骨干网络大一统!Meta-Transformer
在迈向通用人工智能(AGI)的诸多可能的方向中,发展多模态大模型(MLLM)已然成为当前炙手可热的重要路径。在 GPT4 对图文理解的冲击下,更多模态的理解成为学术界关注的焦点,通感时代真要来了吗?
我们知道,人类在学习的过程中不仅仅会接触到文字、图像,还会同时接触声音、视频等各种模态的信息,并在脑中对这些信息同时进行加工处理和统一学习。
那么:人工智能可以具备人类统一学习多模态信息的能力吗?事实上,多模态之间的互补性可以增强人工智能的学习能力,比如,CLIP 将图像与文本进行统一学习的方式就取得了巨大的成功。但受限于多种模态之间巨大的差异性以及现有多模态模型对配对数据的依赖性,实现模态通用感知存在着艰巨挑战。
为了解决上述挑战,近日,香港中文大学多媒体实验室联合上海人工智能实验室的研究团队提出一个统一多模态学习框架 ——Meta-Transformer,采用全新的设计思路,通过统一学习无配对数据,可以理解 12 种模态信息。


-
网站地址:https://kxgong.github.io/meta_transformer/ -
代码地址:https://github.com/invictus717/MetaTransformer
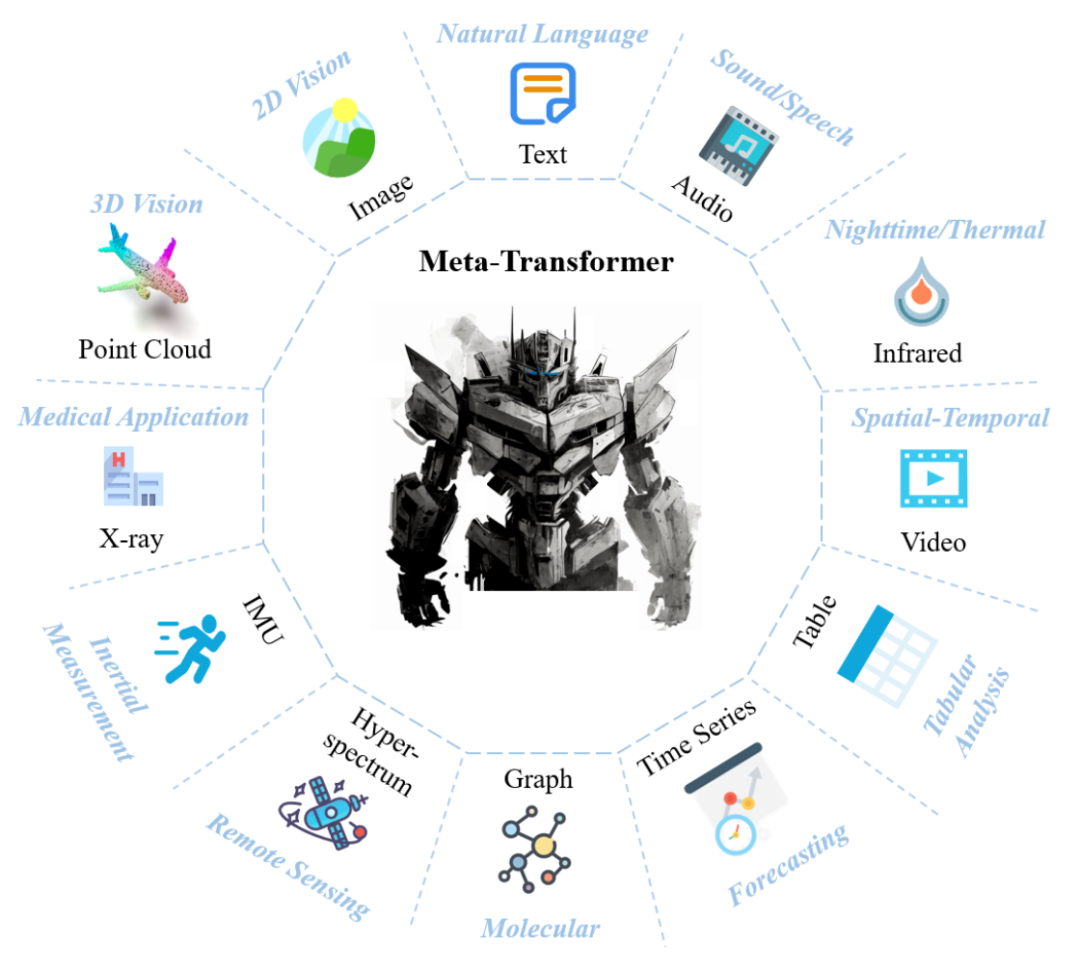
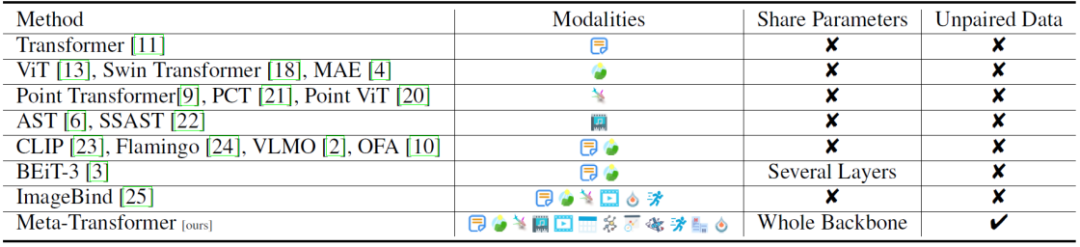

 图 3:Data-to-Sequence 的设计方案能够有效地将不同模态的数据转化为同一个流行嵌入空间内的 token 序列,具有极强的模态拓展性。
图 3:Data-to-Sequence 的设计方案能够有效地将不同模态的数据转化为同一个流行嵌入空间内的 token 序列,具有极强的模态拓展性。
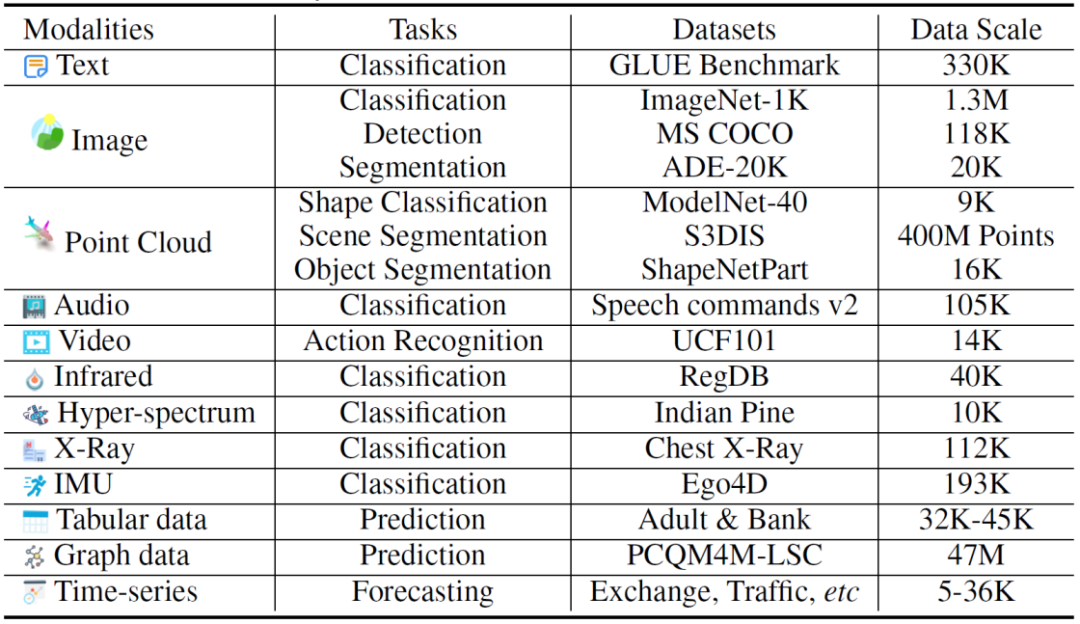
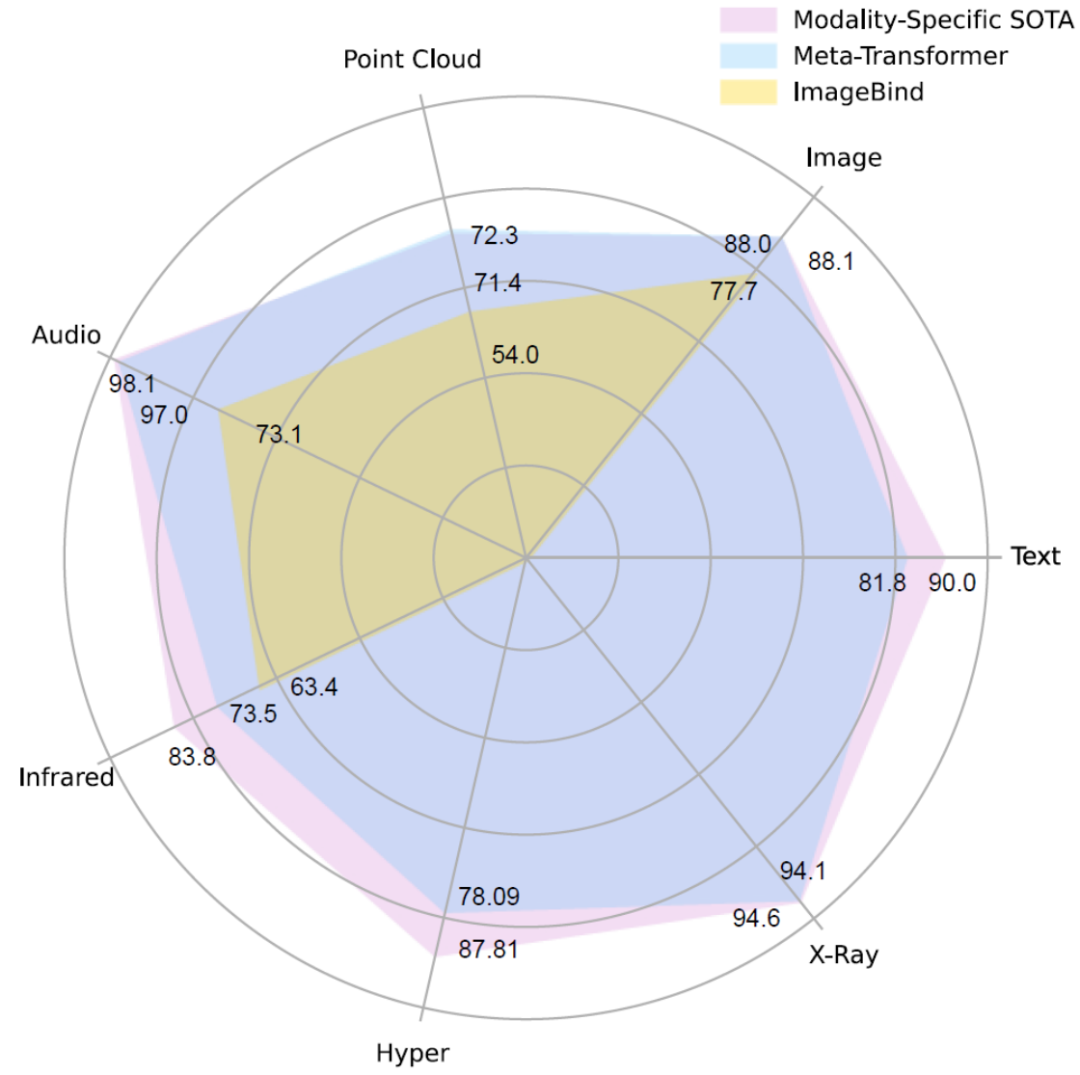
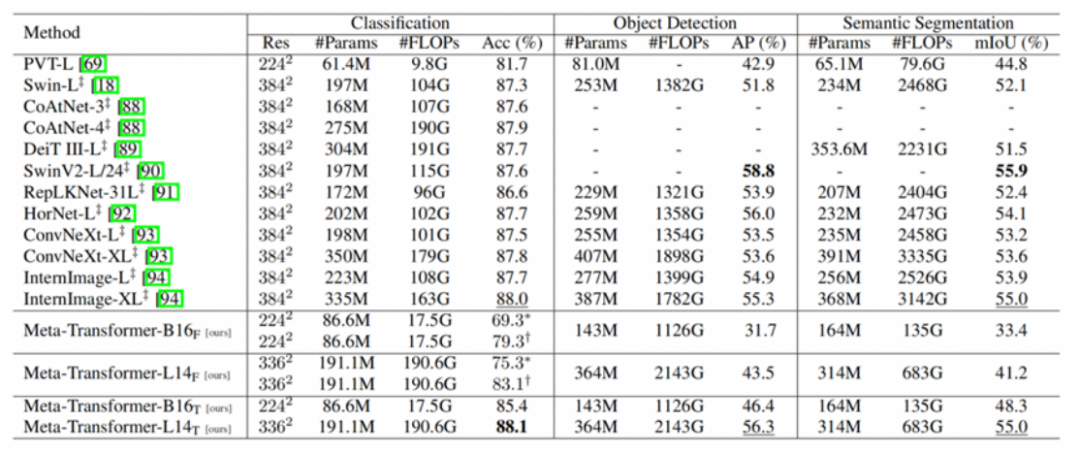
 表 4:Meta-Transformer 对于点云理解方面的能力,分别在 ModelNet-40 形状分类,S3DIS 室内场景分割,以及 ShapeNet Part 物体分割任务上进行了评估。
表 4:Meta-Transformer 对于点云理解方面的能力,分别在 ModelNet-40 形状分类,S3DIS 室内场景分割,以及 ShapeNet Part 物体分割任务上进行了评估。
欢迎大家加入我的这个”AIGC与GPT“知识星球,价格便宜,目前已有100+人
作为一个大厂算法工程师和机器学习技术博主,我希望这个星球可以:
【最全免费资源】免费chatgpt-API,最新AIGC和GPT相关pdf报告和手册。
【最专业算法知识】Transformer、RLHF方法、多模态解读及其论文分享。
【最新变现姿势】如何结合ChatGPT应用落地,各种可以作为副业的AIGC变现方式,打好这个信息差。
【最有趣AICG】ChatGPT+midjourney拍电影,制作壁纸,漫画等等有趣的AICG内 容分享。
另外这里会保存我收集的各种关于AIGC的资源和资料,包括AI绘画-midjourney,ChatGPT, GPT-4,百度-文心一言的各种资料。会保持持续更新,欢迎大家自行拿取。(网盘地址和密码在知识星球自取!)