
【面试题】一文讲清,为啥redis单线程还有很高的性能?
Hollis
共 5800字,需浏览 12分钟
·
2021-09-27 08:01
面试的时候如果聊到缓存,肯定会聊到redis,因为它现在是缓存事实上的标准。
早些年一些互联网公司会用到memcached作为缓存,它是多线程的,用c语言开发,不过现在基本很少了,有兴趣的同学可以学习下它的源码。
那么聊redis,第一个问题就是它的工作原理,redis最最重要的工作原理,就是它的线程模型。
redis是单线程、nio、异步的线程模型,你要是这个都不知道,工作中用到redis,出了问题都不知道如何入手排查。
学习redis线程模型之前,必须了解socket网络编程相关知识,如果你不懂socket,肯定搞不懂redis原理。
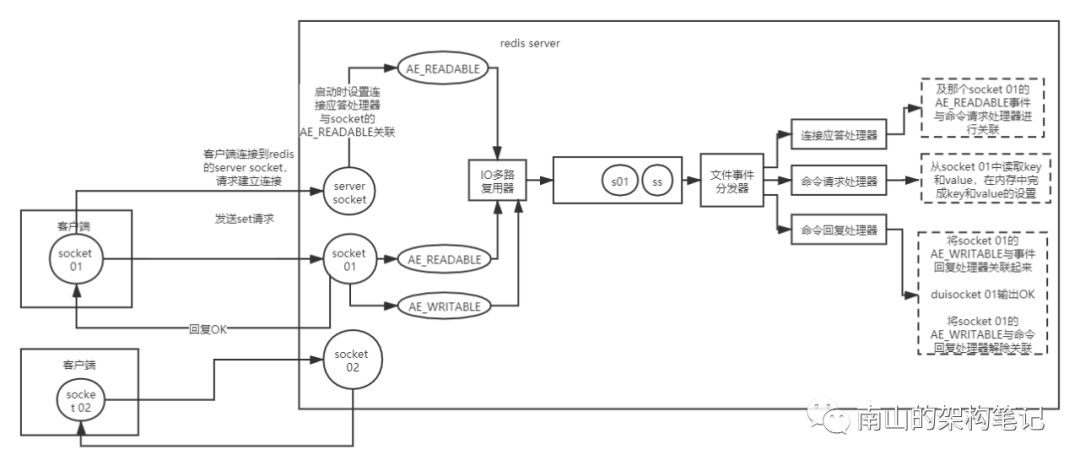
redis使用文件事件处理器(file event handler)处理所有事件,这个文件事件处理器是单线程的,所以redis才叫单线程的。
文件事件处理器采用IO多路复用器,同时监听多个socket,将产生事件的socket放入内存队列中,事件分发器根据socket上的事件类型,选择对应的事件处理器进行处理。
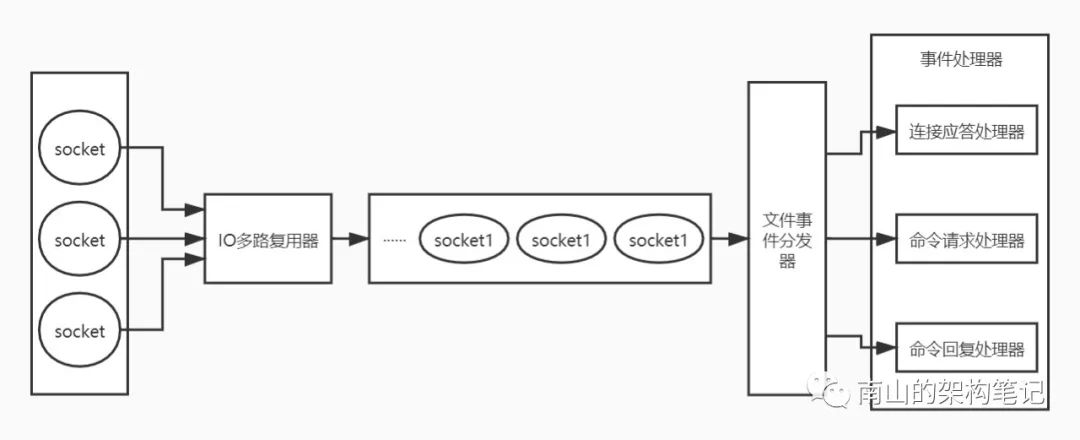
图1 redis 文件事件处理器过程
文件事件处理器的结构包含 4 个部分:
客户端socket IO 多路复用器 文件事件分派器 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
连接应答处理器
在redis server启动的时候,会设置客户端建立连接时的连接应答处理器acceptTcpHandler,并和服务器监听套接字的AE_READABLE 事件关联起来,具体代码在server.c的initServer方法中:
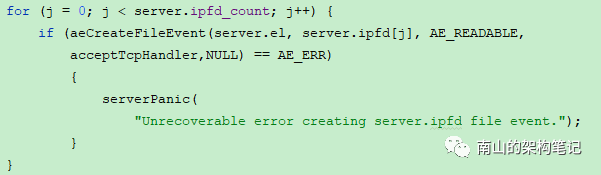
在networking.c 文件中acceptTcpHandler方法实现中,redis的连接应答处理器,用于对连接服务器进行监听,对套接字的客户端进行应答相应。
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {int cport, cfd, max = MAX_ACCEPTS_PER_CALL;char cip[NET_IP_STR_LEN];UNUSED(el);UNUSED(mask);UNUSED(privdata);//循环处理连接应答while(max--) {cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);if (cfd == ANET_ERR) {if (errno != EWOULDBLOCK)serverLog(LL_WARNING,"Accepting client connection: %s", server.neterr);return;}serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);}}
连接应答处理器
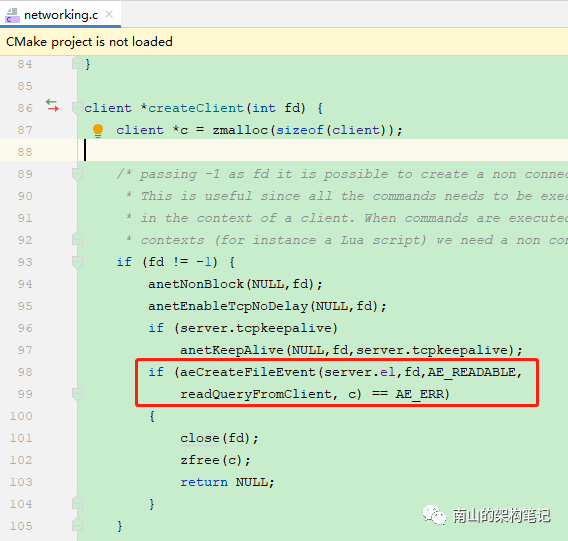
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {client *c = (client*) privdata;int nread, readlen;size_t qblen;UNUSED(el);UNUSED(mask);readlen = PROTO_IOBUF_LEN;/* If this is a multi bulk request, and we are processing a bulk reply* that is large enough, try to maximize the probability that the query* buffer contains exactly the SDS string representing the object, even* at the risk of requiring more read(2) calls. This way the function* processMultiBulkBuffer() can avoid copying buffers to create the* Redis Object representing the argument. */if (c->reqtype == PROTO_REQ_MULTIBULK && c->multibulklen && c->bulklen != -1&& c->bulklen >= PROTO_MBULK_BIG_ARG){ssize_t remaining = (size_t)(c->bulklen+2)-sdslen(c->querybuf);/* Note that the 'remaining' variable may be zero in some edge case,* for example once we resume a blocked client after CLIENT PAUSE. */if (remaining > 0 && remaining < readlen) readlen = remaining;}qblen = sdslen(c->querybuf);if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);nread = read(fd, c->querybuf+qblen, readlen);if (nread == -1) {if (errno == EAGAIN) {return;} else {serverLog(LL_VERBOSE, "Reading from client: %s",strerror(errno));freeClient(c);return;}} else if (nread == 0) {serverLog(LL_VERBOSE, "Client closed connection");freeClient(c);return;} else if (c->flags & CLIENT_MASTER) {/* Append the query buffer to the pending (not applied) buffer* of the master. We'll use this buffer later in order to have a* copy of the string applied by the last command executed. */c->pending_querybuf = sdscatlen(c->pending_querybuf,c->querybuf+qblen,nread);}sdsIncrLen(c->querybuf,nread);c->lastinteraction = server.unixtime;if (c->flags & CLIENT_MASTER) c->read_reploff += nread;server.stat_net_input_bytes += nread;if (sdslen(c->querybuf) > server.client_max_querybuf_len) {sds ci = catClientInfoString(sdsempty(),c), bytes = sdsempty();bytes = sdscatrepr(bytes,c->querybuf,64);serverLog(LL_WARNING,"Closing client that reached max query buffer length: %s (qbuf initial bytes: %s)", ci, bytes);sdsfree(ci);sdsfree(bytes);freeClient(c);return;}/* Time to process the buffer. If the client is a master we need to* compute the difference between the applied offset before and after* processing the buffer, to understand how much of the replication stream* was actually applied to the master state: this quantity, and its* corresponding part of the replication stream, will be propagated to* the sub-slaves and to the replication backlog. */processInputBufferAndReplicate(c);}void processInputBufferAndReplicate(client *c) {if (!(c->flags & CLIENT_MASTER)) {processInputBuffer(c);} else {size_t prev_offset = c->reploff;processInputBuffer(c);size_t applied = c->reploff - prev_offset;if (applied) {replicationFeedSlavesFromMasterStream(server.slaves,c->pending_querybuf, applied);sdsrange(c->pending_querybuf,applied,-1);}}}
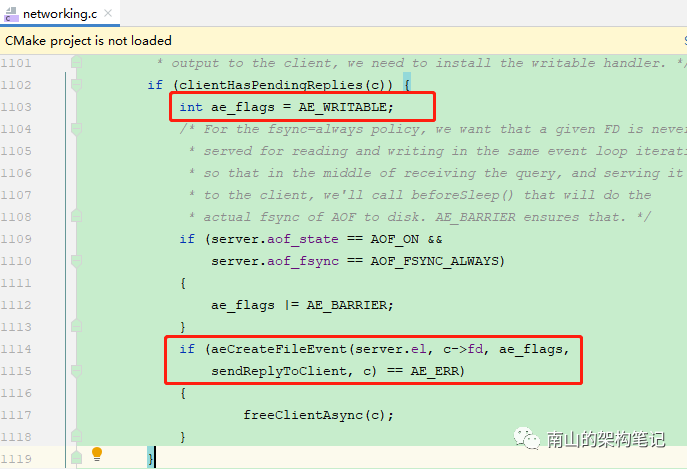
命令回复处理器
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论