
在 Kubernetes 中使用 vGPU 设备插件

vGPU device plugin 基于 NVIDIA 官方插件(NVIDIA/k8s-device-plugin),在保留官方功能的基础上,实现了对物理 GPU 进行切分,并对显存和计算单元进行限制,从而模拟出多张小的 vGPU 卡。在 k8s 集群中,基于这些切分后的 vGPU 进行调度,使不同的容器可以安全的共享同一张物理 GPU,提高 GPU 的利用率。此外,插件还可以对显存做虚拟化处理(使用到的显存可以超过物理上的显存),运行一些超大显存需求的任务,或提高共享的任务数,可参考性能测试报告。
GitHub 地址:https://github.com/4paradigm/k8s-device-plugin
使用场景
显存、计算单元利用率低的情况,如在一张 GPU 卡上运行 10 个 tf-serving。 需要大量小显卡的情况,如教学场景把一张 GPU 提供给多个学生使用、云平台提供小 GPU 实例。 物理显存不足的情况,可以开启虚拟显存,如大 batch、大模型的训练。
性能测试
在测试报告中,我们一共在下面五种场景都执行了 ai-benchmark 测试脚本,并汇总最终结果:
| 测试环境 | 环境描述 |
|---|---|
| Kubernetes version | v1.12.9 |
| Docker version | 18.09.1 |
| GPU Type | Tesla V100 |
| GPU Num | 2 |
| 测试名称 | 测试用例 |
|---|---|
| Nvidia-device-plugin | k8s + nvidia 官方 k8s-device-plugin |
| vGPU-device-plugin | k8s + VGPU k8s-device-plugin,无虚拟显存 |
| vGPU-device-plugin(virtual device memory) | k8s + VGPU k8s-device-plugin,高负载,开启虚拟显存 |
测试内容
| test id | 名称 | 类型 | 参数 |
|---|---|---|---|
| 1.1 | Resnet-V2-50 | inference | batch=50,size=346*346 |
| 1.2 | Resnet-V2-50 | training | batch=20,size=346*346 |
| 2.1 | Resnet-V2-152 | inference | batch=10,size=256*256 |
| 2.2 | Resnet-V2-152 | training | batch=10,size=256*256 |
| 3.1 | VGG-16 | inference | batch=20,size=224*224 |
| 3.2 | VGG-16 | training | batch=2,size=224*224 |
| 4.1 | DeepLab | inference | batch=2,size=512*512 |
| 4.2 | DeepLab | training | batch=1,size=384*384 |
| 5.1 | LSTM | inference | batch=100,size=1024*300 |
| 5.2 | LSTM | training | batch=10,size=1024*300 |
测试结果:
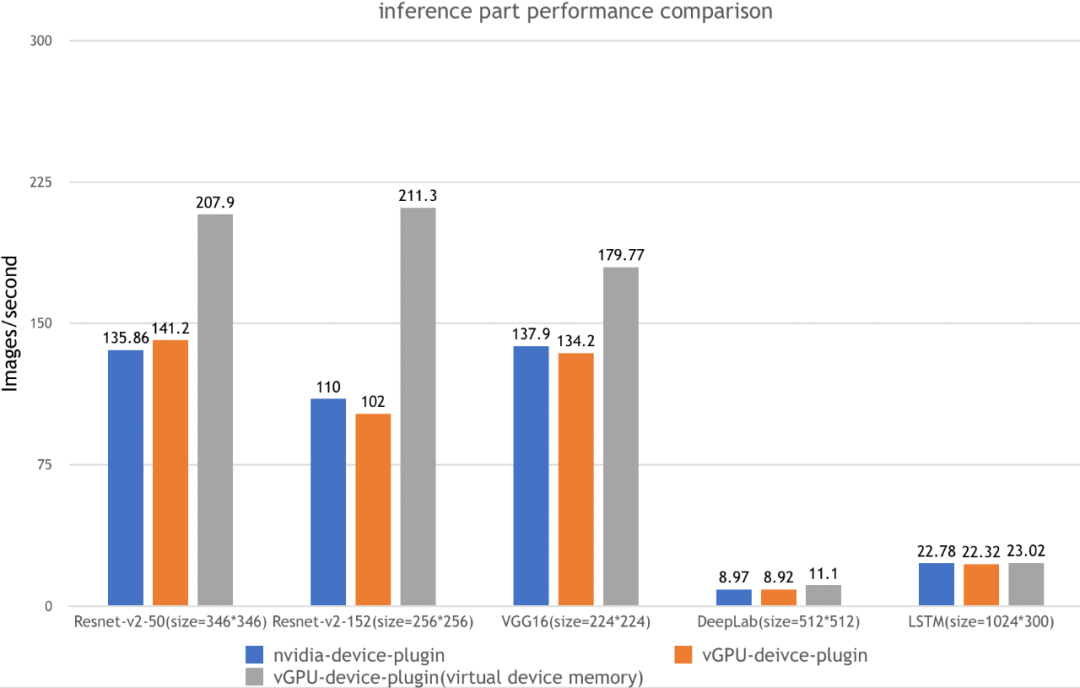
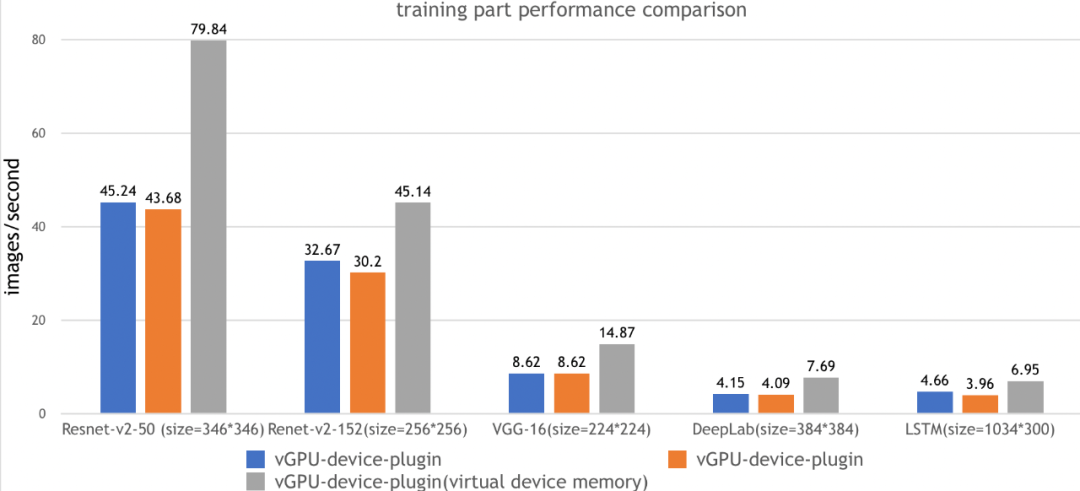
测试步骤:
1、安装 nvidia-device-plugin,并配置相应的参数
2、运行 benchmark 任务
$ kubectl apply -f benchmarks/ai-benchmark/ai-benchmark.yml
3、通过 kubctl logs 查看结果
$ kubectl logs [pod id]
功能
指定每张物理 GPU 切分的 vGPU 的数量 限制 vGPU 的显存 限制 vGPU 的计算单元 对已有程序零改动
实验性功能
虚拟显存
vGPU 的显存总和可以超过 GPU 实际的显存,这时候超过的部分会放到内存里,对性能有一定的影响。
产品限制
分配到节点上任务所需要的 vGPU 数量,不能大于节点实际 GPU 数量
已知问题
开启虚拟显存时,如果某张物理 GPU 的显存已用满,而这张 GPU 上还有空余的 vGPU,此时分配到这些 vGPU 上的任务会失败。 目前仅支持计算任务,不支持视频编解码处理。
开发计划
支持视频编解码处理 支持 Multi-Instance GPUs (MIG)
安装要求
NVIDIA drivers >= 384.81 nvidia-docker version > 2.0 docker 已配置 nvidia 作为默认 runtime Kubernetes version >= 1.10
快速入门
GPU 节点准备
以下步骤要在所有 GPU 节点执行。这份 README 文档假定 GPU 节点已经安装 NVIDIA 驱动和nvidia-docker套件。
注意你需要安装的是nvidia-docker2而非nvidia-container-toolkit。因为新的--gpus选项 kubernetes 尚不支持。安装步骤举例:
# 加入套件仓库
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-docker2
$ sudo systemctl restart docker
你需要在节点上将 nvidia runtime 做为你的 docker runtime 预设值。我们将编辑 docker daemon 的配置文件,此文件通常在/etc/docker/daemon.json路径:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
"default-shm-size": "2G"
}
如果
runtimes字段没有出现, 前往的安装页面执行安装操作 nvidia-docker。
Kubernetes 开启 vGPU 支持
当你在所有 GPU 节点完成前面提到的准备动作,如果 Kubernetes 有已经存在的 NVIDIA 装置插件,需要先将它移除。然后,你能通过下面指令下载我们的 Daemonset yaml 文件:
$ wget https://raw.githubusercontent.com/4paradigm/k8s-device-plugin/master/nvidia-device-plugin.yml
在这个 DaemonSet 文件中, 你能发现nvidia-device-plugin-ctr容器有一共 4 个 vGPU 的客制化参数:
fail-on-init-error:布尔类型, 预设值是 true。当这个参数被设置为 true 时,如果装置插件在初始化过程遇到错误时程序会返回失败,当这个参数被设置为 false 时,遇到错误它会打印信息并且持续阻塞插件。持续阻塞插件能让装置插件即使部署在没有 GPU 的节点(也不应该有 GPU)也不会抛出错误。这样你在部署装置插件在你的集群时就不需要考虑节点是否有 GPU,不会遇到报错的问题。然而,这么做的缺点是如果 GPU 节点的装置插件因为一些原因执行失败,将不容易察觉。现在预设值为当初始化遇到错误时程序返回失败,这个做法应该被所有全新的部署采纳。device-split-count:整数类型,预设值是 2。NVIDIA 装置的分割数。对于一个总共包含N张 NVIDIA GPU 的 Kubernetes 集群,如果我们将device-split-count参数配置为K,这个 Kubernetes 集群将有K * N个可分配的 vGPU 资源。注意,我们不建议将 NVIDIA 1080 ti/NVIDIA 2080 tidevice-split-count参数配置超过 5,将 NVIDIA T4 配置超过 7,将 NVIDIA A100 配置超过 15。device-memory-scaling:浮点数类型,预设值是 1。NVIDIA 装置显存使用比例,可以大于 1(启用虚拟显存,实验功能)。对于有M显存大小的 NVIDIA GPU,如果我们配置device-memory-scaling参数为S,在部署了我们装置插件的 Kubenetes 集群中,这张 GPU 分出的 vGPU 将总共包含S * M显存。每张 vGPU 的显存大小也受device-split-count参数影响。在先前的例子中,如果device-split-count参数配置为K,那每一张 vGPU 最后会取得S * M / K大小的显存。device-cores-scaling:浮点数类型,预设值是 1。NVIDIA 装置算力使用比例,可以大于 1。如果device-cores-scaling参数配置为Sdevice-split-count参数配置为K,那每一张 vGPU 对应的一段时间内 sm 利用率平均上限为S / K。属于同一张物理 GPU 上的所有 vGPU sm 利用率总和不超过 1。enable-legacy-preferred:布尔类型,预设值是 false。对于不支持 PreferredAllocation 的 kublet(<1.19)可以设置为 true,更好的选择合适的 device,开启时,本插件需要有对 pod 的读取权限,可参看 legacy-preferred-nvidia-device-plugin.yml。对于 kubelet >= 1.9 时,建议关闭。
完成这些可选参数的配置后,你能透过下面命令开启 vGPU 的支持:
$ kubectl apply -f nvidia-device-plugin.yml
运行 GPU 任务
NVIDIA vGPUs 现在能透过资源类型nvidia.com/gpu被容器请求:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 2 # 请求2个vGPUs
现在你可以在容器执行nvidia-smi命令,然后比较 vGPU 和实际 GPU 显存大小的不同。
注意:如果你使用插件装置时,如果没有请求 vGPU 资源,那容器所在机器的所有 vGPU 都将暴露给容器。
测试
TensorFlow 1.14.0-1.15.0/2.2.0-2.6.2 torch1.1.0-1.8.0 mxnet 1.4.0 mindspore 1.1.1 xgboost 1.0-1.4 nccl 2.4.8-2.9.9
以上框架均通过测试。
日志
启动日志:在使用 vGPU 功能的 pod 中添加环境变量
LIBCUDA_LOG_LEVEL=5
获取 vGPU 相关的日志:
$ kubectl logs xxx | grep libvgpu.so
反馈和参与
bug、疑惑、修改欢迎提在 Github Issues 想了解更多或者有想法可以参与到 Discussions 和 slack 交流
原文链接:https://www.cnblogs.com/9849aa/p/15037772.html?utm_source=pocket_mylist


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
