
使用 Loki、Kubernetes 和 Golang 在生产环境中进行负载测试

12月26日至2月初这段时间是英国节假日交易活动增加的时期之一,在 loveholidays 这属于高峰期。在高峰期,loveholidays.com 的吞吐量超过平均水平的10倍以上。为了确保我们的服务能够承受负载,我们通过将生产环境访问日志的流量以原吞吐量的倍数重放到我们的 staging 和生产环境来不断测试它们。负载测试会在晚上针对生产环境运行,因为此时英国和爱尔兰的流量较少,我们在晚间针对生产环境执行测试的系统是围绕 Grafana Loki、Kubernetes CronJob 和我们开源的一个名为 ripley 的 HTTP 流量重放工具构建的,我们称这个系统为 Owlbot。
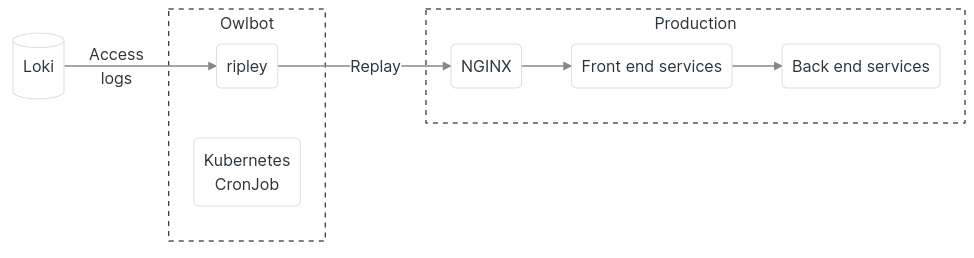
可重放的访问日志
通过使用访问日志重放流量,可以真实地了解请求的分布情况,例如有多少用户点击了主页与搜索结果页面,或者搜索所有目的地的用户与只搜索马略卡岛度假的用户的比例。由于不同类型请求之间的这种分布会影响性能,使用脚本合成负载测试来复制真实流量可能会更加困难。
我们将访问日志与我们所有的服务日志一起存储在 Grafana Loki 中以提高效率,也因为它是 Prometheus/Grafana 生态系统的原生项目,这是我们监控堆栈的一个组成部分,所以我们使用 Loki,而不是其他定制解决方案,这符合我们专注于差异化工程的原则,以及专注于简单性的原则,只需要最小的配置,没有中间系统,例如 GCS,我们在该系统的早期版本上尝试过。
将我们所有的访问日志存储在 Loki 中,还可以捕获到性能下降的时期或导致中断的事件,这样我们就可以重放它们来证明我们的后续改进工作。
我们使用来自 NGINX 的访问日志,这是我们生产集群的入口点,在收集这些日志时,我们会排除一些敏感数据,比如个人身份信息等。
使用 Ripley 重放访问日志
Ripley 是我们编写的一个 Go 工具,灵感来自 Vegeta HTTP 负载测试工具,其他负载测试工具通常以配置的速率生成负载,例如每秒100个请求,这种恒定的负载并不能准确地代表用户行为。默认情况下,ripley 以与生产中发生的请求完全相同的速率进行复制,它还允许以录制速率的倍数进行快速(或慢速)重放,这更接近于自然流量的行为,在 loveholidays.com 的案例中,自然流量通常不是突然爆发的,这种真实的流量模拟对于调整 Kubernetes 的 Horizontal Pod Autoscaler (HPA) 非常有用,我们用它来在吞吐量上升和下降时弹性地扩展我们的服务。
比如一个与 HPA 调整相关的发现示例,在运行期间,我们注意到我们的一项服务难以处理增加的负载,该服务的 HPA 基于 CPU 利用率。在测试期间,随着负载的增加,CPU 的利用率也随之增加,几个新的 Pod 会出现,CPU 利用率会下降,Kubernetes 会关闭 Pod,同样的过程会重复,这样会导致 Pod 会抖动,性能最终会下降,这样我们就需要去调整服务的 scaleUp 和 scaleDown 策略,比如设置 stabilizationWindowSeconds 稳定窗口参数来确保顺利处理流量的波动。
使用 Kubernetes CronJob 编排负载测试
负载测试周期性地针对生产运行,没有人为干预,除非发现了有性能上的问题,在这种情况下,我们的监控系统会通知我们。我们使用 Kubernetes CronJob 来进行编排:
使用 LogCLI 从 Loki 获取访问日志 将访问日志通过管道传输到一个工具中,该工具将它们转换为 Ripley 的 JSON Lines 输入格式 Ripley 针对我们的生产集群重放访问日志
对应的资源清单示例文件如下所示:
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: owlbot
namespace: perf-test
labels:
team: platform-infrastructure
spec:
suspend: false
schedule: "48 02 * * *"
startingDeadlineSeconds: 1800
jobTemplate:
spec:
# 确保我们每次都只尝试一次
backoffLimit: 0
template:
metadata:
labels:
team: platform-infrastructure
spec:
serviceAccountName: owlbot
volumes:
- name: requests
emptyDir: {}
initContainers:
- name: loki-fetch
image: # `logcli` 镜像
command:
- /bin/sh
- -c
- |
/logcli-linux-amd64 query \
--quiet \
--forward \
--limit=24000000 \
--batch=1000 \
--timezone=UTC \
--from="2021-11-14T11:00:00Z" \
--to="2021-11-14T16:30:00Z" \
--output=raw \
# 在这里过滤掉任何不需要被重放的请求
'{job="frontend/nginx"} |= "\"request\":\""' > /load/nginx.jsonl && \
du -sh /load/*
resources: { }
volumeMounts:
- mountPath: /load
name: requests
tolerations:
- key: workload
operator: Equal
value: perf-test
effect: NoSchedule
containers:
- name: owlbot
image: ... # image with `ripley` and tools to convert logs to `ripley`'s input model
resources: {}
command:
- /bin/sh
- -c
- |
# /opt/your/ripley/convert/script /load/requests.jsonl > /load/requests.ripley.jsonl
seq 9999 | xargs -I {} cat /load/requests.ripley.jsonl | /opt/ripley/bin/ripley -pace "1m@1 5m@2 5m@3 5m@4 5m@5 5m@6 5m@7 5m@8 5m@9 5m@10"
volumeMounts:
- mountPath: /load
name: requests
restartPolicy: Never
这些结果由 Prometheus 记录,可以在它或在 Grafana 中直接访问,还有我们正常的应用指标,包括 Tempo 中的 OpenTelemetry 跟踪。
结束语
负载测试对于了解我们的系统处理不同水平的流量的能力方面是非常宝贵的,在一个隔离的 stagng 环境中进行重复测试,可以使测试结果更容易理解,并且不会带来中断实时应用程序的风险。针对生产系统测试是最直接的选择,因为它消除了跨环境的调整需要。在未来,我们还会探索如何能让我们有足够的信心随时针对生产运行负载测试,并将混沌工程引入到我们的流程中来。
原文链接:https://medium.com/loveholidays-tech/load-testing-in-production-with-grafana-loki-kubernetes-and-golang-1699554d2aa3