
漫谈 HTTP 连接
公众号关注“杰哥的IT之旅”,
选择“星标”,重磅干货,第一时间送达!

本文首先会 HTTP 的特点和优缺点,然后会详细介绍 HTTP 长连接和短连接的连接管理,通过阅读本文能够对 HTTP 连接有个深入的认识。
通过前面的 HTTP 系列文章,想必大家已经知道 HTTP 协议的基本知识,了解它的报文结构,请求头、响应头等细节。
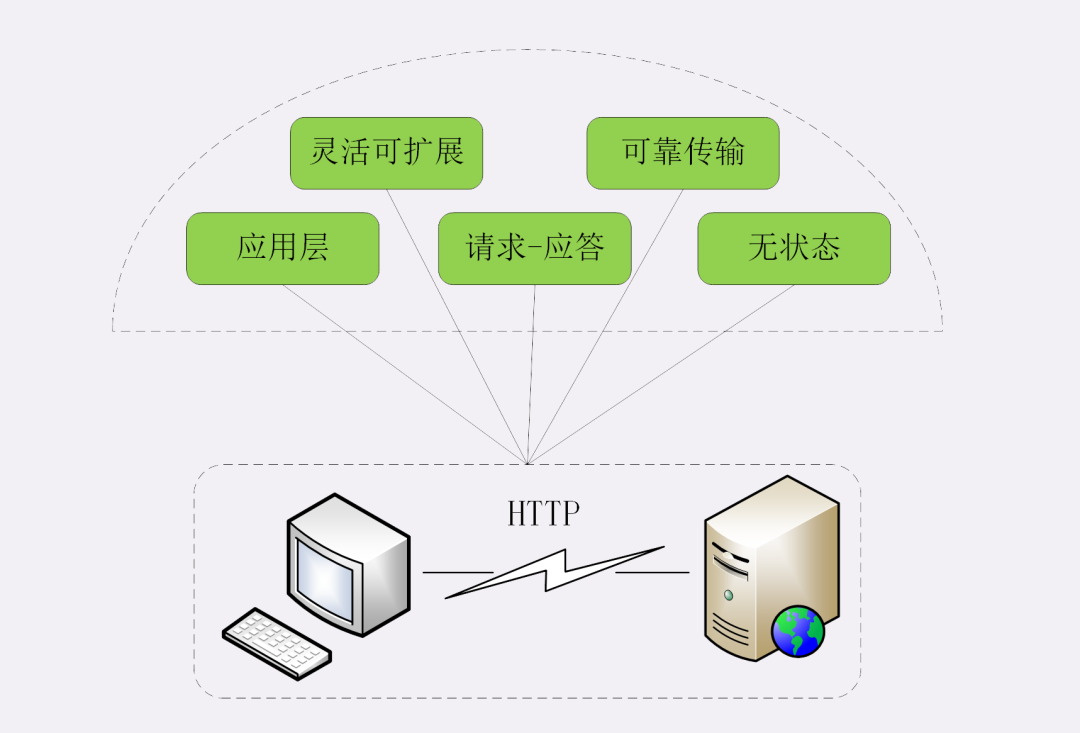
HTTP 的特点
所以接下来先是聊聊 HTTP 协议的特点、优点和缺点。既要看到它好的一面,也要正视它不好的一面,只有全方位、多角度了解 HTTP,才能实现“扬长避短”,更好地利用 HTTP。
灵活可扩展
首先, HTTP 协议是一个“灵活可扩展”的传输协议。
HTTP 协议最初诞生的时候就比较简单,本着开放的精神只规定了报文的基本格式,比如用空格分隔单词,用换行分隔字段,“header+body”等,报文里的各个组成部分都没有做严格的语法语义限制,可以由开发者任意定制。
所以,HTTP 协议就随着互联网的发展一同成长起来了。在这个过程中,HTTP 协议逐渐增加了请求方法、版本号、状态码、头字段等特性。而 body 也不再限于文本形式的 TXT 或 HTML,而是能够传输图片、音频视频等任意数据,这些都是源于它的“灵活可扩展”的特点。
而那些 RFC 文档,实际上也可以理解为是对已有扩展的“承认和标准化”,实现了“从实践中来,到实践中去”的良性循环。
也正是因为这个特点,HTTP 才能在三十年的历史长河中“屹立不倒”,从最初的低速实验网络发展到现在的遍布全球的高速互联网,始终保持着旺盛的生命力。
可靠传输
第二个特点, HTTP 协议是一个“可靠”的传输协议。
这个特点显而易见,因为 HTTP 协议是基于 TCP/IP 的,而 TCP 本身是一个“可靠”的传输协议,所以 HTTP 自然也就继承了这个特性,能够在请求方和应答方之间“可靠”地传输数据。
它的具体做法与 TCP/UDP 差不多,都是对实际传输的数据(entity)做了一层包装,加上一个头,然后调用 Socket API,通过 TCP/IP 协议栈发送或者接收。
不过我们必须正确地理解“可靠”的含义,HTTP 并不能 100% 保证数据一定能够发送到另一端,在网络繁忙、连接质量差等恶劣的环境下,也有可能收发失败。“可靠”只是向使用者提供了一个“承诺”,会在下层用多种手段“尽量”保证数据的完整送达。
当然,如果遇到光纤被意外挖断这样的极端情况,即使是神仙也不能发送成功。所以,“可靠”传输是指在网络基本正常的情况下数据收发必定成功,借用运维里的术语,大概就是“3 个 9”或者“4 个 9”的程度吧。
应用层协议
第三个特点,HTTP 协议是一个应用层的协议。
这个特点也是不言自明的,但却很重要。
在 TCP/IP 诞生后的几十年里,虽然出现了许多的应用层协议,但它们都仅关注很小的应用领域,局限在很少的应用场景。例如 FTP 只能传输文件、SMTP 只能发送邮件、SSH 只能远程登录等,在通用的数据传输方面“完全不能打”。
所以 HTTP 凭借着可携带任意头字段和实体数据的报文结构,以及连接控制、缓存代理等方便易用的特性,一出现就“技压群雄”,迅速成为了应用层里的“明星”协议。只要不太苛求性能,HTTP 几乎可以传递一切东西,满足各种需求,称得上是一个“万能”的协议。
套用一个网上流行的段子,HTTP 完全可以用开玩笑的口吻说:“不要误会,我不是针对 FTP,我是说在座的应用层各位,都是垃圾。”
请求 - 应答
第四个特点,HTTP 协议使用的是请求 - 应答通信模式。
这个请求 - 应答模式是 HTTP 协议最根本的通信模型,通俗来讲就是“一发一收”“有来有去”,就像是写代码时的函数调用,只要填好请求头里的字段,“调用”后就会收到答复。
请求 - 应答模式也明确了 HTTP 协议里通信双方的定位,永远是请求方先发起连接和请求,是主动的,而应答方只有在收到请求后才能答复,是被动的,如果没有请求时不会有任何动作。
当然,请求方和应答方的角色也不是绝对的,在浏览器 - 服务器的场景里,通常服务器都是应答方,但如果将它用作代理连接后端服务器,那么它就可能同时扮演请求方和应答方的角色。
HTTP 的请求 - 应答模式也恰好契合了传统的 C/S(Client/Server)系统架构,请求方作为客户端、应答方作为服务器。所以,随着互联网的发展就出现了 B/S(Browser/Server)架构,用轻量级的浏览器代替笨重的客户端应用,实现零维护的“瘦”客户端,而服务器则摈弃私有通信协议转而使用 HTTP 协议。
此外,请求 - 应答模式也完全符合 RPC(Remote Procedure Call)的工作模式,可以把 HTTP 请求处理封装成远程函数调用,导致了 WebService、RESTful 和 gPRC 等的出现。
无状态
第五个特点,HTTP 协议是无状态的。这个所谓的“状态”应该怎么理解呢?
“状态”其实就是客户端或者服务器里保存的一些数据或者标志,记录了通信过程中的一些变化信息。
你一定知道,TCP 协议是有状态的,一开始处于 CLOSED 状态,连接成功后是 ESTABLISHED 状态,断开连接后是 FIN-WAIT 状态,最后又是 CLOSED 状态。
这些“状态”就需要 TCP 在内部用一些数据结构去维护,可以简单地想象成是个标志量,标记当前所处的状态,例如 0 是 CLOSED,2 是 ESTABLISHED 等等。
再来看 HTTP,那么对比一下 TCP 就看出来了,在整个协议里没有规定任何的“状态”,客户端和服务器永远是处在一种“无知”的状态。建立连接前两者互不知情,每次收发的报文也都是互相独立的,没有任何的联系。收发报文也不会对客户端或服务器产生任何影响,连接后也不会要求保存任何信息。
“无状态”形象地来说就是“没有记忆能力”。比如,浏览器发了一个请求,说“我是小明,请给我 A 文件。”,服务器收到报文后就会检查一下权限,看小明确实可以访问 A 文件,于是把文件发回给浏览器。接着浏览器还想要 B 文件,但服务器不会记录刚才的请求状态,不知道第二个请求和第一个请求是同一个浏览器发来的,所以浏览器必须还得重复一次自己的身份才行:“我是刚才的小明,请再给我 B 文件。”
我们可以再对比一下 UDP 协议,不过它是无连接也无状态的,顺序发包乱序收包,数据包发出去后就不管了,收到后也不会顺序整理。而 HTTP 是有连接无状态,顺序发包顺序收包,按照收发的顺序管理报文。
但不要忘了 HTTP 是“灵活可扩展”的,虽然标准里没有规定“状态”,但完全能够在协议的框架里给它“打个补丁”,增加这个特性。
其他特点
除了以上的五大特点,其实 HTTP 协议还可以列出非常多的特点,例如传输的实体数据可缓存可压缩、可分段获取数据、支持身份认证、支持国际化语言等。但这些并不能算是 HTTP 的基本特点,因为这都是由第一个“灵活可扩展”的特点所衍生出来的。
小结
HTTP 是灵活可扩展的,可以任意添加头字段实现任意功能;
HTTP 是可靠传输协议,基于 TCP/IP 协议“尽量”保证数据的送达;
HTTP 是应用层协议,比 FTP、SSH 等更通用功能更多,能够传输任意数据;
TTP 使用了请求 - 应答模式,客户端主动发起请求,服务器被动回复请求;
HTTP 本质上是无状态的,每个请求都是互相独立、毫无关联的,协议不要求客户端或服务器记录请求相关的信息。
HTTP的连接管理
HTTP 的连接管理也算得上是个“老生常谈”的话题了,你一定曾经听说过“短连接”“长连接”之类的名词,今天让我们一起来把它们弄清楚。
短连接
HTTP 协议最初(0.9/1.0)是个非常简单的协议,通信过程也采用了简单的“请求 - 应答”方式。
它底层的数据传输基于 TCP/IP,每次发送请求前需要先与服务器建立连接,收到响应报文后会立即关闭连接。
因为客户端与服务器的整个连接过程很短暂,不会与服务器保持长时间的连接状态,所以就被称为“短连接”(short-lived connections)。早期的 HTTP 协议也被称为是“无连接”的协议。
短连接的缺点相当严重,因为在 TCP 协议里,建立连接和关闭连接都是非常“昂贵”的操作。TCP 建立连接要有“三次握手”,发送 3 个数据包,需要 1 个 RTT;关闭连接是“四次挥手”,4 个数据包需要 2 个 RTT。
而 HTTP 的一次简单“请求 - 响应”通常只需要 4 个包,如果不算服务器内部的处理时间,最多是 2 个 RTT。这么算下来,浪费的时间就是“3÷5=60%”,有三分之二的时间被浪费掉了,传输效率低得惊人。

单纯地从理论上讲,TCP 协议你可能还不太好理解,我就拿打卡考勤机来做个形象的比喻吧。
假设你的公司买了一台打卡机,放在前台,因为这台机器比较贵,所以专门做了一个保护罩盖着它,公司要求每次上下班打卡时都要先打开盖子,打卡后再盖上盖子。
可是偏偏这个盖子非常牢固,打开关闭要费很大力气,打卡可能只要 1 秒钟,而开关盖子却需要四五秒钟,大部分时间都浪费在了毫无意义的开关盖子操作上了。
可想而知,平常还好说,一到上下班的点在打卡机前就会排起长队,每个人都要重复“开盖 - 打卡 - 关盖”的三个步骤,你说着急不着急。
在这个比喻里,打卡机就相当于服务器,盖子的开关就是 TCP 的连接与关闭,而每个打卡的人就是 HTTP 请求,很显然,短连接的缺点严重制约了服务器的服务能力,导致它无法处理更多的请求。
长连接
针对短连接暴露出的缺点,HTTP 协议就提出了“长连接”的通信方式,也叫“持久连接”(persistent connections)、“连接保活”(keep alive)、“连接复用”(connection reuse)。
其实解决办法也很简单,用的就是“成本均摊”的思路,既然 TCP 的连接和关闭非常耗时间,那么就把这个时间成本由原来的一个“请求 - 应答”均摊到多个“请求 - 应答”上。
这样虽然不能改善 TCP 的连接效率,但基于“分母效应”,每个“请求 - 应答”的无效时间就会降低不少,整体传输效率也就提高了。
这里我画了一个短连接与长连接的对比示意图。
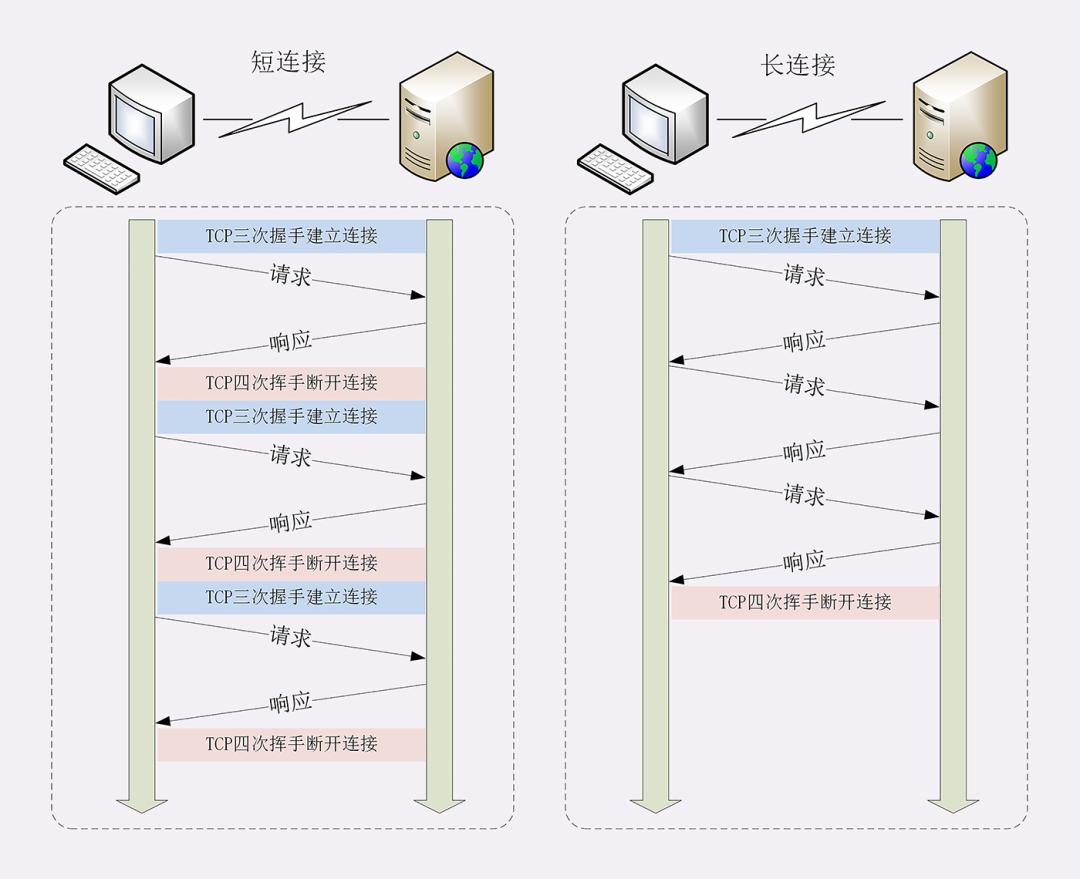
在短连接里发送了三次 HTTP“请求 - 应答”,每次都会浪费 60% 的 RTT 时间。而在长连接的情况下,同样发送三次请求,因为只在第一次时建立连接,在最后一次时关闭连接,所以浪费率就是“3÷9≈33%”,降低了差不多一半的时间损耗。显然,如果在这个长连接上发送的请求越多,分母就越大,利用率也就越高。
继续用刚才的打卡机的比喻,公司也觉得这种反复“开盖 - 打卡 - 关盖”的操作太“反人类”了,于是颁布了新规定,早上打开盖子后就不用关上了,可以自由打卡,到下班后再关上盖子。
这样打卡的效率(即服务能力)就大幅度提升了,原来一次打卡需要五六秒钟,现在只要一秒就可以了,上下班时排长队的景象一去不返,大家都开心。
连接相关的头字段
由于长连接对性能的改善效果非常显著,所以在 HTTP/1.1 中的连接都会默认启用长连接。不需要用什么特殊的头字段指定,只要向服务器发送了第一次请求,后续的请求都会重复利用第一次打开的 TCP 连接,也就是长连接,在这个连接上收发数据。
当然,我们也可以在请求头里明确地要求使用长连接机制,使用的字段是 Connection,值是 “keep-alive”。
不过不管客户端是否显式要求长连接,如果服务器支持长连接,它总会在响应报文里放一个 “Connection: keep-alive” 字段,告诉客户端:“我是支持长连接的,接下来就用这个 TCP 一直收发数据吧”。
不过长连接也有一些小缺点,问题就出在它的“长”字上。
因为 TCP 连接长时间不关闭,服务器必须在内存里保存它的状态,这就占用了服务器的资源。如果有大量的空闲长连接只连不发,就会很快耗尽服务器的资源,导致服务器无法为真正有需要的用户提供服务。
所以,长连接也需要在恰当的时间关闭,不能永远保持与服务器的连接,这在客户端或者服务器都可以做到。
在客户端,可以在请求头里加上“Connection: close”字段,告诉服务器:“这次通信后就关闭连接”。服务器看到这个字段,就知道客户端要主动关闭连接,于是在响应报文里也加上这个字段,发送之后就调用 Socket API 关闭 TCP 连接。
服务器端通常不会主动关闭连接,但也可以使用一些策略。拿 Nginx 来举例,它有两种方式:
使用“keepalive_timeout”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当 Nginx 在这个连接上处理了 1000 个请求后,也会主动断开连接。
另外,客户端和服务器都可以在报文里附加通用头字段“Keep-Alive: timeout=value”,限定长连接的超时时间。但这个字段的约束力并不强,通信的双方可能并不会遵守,所以不太常见。
队头阻塞
看完了短连接和长连接,接下来就要说到著名的“队头阻塞”(Head-of-line blocking,也叫“队首阻塞”)了。
“队头阻塞”与短连接和长连接无关,而是由 HTTP 基本的“请求 - 应答”模型所导致的。
因为 HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求没有轻重缓急的优先级,只有入队的先后顺序,排在最前面的请求被最优先处理。
如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本。
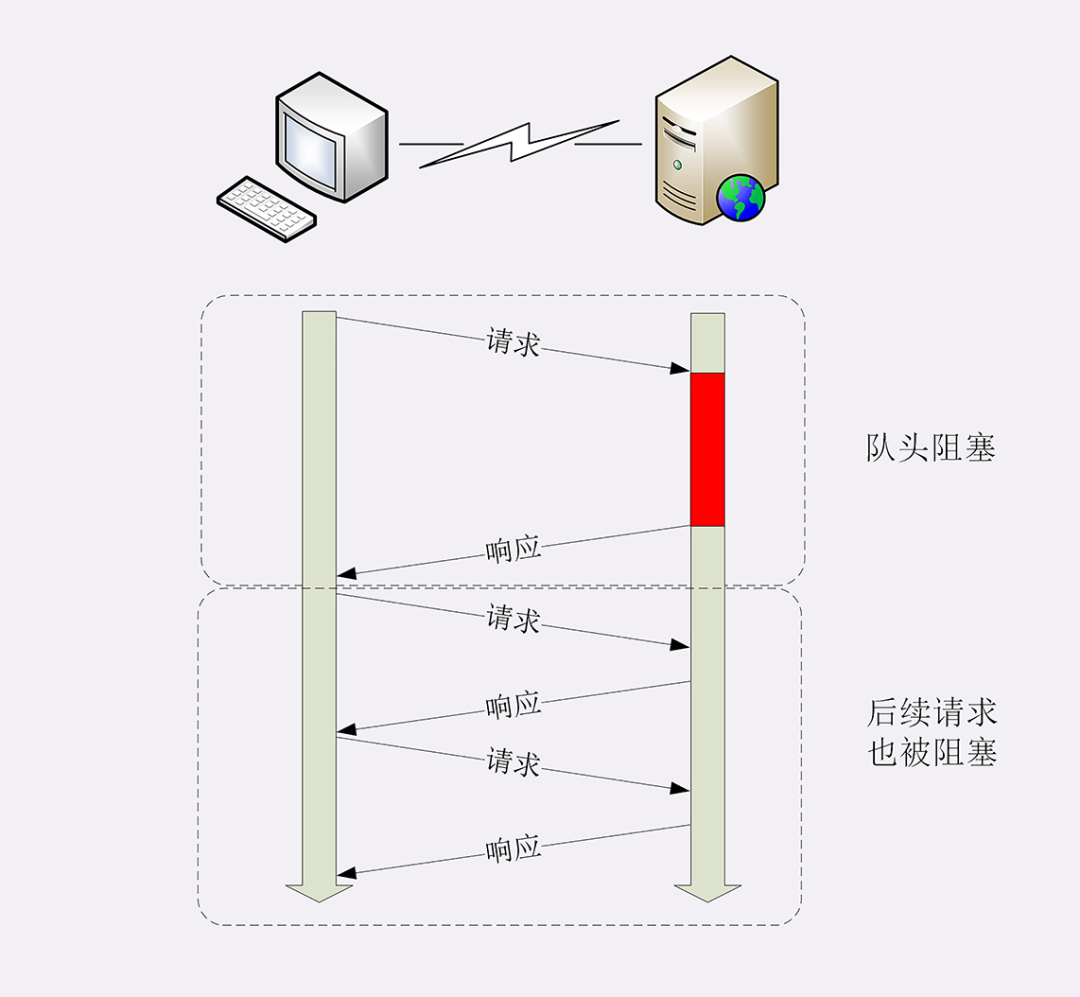
还是用打卡机做个比喻。
上班的时间点上,大家都在排队打卡,可这个时候偏偏最前面的那个人遇到了打卡机故障,怎么也不能打卡成功,急得满头大汗。等找人把打卡机修好,后面排队的所有人全迟到了。
性能优化
因为“请求 - 应答”模型不能变,所以“队头阻塞”问题在 HTTP/1.1 里无法解决,只能缓解,有什么办法呢?
公司里可以再多买几台打卡机放在前台,这样大家可以不用挤在一个队伍里,分散打卡,一个队伍偶尔阻塞也不要紧,可以改换到其他不阻塞的队伍。
这在 HTTP 里就是“并发连接”(concurrent connections),也就是同时对一个域名发起多个长连接,用数量来解决质量的问题。
但这种方式也存在缺陷。如果每个客户端都想自己快,建立很多个连接,用户数×并发数就会是个天文数字。服务器的资源根本就扛不住,或者被服务器认为是恶意攻击,反而会造成“拒绝服务”。
所以,HTTP 协议建议客户端使用并发,但不能“滥用”并发。RFC2616 里明确限制每个客户端最多并发 2 个连接。不过实践证明这个数字实在是太小了,众多浏览器都“无视”标准,把这个上限提高到了 6~8。后来修订的 RFC7230 也就“顺水推舟”,取消了这个“2”的限制。
但“并发连接”所压榨出的性能也跟不上高速发展的互联网无止境的需求,还有什么别的办法吗?
公司发展的太快了,员工越来越多,上下班打卡成了迫在眉睫的大问题。前台空间有限,放不下更多的打卡机了,怎么办?那就多开几个打卡的地方,每个楼层、办公区的入口也放上三四台打卡机,把人进一步分流,不要都往前台挤。
这个就是“域名分片”(domain sharding)技术,还是用数量来解决质量的思路。
HTTP 协议和浏览器不是限制并发连接数量吗?好,那我就多开几个域名,比如 shard1.chrono.com、shard2.chrono.com,而这些域名都指向同一台服务器 www.chrono.com,这样实际长连接的数量就又上去了,真是“美滋滋”。不过实在是有点“上有政策,下有对策”的味道。
小结
这一讲中我们学习了 HTTP 协议里的短连接和长连接,简单小结一下今天的内容:
早期的 HTTP 协议使用短连接,收到响应后就立即关闭连接,效率很低;
HTTP/1.1 默认启用长连接,在一个连接上收发多个请求响应,提高了传输效率;
服务器会发送“Connection: keep-alive”字段表示启用了长连接;
报文头里如果有“Connection: close”就意味着长连接即将关闭;
过多的长连接会占用服务器资源,所以服务器会用一些策略有选择地关闭长连接;
“队头阻塞”问题会导致性能下降,可以用“并发连接”和“域名分片”技术缓解。
原文:https://www.cnblogs.com/huansky/p/14221846.html
推荐阅读
点个[在看],是对杰哥最大的支持!
