分布式锁的伪代码,仅供参考:
public Object getData(String key) throws InterruptedException {Object value = redis.get(key);// 缓存值过期if (value == null) {// lockRedis:专门用于加锁的redis;// "empty":加锁的值随便设置都可以if (lockRedis.set(key, "empty", "PX", lockExpire, "NX")) {try {// 查询数据库,并写到缓存,让其他线程可以直接走缓存value = getDataFromDb(key);redis.set(key, value, "PX", expire);} catch (Exception e) {// 异常处理} finally {// 释放锁lockRedis.delete(key);}} else {// sleep50ms后,进行重试Thread.sleep(50);return getData(key);}}return value;}
2、热点数据不过期。直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。
这种方式适用于比较极端的场景,例如流量特别特别大的场景,使用时需要考虑业务能接受数据不一致的时间,还有就是异常情况的处理,不要到时候缓存刷新不上,一直是脏数据,那就凉了。
缓存雪崩
描述:大量的热点 key 设置了相同的过期时间,导在缓存在同一时刻全部失效,造成瞬时数据库请求量大、压力骤增,引起雪崩,甚至导致数据库被打挂。
缓存雪崩其实有点像“升级版的缓存击穿”,缓存击穿是一个热点 key,缓存雪崩是一组热点 key。
解决方案:
1、过期时间打散。既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
2、热点数据不过期。该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
3、加互斥锁。该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。
最后
金三银四的季节,相信有不少同学正准备跳槽。
我将我最近的原创的文章进行了汇总,其中有不少面试高频题目解析,很多都是我自己在面试大厂时遇到的,我在对每个题目解析时都会按较高的标准进行深入探讨,可能只看一遍并不能完全明白,但是相信反复阅读,定能有所收获。
有兴趣的同学可以在我公众号底部的“原创汇总”自行查看。
原创不易,如果你觉得本文写的还不错,对你有帮助,请通过【点赞】让我知道,支持我写出更好的文章。
推荐阅读