
一文梳理深度学习算法演进
涉及语音、图像、nlp、强化学习、隐私保护、艺术创作、目标检测、医疗、压缩序列、推荐排序等方向。文章较长,干货满满。
1. 前言
如果说高德纳的著作奠定了第一代计算机算法,那么传统机器学习则扩展出第二代,而近十年崛起的深度学习则是传统机器学习上进一步发展的第三代算法。深度学习算法的魅力在于它核心逻辑的简单且通用。 在人类历史上,可能没有哪个方向的技术能在如此短的时间内吸引如此多的人投入其中,也没有哪个技术在如此短的时间被应用在如此多的场景。深度学习算法这过去6年可能说不上产生了多么重大的突破,但是产量绝对是惊人的,也给我们带来了许多意想不到的惊喜。 回顾2015年到2021年,个人期间有幸参与了语音、视觉、NLP和推荐排序等几个领域。其中一部分是以直接算法应用研究角度,还有一部分是从框架系统支撑视角。部分工作是算法预研,还有部分成果应用在语音搜索,医疗影像,推荐系统等业务。 这篇文章更多是结合自己实践经历,通过一些业界经典成果回顾了过去6年在深度学习算法方向上的技术迭代。最后做了一些归纳总结和展望。
2. 语音识别
语音识别任务通常是将人的讲话转换成文字的能力。这个能力在Google Voice Search, iPhone Siri助手等多个领域都有重要的应用。 语音识别技术的研究从几十年前就已经开始,然而深度学习技术普及之前,离普遍产品应用还有不少的距离,错词率(WER)一直都比较高。即使在低噪音的环境下,通常至少在10%以上。 传统的语音识别通常是多阶段的复杂工程:
先对语音做一系列信号处理,转换成中间格式,比如filter-bank。 然后还会经过提取phoneme(音素)的阶段。 再经过一些语言模型,路径搜索,词表等复杂流程。 最后产生文字结果。
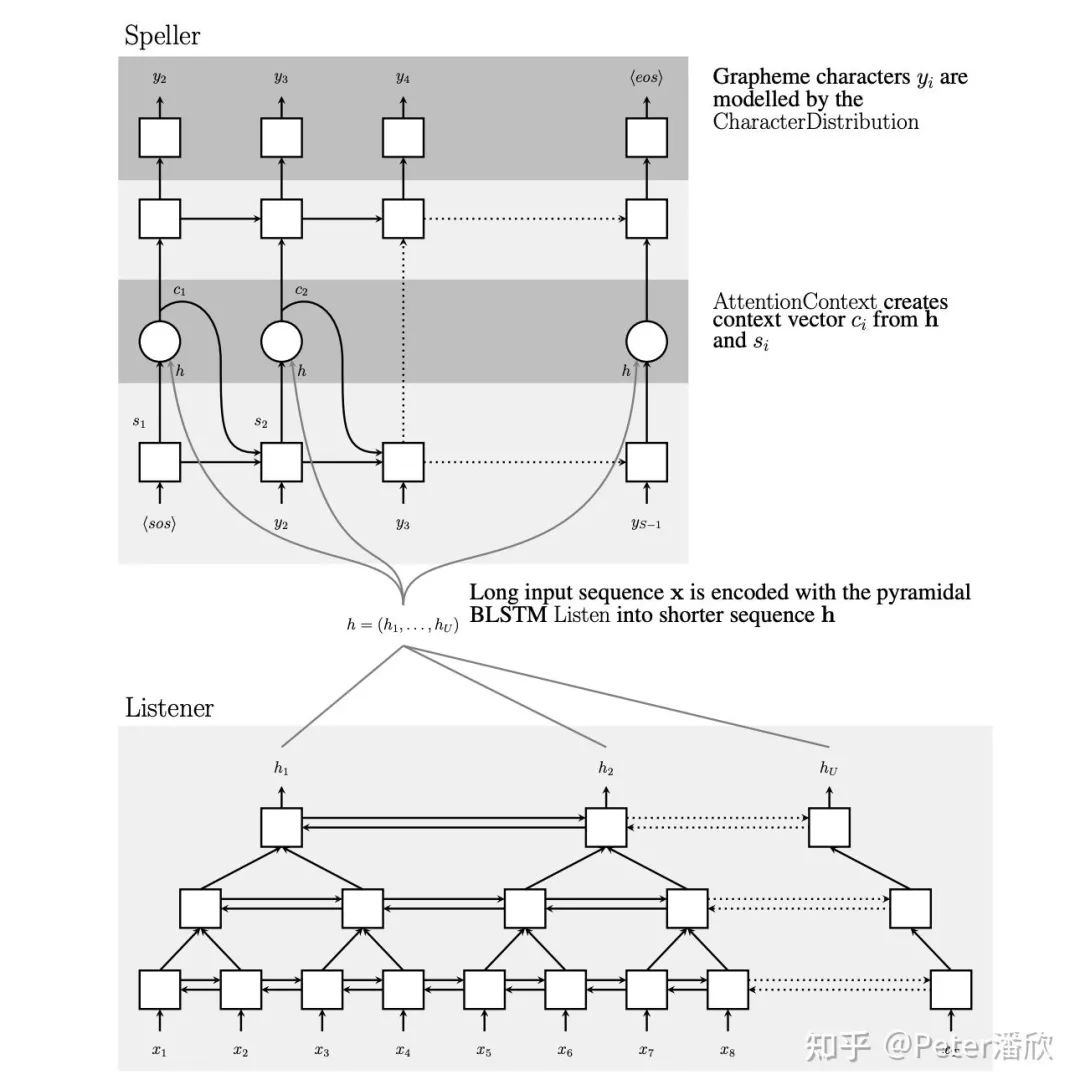
大概15年底到16年初的时候,我做了一个项目是帮谷歌voice search在tensorflow上实现Listen, Attend and Spell(LAS)这个论文的工作。LAS的工作是Google Brain的实习生William15年在上一代框架DistBelif上完成的,在当时相比传统方案是个不小的进步,它让语音识别从一个多阶段的算法和系统工程,变成了端到端几百行python代码的问题。 具体可以大致总结在几个方面:
端到端语音识别。相比传统多阶段方法,这个模型使用filter-bank spectra作为输入,通过seq2eq with attention的结构直接输出了语言文字。在没有附加外部语言模型的情况下就达到了14%的WER。附加语言模型达到10%的WER。 在当时的K40 GPU算力下,这个模型的复杂度是非常高的。其中多层bi-lstm encoder在序列比较长的时候几乎训不动。为了解决这个问题,采用了金字塔结构的encoder,逐层降低序列长度。 attention机制帮助decoder能够提取encoder sequence重要信息,显著提升解码的效果。同时decoder内部隐式学习了语言模型。
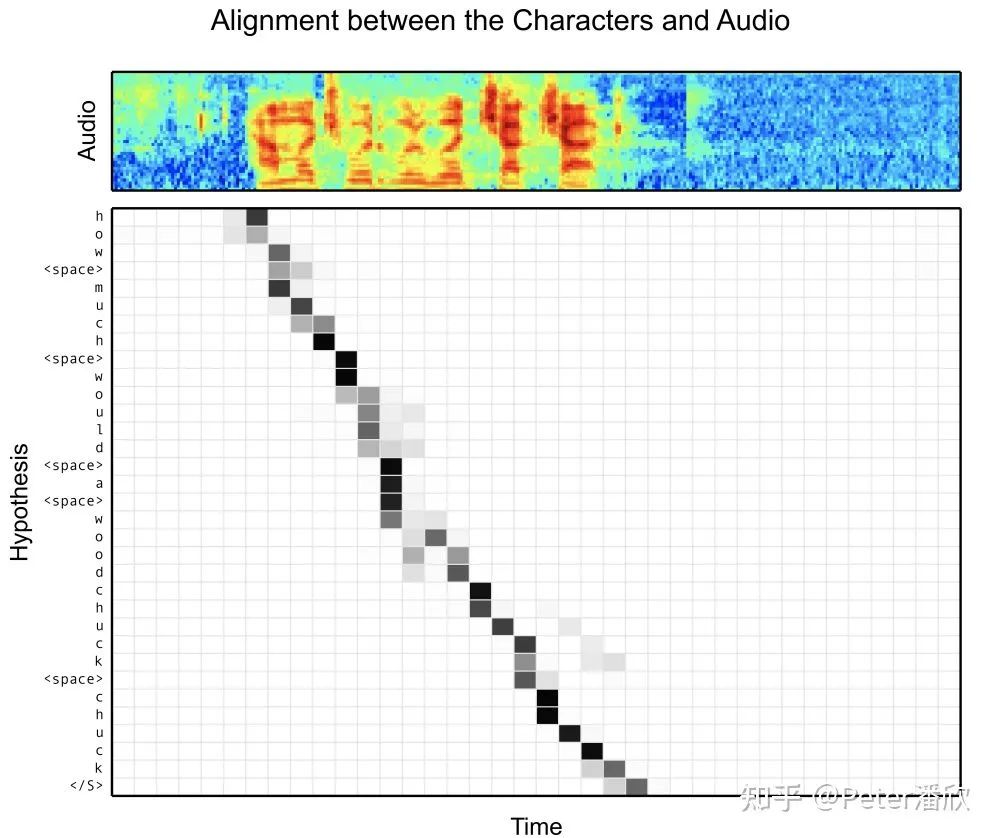
当时顺便开发了个debug工具,能抽样听某个voice search的录音,对比识别的文字结果。从实际情况抽样,这个模型已经超过一般人的水平。模型能并识别大量地名,物品名,型号名,比如galaxy s5。 模型训练速度在当时还是比较慢的。为了完成voice search数据的训练收敛,动用了128个GPU,训练了将近2个月。为了多组实验并行,常常一口气跑到500~1000个GPU。那会还是以GPU worker+PS的异步训练为主。很多人觉得异步训练会影响模型的收敛效果,也有人觉得异步训练能跳出一些局部鞍点。
从当时实验上看,精心调参的异步训练最终的确会超过同步训练实验。其中一个原因可能是当时同步训练在当时硬件设备和软件框架上太慢了,很难完成有效的迭代。从18年以后的经验看,同步训练的效果和异步训练的效果基本能不相上下,在某些场景同步训练的效果甚至更好(可能大batch size对于稀疏特征场景这种样本分布不稳定的问题有一定的缓解) 百度的DeepSpeech当时也非常优秀,影响更深远的是当时百度主推了HPC的训练模式,发扬了同步训练的Ring AllReduce。现在回过头看,百度似乎是对的。TF可能是受早年MapReduce基于commodity machine的分布式思路影响比较深。当然后面的TPU也回到了HPC的轨道上。
3. 图像识别
15~16年的ResNet算得上是比较突破性的工作了,从它超过10万的论文引用量就能看出来。ResNet之前是VGG,AlexNet等统治世界,那时候模型还比较浅,和ResNet相比只算得上是“浅度学习” :-)。16年初的时候,谷歌内部还没有ResNet的TensorFlow实现(当时内部用Inception比较多)。我于是基于TensorFlow写个ResNet出来给大家用。
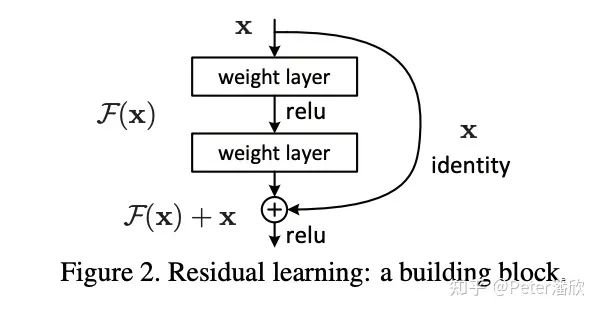
ResNet的突破性在于基于相似结构(Residual Block)的重复堆叠,并通过Residual Connection将这些Blocks联起来,实现非常深的模型训练。Residual Connection之前,很深的网络训练会有比较明显梯度暴涨和衰减的问题。记得早年Hinton老爷子训练多层模型是训完一层再加一层,效率会比较低。基于ResNet的结构,模型可以轻易的加到1001层。个人觉得,深度学习在ResNet之后才成为真正的”深度“学习。BatchNorm相信每个搞深度学习的都非常熟悉,这也是ResNet的核心模块。时间回到16年初,我发现谷歌内部竟然没能找到一个TensorFlow正确实现的BatchNorm。有少量错误的实现版本的确在被使用,但是好像并没有被察觉。有个笑话说的是你可能分不清一些深度学习模型结构到底是bug还是feature,修复了“bug”反而导致模型的效果下降。 当时TensorFlow写个BatchNorm还需要通过加减乘除来拼接。我碰到一个神奇的问题就是ResNet加到1001层后会发生诡异的数值错误,通常是NaN。记得仔细Debug后,好像是参数有个moving average的默认值0.999...后面的9的个数是有讲究的。 后来我把早期完全没有性能优化(那会还没有FuseBatchNorm)的ResNet放到tensorflow model zoo github上开源了。AWS和一些机构没有调优就拿过去做了一些benchmark,得出tensorflow性能远差于其他框架的结论。TensorFlow的老板们表示非常不满,于是tensorflow 1.0版发布专门搞了个官方优化的性能benchmark。
4. 语言模型和文本归纳
语言模型可以说是NLP领域的核心基础算法。16年的语言模型还没有现在的BERT如此强大。当时还有不少的流派,比较传统的是Ngram模型,基于全网数据训练一个数百GB的Ngram模型在公司有广泛应用。 然而新的挑战者已经在路上了。当时深度学习的当红是LSTM和它的兄弟们,比如Bi-LSTM。不过当时LSTM在TensorFlow上的速度真是一言难尽,实际生产都会退而求其次选择GRU。后来英伟达搞了个cudnnLSTM,才算有了比较显著的进步。 我做语音模型时需要训练一个domain specific的语言模型,和搜索部门转岗过来的大哥在这块有些合作。当时他结合搜索业务场景,搞了个byte-level语言模型,词表只有256个,目标是预测下一byte,这个模型厉害之处除了非常精小,而且语言无关,可以同时预测混合中英文和数字的文本。上线到搜索词补全上,取得了不错的业务收益。 文本归纳人机对比示例:

后来16年我参与了一个Moonshot项目是做自动文本归纳。模型结构基本是复用了前文说道的语音识别的模型seq2seq+attention。数据是dailynews等,使用正文作为输入,标题作为样本,经过了加深和加宽的暴力训练,很轻松的就超过了当时的SOTA。细心的读者会发现,其实各个不同领域,比如语音、文本,的模型结构的统一趋势在这个时候已经比较明显了。
实际Debug分析时,我们发现文本归纳模型对于股市类新闻的归纳非常的精准。但是在许多复杂场景还是有比较严重的缺陷的。比如某个警匪案件中,A发现B的兄弟C谋害了D,模型很容易就会错误归纳成B谋害了D,或者D谋害了C。 当时模型的优化目标是F1 Score,简单的说就是比较样本和预测之间字词是否一样。这显然是有缺陷的,每篇文章都有很多不同的归纳方法。 当时有个研究员建议我先基于海量数据预训练语言模型,然后再用dailynews fine tune这个文本归纳模型。放到今天这是个不言而喻的常规操作,然而当时我却因为其他事务没有尝试。
5. 深度强化学习与AlphaGo和AutoML
深度强化学习大概是16~17年迎来了一个小高潮,原因是AlphaGo战胜了人类世界冠军,紧接着又迭代了AphaGo Zero和AphaZero两版,俗称AlphaGo三部曲。当时Brain请DeepMind的同事过来做了些分享,对我的震撼还是挺大的,强化学习跟动物的自然学习方式太像了。
简单回顾一下AlphaGo系列三部曲:
AlphaGo先从人类走棋数据集上学习policy network。监督数据就是基于当前棋局s,预测人类行为a。 初步学习后,AlphaGo再和自己玩,用RL的policy gradient进一步优化policy network,提升行为准确性。 然后用policy network生成很对局数据,数据用来训练value network。value network简单来说就是预判当前局势的胜率。
上面说的的是训练过程。其中蒙特卡洛搜索树MCTS是这个训练过程中重要数据结构,这就不展开说了。在推理过程(线上比赛):
AlphaGo会基于MCTS去探索子树(类似人类心中演绎棋局不同走势。演绎多长,越接近结局,预判越准)。其中探索过程会基于前面说的policy network和value network。还会用一个小policy network快速走棋到结束得到一个大概结果。 基于子树的探索,AphaGo就能够进一步加强对于不同行动的判断准确性,进而采取更优的决策。
上面讲的比较简略了,感兴趣的可以去阅读原文。AlphaGo Zero去掉了“基于人类对战数据监督”的过程,完全是自己和自己玩来提高。AlphaZero则将这个算法框架通用化到了多个棋类游戏,比如chess等。 其实强化学习早就有了,其基础理论可以追溯到动态规划,马尔科夫链和图灵状态机。当它和深度学习融合后效果就产生了巨大的进步(Oracle Turing Machine中的“Oracle”)。21年AlphaGo系列的作者写了篇文章叫Reward Is Enough,谈到强化学习更大的可能性,感兴趣读者可以看看。这里回顾下前几年发生了那些事。大概16~17年的时候,Brain有两位实习生分别利用强化学习干了两件事:
其中一个用强化学习去发现更好的gpu device placement,让机器翻译模型能有更好的GPU分布式训练速度。 另一个用它去搜索模型结构,也就是那篇Neural Architecture Search (NAS)。它发现了更好的训练imagenet的backbone,效果要超过SOTA的ResNet等模型。这个技术后来被逐渐泛化成了AutoML。
6. 隐私保护Differential Privacy
人脸识别技术是相对发展比较快和成熟比较早的。有论文发现可以从模型中逆向还原训练数据中的人脸图片。如何保护训练数据的隐私成了一个比较重要的问题。 当时做的其实也比较简单。在一个研究员指导下,我Hack了一些TensorFlow Optimizer,在gradient中注入了一定比例的高斯噪声。根据噪声的设置,对与最终模型的效果有一定的影响。研究员基于一些复杂的公式能够量化privacy泄露上界。
7. 深度学习的艺术创作



深度学习的模型训练和预测往往不只有predict target。灵活的控制feature extractor和gradient propagation,可以玩出许多花样来。比如在Adversarial Training中对抗恶意样本攻击,或者在Neural Style Transfer中修改原图的样式。16年参与到了Nerual Style Transfer的一个模型的实现,它可以将一个艺术图片的“艺术”(可能叫纹理比较好)快速的加入到另一张普通图片中,让普通图片获得“艺术”。总体原理如下:
使用预训练VGG模型某些中间层的输出作为feature extractors。 其中一些feature extractors的输出叫做content feature,另一些层的feature extractors输出经过gram matrix计算后的值叫做style feature。用VGG分别算出来原始图片(上图中的狗)的content feature,和style图片(上图中的艺术图片)的style feature。 loss = content loss + style loss。content loss是当前content feature和上一步中保存的原始图片content feature的差。用来保障图片还有原来狗的轮廓。而style loss是狗狗照片style值和艺术图片style值的差。让狗狗照片的style越来越接近艺术图片。 两个loss互相平衡,让vgg feature extractors既能够保留原图像的轮廓,同时还能添加出style。但是原狗狗图片和艺术照图片的style显然不一样,所以开始时style loss会比较大。怎么办? 解法就是将loss反向求出的gradient叠加到原始图片上。满足style loss变小的目的。经过几轮的image=image叠加gradient,原始图片image会既有狗的轮廓(content loss),已有艺术图片的style(降低style loss)。
这个能力看似只能娱乐,但是再Adobe看来却是块宝贝。高度可控的Neural Style修改技术可以极大的提高大家的PS效率。记得当年在旧金山还办过几个AI艺术展。 既然聊到这,不得不提一下GAN,GAN的作用现在看来是非常重要。当年也曾经一度冲到CVPR的最热门Topic。各种花式GAN变种如雨后春笋般出现,而GAN模型的效果却不像图片分类一下好PK。后来好像有篇论文分析了10个不同的GAN算法,发现他们之间的效果没有显著差异。
8. 目标检测和分割
8.1 Youtube BoundingBox
横跨16到17年,很大一部分工作都在目标检测(Object Detection)和分割(Segmentation)上。最开始是Youtube和Brain团队一块想搞个世界上最大的目标检测数据集。 然而预料之外的是这个项目花了很多时间在数据标注上,先是开发了个简单的数据标注网站,然后后期经费竟然不够用了。。。为什么会不够用?从下面这张图示例就能看出来。如果标注按框框算钱,这一群斑马就像是燃烧的经费。

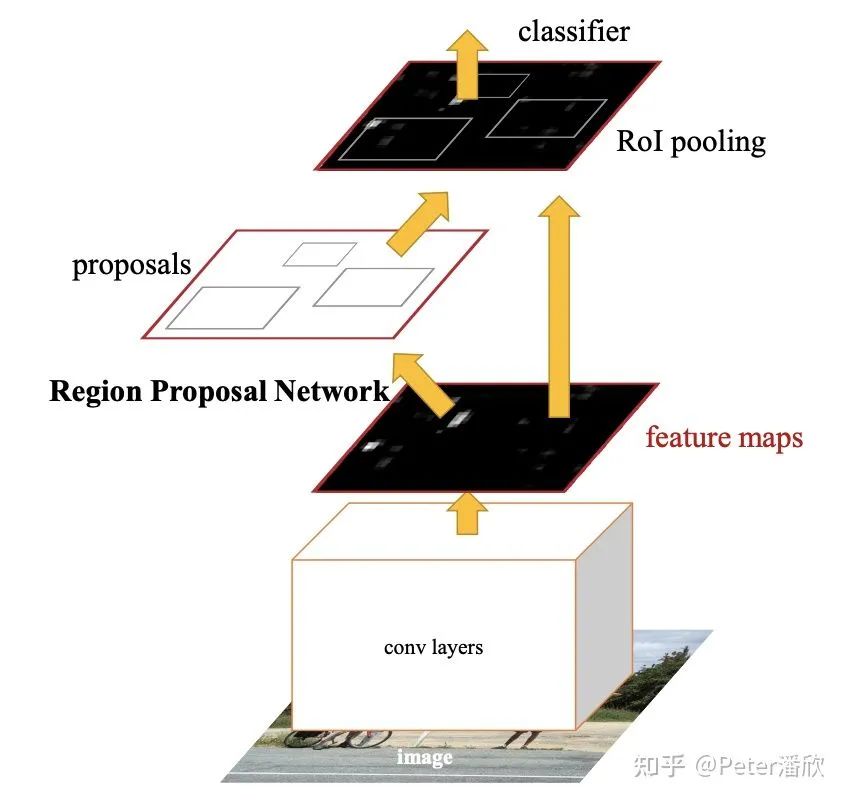
后来我们做了个艰难的决定,对于这种情况,一个图片只标注其中一匹斑马。我这边负责实现一个目标检测模型,评估一下SOTA模型在这个数据集上的效果。当时有两个选择,SSD和Faster-RCNN。SSD的实现要简单不少,但是当时效果比不过FasterRCNN,于是决定实现FasterRCNN。FasterRCNN大致结构如下:
底座通常是个基于图片分类模型预训练的feature extractor,比如ResNet50。 接着是在feature map上找box。通常是每个位置上有多个不同预制大小规格的box。 同时还要对每个box进行分类。
虽然说起来逻辑不复杂。实现过程还是差点翻车。当时我搞了挺久也没能完全复现CoCo数据集的结果。这里面的loss设计、hard negative mining等都有不少的trick。比较幸运的是Research部门有另一个团队的几个人也在复现FasterRCNN,于是我借鉴了比较多他们的工作。 从实践来看,即使数据集中仅标注了多个同类物体中的某一个,在预测集上,该模型依然能够在某个图片进行多个同类物体的圈选。
8.2 GoogleMap Segmentation
如果目标检测只是大致框出图片中的物体,分割(Segmentation)则是要清晰精确的切割出物体的轮廓(据说这个领域目前已经卷到去切割头发丝和牙齿的轮廓了)。17年GoogleMap找我们预研切割卫星视图下的房屋的轮廓,据说是要为无人机投递快递做准备,防止投递到马路或者屋顶上。Segmentation领域传统的Semantic Segmentation结构相对比较简单,比如UNet等,已经能取得不错的效果。后来Mask-RCNN出来能够在一个模型中同时学习分割和检测,这样能够进一步提升分割的效果(IOU)。 当时我们做到的效果基本已经接近人的水平了。但是有很多难样本还是不好解决。比如有些屋顶被大树遮盖后和草地颜色非常相近。或者是一些特殊厂房屋顶轮廓和颜色都比较特殊。模型还是偶尔会做出错误的分割。
8.3 医疗影像的应用
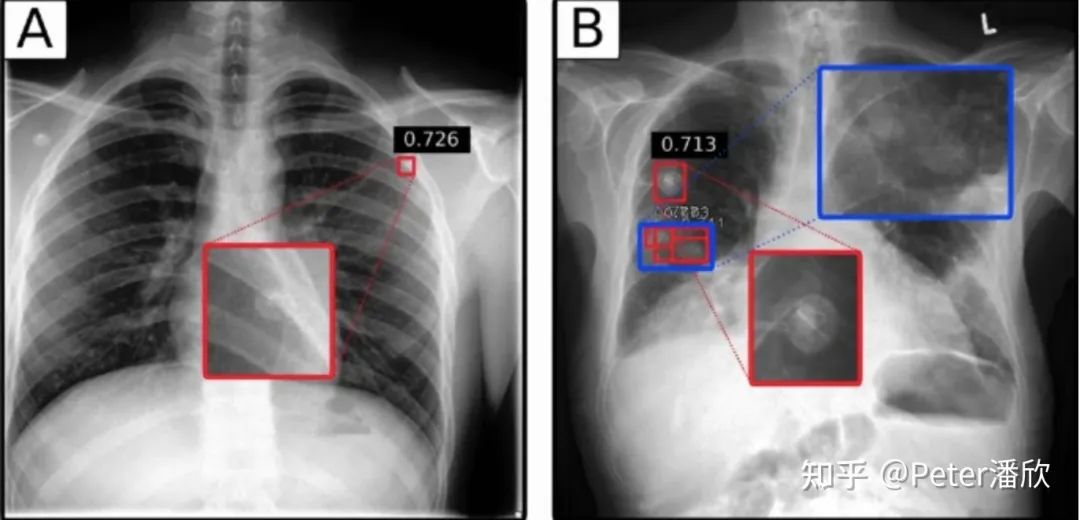
17年Brain下成立一个放射科的医疗影像团队:Radiology。由于我正好在这个领域开发模型,就帮助了这个团队的创建。 最初我们先从简单的XRay下手。我将FasterRCNN先经过CoCo的预训练,然后再几百张XRay样本上做了一些fine-tune,结果意外的好。 后来我们深入到更难的CT场景。CT是对人进行3维立体的扫描,因此对应的框需要包含长宽高。由于当时是兼岗,我简单将CT做了抽帧,转换成多张二维图片,然后通过FasterRCNN,然后再三维化。这样效果比较一般。后来一个韩国小哥实现了一个高性能的3D检测,取得了更好的效果。 花絮 AI医疗的上线是非常困难的,特别是在美国这种FDA管理比较严格的国家。当时我们找到一个场景,据说是不需要FDA Apporve的: 通常需要被诊断的Radiology数据是FIFO排队被医生诊断的。这就有个问题,有可能某个人的情况很紧急(比如车祸胸部骨折),但是他的XRay被排在了后面,耽误了诊断。我们可以用AI模型对这些XRAY做一个严重程度的排序,给医生提出建议。另外,我们还在印度搞了流动医疗车,免费提供相关的诊断。
9. 看见未来Frame Prediction
Self-Driving Car和Brain有个合作,要预测无人车在未来的一段时间能看到的场景。研究员建议我使用Variational AutoEncoder,将一系列历史Frame序列输入到模型中,进过Encoder,构造出未来一段时间将会出现的画面。通过调整随机输入,可以让模型预测多种不同的结果。 这个模型的训练模式和语言模型比较类似。只要汽车一直采集视频,模型就用最后一帧的图片监督模型对这一帧的预测,无需人工标注就可以产生源源不断的监督信号。

10. 序列的崛起Transformer,BERT
个人认为17年之前,卷积网络和CV进展几乎占据了深度学习领域重要成果的大部分,模型效果显著超过人的水平,大量被应用在生活中。而NLP的进展在17年之前,相比之下就显得慢一些。虽然机器翻译等有了不少进步,但是LSTM和GRU无法建模长序列,性能开销大,难以并行计算的问题一直制约NLP和序列相关问题的进展。同时我们发现LSTM也不像Conv那样容易进行多层堆叠。
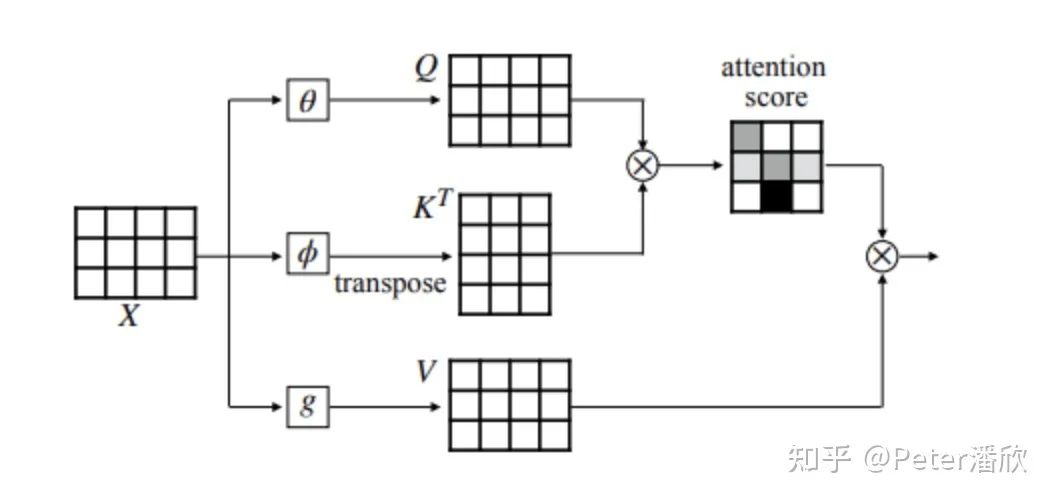
Transformer是深度学习兴起以来NLP翻身仗的开端,甚至有Transformer Everywhere的大一统趋势。为之后的BERT, 大规模预训练模型打开了一个关键突破口。Transformer开始流行的18年,我大部分时间都投入到Paddle框架的开发中,对于算法的关注相对比较少。不过Transformer从一开始就是我们重点优化性能的benchmark模型。先是优化Transformer单GPU的训练性能,然后是多GPU的训练性能。当时我们还分析了对于一个O(n)的序列,Transformer和LSTM的时间复杂度。然而Transformer的关键优势在于它可以并行的处理整个序列,而LSTM需要一个Recurrent的过程,从一头往另一头逐个处理。在GPU这种设备下,Transformer的性能优势会非常明显。
10.1 Self-Supervise和大模型
Transformer方兴未艾,18年以后紧接着BERT,GPT-3也火了。数据集和模型变得一个比一个大,几乎以每年一个数量级持续了几年。回忆在16年的时候,我和几个研究员讨论是不是模型参数量达到人脑神经元的量级,自然就会产生更高级的智能。在那个时候,VGG、ResNet等模型参数量和人脑还有几个数量级的差距。通过人们习惯的线性思维,很难想象5年后模型的规模已经达到人脑神经元的量级了(100Billion ncbi.nlm.nih.gov/pmc/ar)。
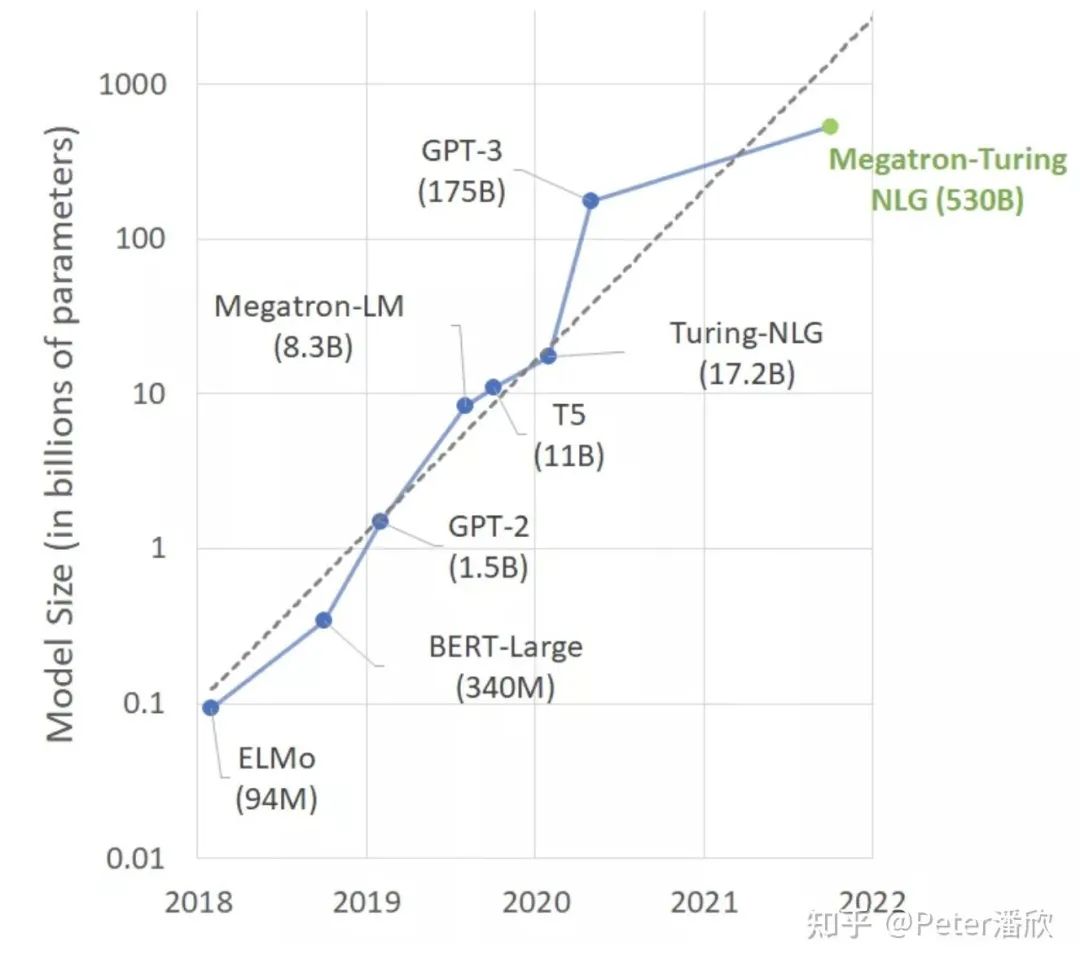
数据规模和模型爆发增长背后的算法突破很大一部分归功于Self-supervise Learning。(训练架构上也有不少突破:Peter潘欣:巨型AI模型背后的分布式训练技术: https://zhuanlan.zhihu.com/p/430383324。说起来BERT采用的Self-supervise方法出奇的简单,就是最简单的填词游戏,相信大多数人小时候都玩过。这个游戏给BERT模型玩却显著的提高了模型的泛化效果。 类似的思想也在最近两年被应用在CV领域,比如扣掉图片中一部分让模型预测。或者语音领域,挡住一段音频feature,让模型去预测。都取得了不错的效果。 随着模型规模的增长,我们似乎正在打开AI更高阶段的另一扇门。和之前“小”模型相比,这些巨型模型有一些更接近人的特殊能力,比如:
One-shot, Few-shot Learning。使用很少的样本就能在大模型的基础上训练获得新领域的能力。 Multi-Tasking。这些大的预训练模型可以被用在很多不同的任务上。之前卷积feature extractor也有类似的能力,但是相对局限一些。
业界大佬Jeff Dean和FeiFei Li等对未来的预测也都多少基于这些预训练大模型的技术,做出延展。比如Jeff的Pathway以及FeiFei的Foundation Model。
11. 压缩
其实压缩技术比深度学习技术的出现更加久远。早期的很多深度学习模型的压缩技术都是从其他领域的压缩技术借鉴而来,比如int8量化。深度学习由于模型体积远大于传统模型,而且研究也发现深度学习模型其中存在大量冗余参数。因此伴随着深度学习技术的应用,相关模型压缩技术也取得了非常显著的进步。简单回顾一些个人相关实践。
bfloat16。17年的时候,TPU训练卡的底层开发已经完成,为了让TensorFlow用户更好的使用TPU,需要整个python层完成bfloat16支持,并打通C++层的XLA。基于实验分析,bfloat16缓解了float16在梯度很小的时候容易round to zero的问题,保留了更多exponential bits,牺牲了不那么重要的precision bits。
int16, int8, int4。量化(quantization)和定点数计算取得了不错的成果。一方面是节省了空间,另外硬件定点数的计算效率也通常更高。比如在GPU上int8的理论速度可以比float32高一个数量级。int16可以被应用在部分模型的训练上,int8和int4等则多是在推理模型的存储和计算上使用。量化技术看似简单,其实细节很多,这里稍微展开一点:
training-aware or not。在训练时就进行量化可以减少一些效果的损失。 黑白名单。许多算子是对量化不友好的(e.g. conv vs softmax)。通常对于不友好的算子,会在前面插入反量化逻辑,回到浮点数。 min-max rounding。如果简单使用min-max作为上下界,很可能因为某个outlier导致大部分数值的解析度太低。因此会有许多方法自动计算合理的min-max。将outlier clip到min or max。 Distillation。有时也叫teacher-student。用一个大模型的中间输出去调教一个小模型。蒸馏的变种也很多,比如co-distillation,三个臭皮匠顶个诸葛亮。我们在推荐排序领域,用精排去蒸馏粗排、召回取得了不错的成果。
Sparsification。前面提到DNN模型有大量参数其实是无效的。很多裁剪技术也都证明了这一点。通过一些技术(比如是loss中增加相关约束),可以让有效的参数远离0,无效的参数逼近0。在通过一些结构化的技术,可以裁剪调模型中很大一部分,而保障效果无损,或者损失较少。
Jeff看中的Pathway里稀疏激活不知是否也可以归到这一类。这是一个很诱人,也是一个非常难的方向。诱人在于不但可以将模型压缩几个数量级,理论计算量和能耗都能大幅压缩。艰难在于现在硬件和模型训练方式都不容易达到这个目标。但是,人脑似乎就是这么工作的。人类在思考的时候,大脑只有比较少的一部分被激活。
12. 推荐排序
最近三年在推荐排序上的系统方向工作比较多,对于相关算法也有一些研究。
这个方向有时被称作“沉默的大多数”:
“大多数”是因为互联网公司的主要AI算力其实都消耗在推荐排序类的深度学习模型上了。这些模型不但承载了互联网公司的主要业务形态(比如电商和视频的推荐),还承担了公司关键收入来源(比如广告推荐)。 “沉默”是说深度学习的技术突破和首先应用通常不源于这个方向,而更多来自于CV,NLP等更基础的方面。许多推荐排序技术的提升大多来自于CV,NLP成功技术的跨领域应用。深度学习领域的顶级研究员也相对少提到推荐排序相关的问题(有可能是个人局限性视角)。
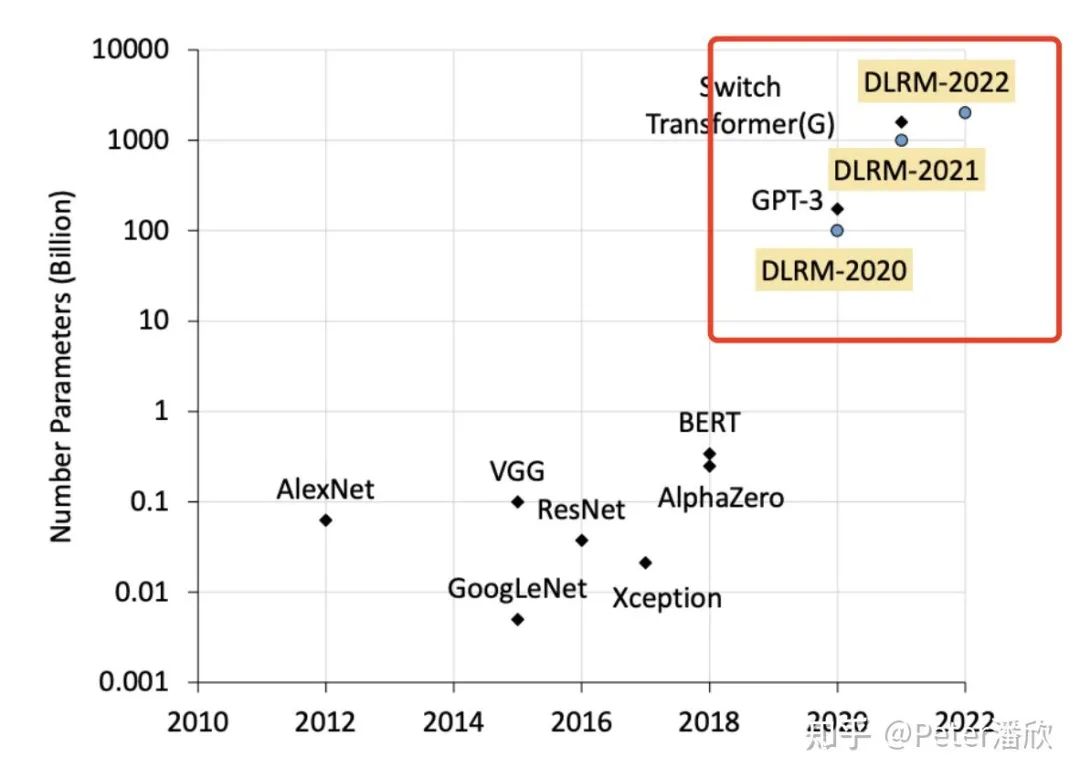
12.1 海量的Embedding和渺小的DNN
据了解,当16~17年CV,NLP大模型还在几百MB或者几GB的阶段徘徊时,广告排序模型就已经逼近了TB量级。巨大模型的参数不来自DNN里的Conv, LSTM或者是Attention。它们来自于巨大的Embedding Table。EmbeddingTable中每一行(向量)表示一个稀疏特征值(e.g. user_314151, Beijing, etc)的隐式表达。 这个EmbeddingTable可以达到数百亿行。为何会如此之大?除了互联网公司海量的用户规模,还来自于特征工程里面的笛卡尔交叉。
举个例子,一共有100个值表示不同年龄,100个值表示不同城市,100个表示不同的收入。我们可以做个特征交叉获得一类新的交叉特征100100100=10^6,其中只要一个特征值可以表示“北京60岁高收入”人群。遇到这个特征值,模型就可以给他们推荐个性化的商品了(人参?)。如果笛卡尔积出现了user-id, item-id,模型体积可以轻易突破TB。 和EmbeddingTable相比,早期排序模型的DNN就小的多了,很多时候就是几层FullyConntected Layers。然而随着技术的发展,下文会看到DNN的模型结构也变得更加多样化。
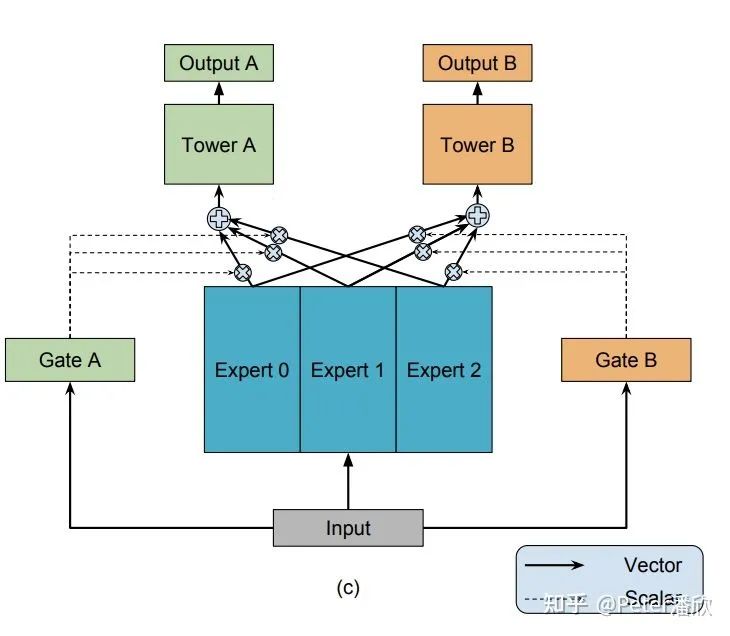
12.2 LR,FM,FFM,WDL,MMOE
从和算法人员的沟通发现,“好的特征”比“好的DNN模型”更有收益。一些论文也描述过当前DNN难以有效的学习高度稀疏特征之间的交叉泛化关系。 从直觉上,推荐排序模型的高维稀疏特征和CV、语音、NLP的信号相比有着比较大的不同。视觉图片和语音wave都是自然信号,有着非常强的规律性。NLP虽然是人造的产物,但是也大体服从显而易见的语法规律(否则就没法沟通了)。 但是推荐模型的特征输入却是高度自定义,且长尾信号非常稀疏的,就比如前面举例的“北京60岁高收入”只是10^6可能性中的一个(e.g. 深圳90岁无收入就比较少)。每次输入是从数亿个特征中挑选其中几百个或者几千个,来刻画这个用户的请求。 智能不够人工来凑。勤劳的算法人员在早期LR,FM,FFM等阶段,更多采用了人工实验的方式挑选了特征,但是我们也逐渐看到隐式、自动化交叉取得了更好的效果。16年的WDL是一个转折性的工作,推荐排序相对有机的融合了人工特征和DNN学习两个流派的优点。Wide负责记忆,Deep负责泛化。WDL更像是一个框架,Wide和Deep可以被替换成其他的结构,比如Wide使用FM就变成了DeepFM。而Deep的花样更多,可以引入Attention, RNN等等。18年的MMOE(Multi-gate Mixture-of-Experts)对推荐排序模型是一个新的较大的改进。和CV和NLP任务通常有明确的优化目标不太一样,推荐场景通常需要优化用户多个维度的体验,比如时长,点击,转发,点赞,多样性等等。传统方法需要单独训练多个模型。而MMOE解决了单个模型多个任务的问题。后来的PLE进一步缓解了跷跷板效应,让模型能够同时改进多个目标的效果。 最近两年模型DNN突破性的结构变化相对比较少,但是许多效果演进还是不少,累计也进一步提高了推荐排序的效果。比如更加复杂的embedding交叉结构,结合transformer、序列建模,构建更多、更细粒度的训练目标等等。 总体而言,推荐排序DNN复杂度相比NLP来说,要低很多。一个可能的原因是CPU训练的算力限制。随着新的架构解决了海量embedding的GPU训练问题,可能GPU训练能为推荐排序模型DNN复杂度和效果提升带来新的突破。
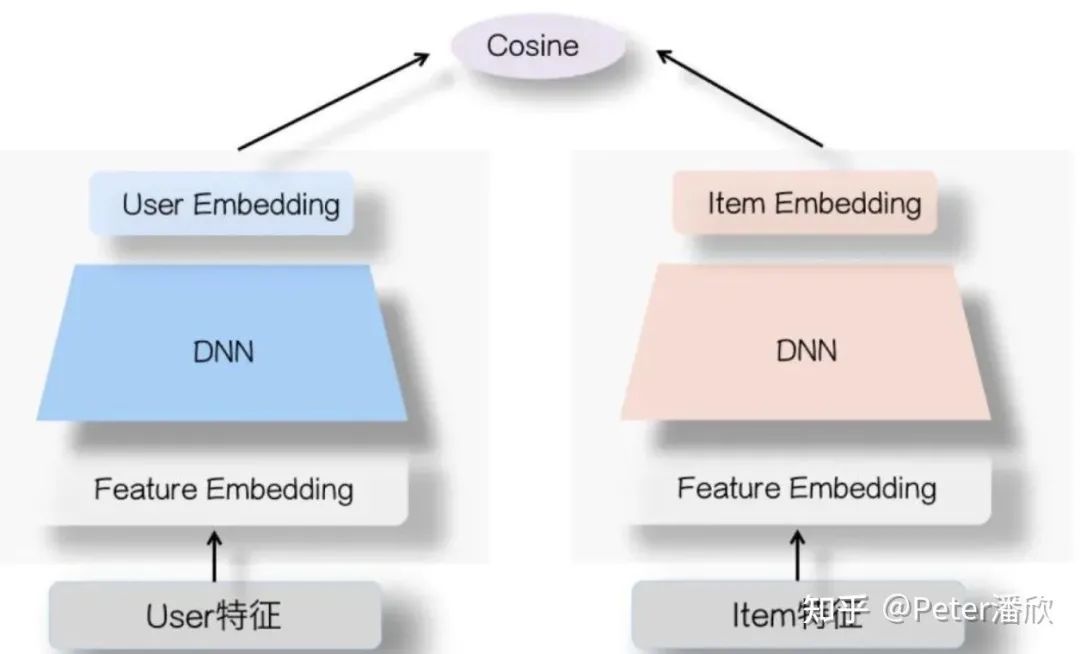
12.3 Tower, Tree, Graph
如果觉得推荐排序只有上一节提到的玩法,就有点太小看这个领域的算法人员了。市面上能找到的主流深度学习算法技术其实在推荐领域都被试了个遍,这里简单说几个: 双塔模型是推荐领域的经典了,常常被用在召回、粗排等需要极高性能的场景。由于Item特征的变化相对缓慢,可以提前批量算出所有Item Embedding。这样在线上服务时,只需要基于实时的User特征计算User Embedding,然后再做一个Cosine距离就可以知道这个User和Item的匹配程度了。 双塔模型为了能够分别计算User和Item向量,限制了特征和模型的复杂度,不方便进行user和item交叉特征的学习。Tree模型的思路是通过树的分治减少需要计算的item量,这样可以使用复杂的召回模型。类似的还有DeepRetrival等。 说起Graph模型不得不提这几年火起来的GraphNeuralNetwork(GNN),比如GraphSage等。其实思想有点类似word2vec和一些自监督的算法,通过一些游走策略改造子图,并通过他们之间的邻近关系,以及非子图节点的非相似关系来来构造样本进行学习,最终得到每个节点的隐式表达。而这些隐式表达则可以被用在推荐领域召回相似的物品。
12.4 多场景,端到端,预训练
大的互联网公司通常会有许多业务,比如字节的抖音、头条,腾讯的浏览器、视频、新闻、音乐等。每个业务内部又有细分为许多子场景,比如主页Feed,以及点击某个物品后进入到相似物品的推荐。而每个子场景又常常拆分为召回、粗排、精排、混排等多个阶段。通常人员组织架构也符合这样的拆分。 从下图可以看到,这种结构下产生了非常多的横向“竖井”,用户和数据被切割在各个竖井中了。纵向漏斗也被切分成各个阶段的独立模型,产生了较多的bias和训练目标一致性问题。
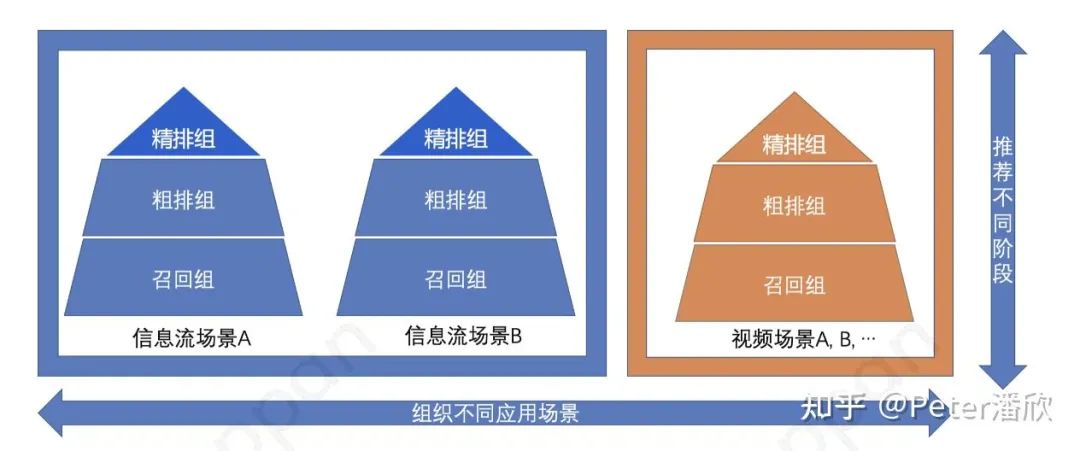
针对上面的问题,可以进行了横向的和纵向的打通工作:
横向来看,构造多场景的异构图,或者通过share和independent feature的方式构造多业务场景的MMOE模型。基于更丰富的数据进行预训练,而后应用在子场景上。这种方式对对于新用户和中小场景的提升尤其明显。 纵向上看,通过一次性训练任务同时训练召回、粗排、精排模型。利用精排更复杂和精准的预测结果来蒸馏前面两个阶段。这种方式一方面可以显著提升召回、粗排的效果,也可以压缩粗排模型的体积。
13. 总结与展望
回顾深度学习模型过去的发展历史,我们看到过去一些明显的规律和局限:
更宽、更深、更大的模型持续带来效果和能力上的惊喜,但是似乎在22年走到了一个反思的节点。用VGG的100M和Megatron的530B相比,规模提升了1000~10000倍。然而,规模的边际效用降低,能耗和迭代效率都成为较大的问题。 模型越来越全能,算法越来越归一。放在10年前,CV和NLP的研究员可能风马牛不相及。但是现在我发现CV,NLP,语音的SOTA模型都能用上Transformer结构,都能用上自监督训练。而且模型能够编码多种模态的输入。 可解释,可控性,可预测能力依然没有突破。就好像对人脑的理解一样,对于深度学习模型的理解依然很单薄。或许高维空间本身就是无法被直观理解的。无法被理解的基础上,就不容易被管控。通过one-shot似乎可以让模型快速掌握新的能力,但是对于模型其他能力的影响缺失很难判断的。就好比你让一辆车很容易躲避障碍物,却可能导致它侧翻的概率增加。 随机应变和规划能力不足。虽然模型有着超越人类的感知和记忆能力,但是面对复杂世界的行动和决策却相对较弱。从AlphaGo和一些相关工作,可能强化学习是一个可以持续挖掘突破的方向。但是强化学习的发展有可能带来对可控性和可预测性的担忧。假如用强化学习来训练无人机,并用“击中目标”作为Reward。会发生什么?能不能让它“绝不伤害人类”。 算力、数据、算法的进步造就了今天技术成就。但是现在能耗,硬件算力,体系结构(e.g. 冯诺依曼架构、内存墙)都对人工智能的发展产生了制约,可能迈向通用人工智能的路上还需要先进行、更彻底的底层颠覆。
从规律和问题出发,可以展望未来的一些发展趋势:
受限能耗、系统性能、模型迭代效率,边际效益递减等因素,模型的规模增长不会像过去几年一样高速,而是朝更高效的模型结构(e.g. Sparse Activation),训练方式(Self-supervise),更高效的部署(e.g. Distillation)发展。 模型的感知和记忆能力会快速、全面超过人类水平,并且固化下来,形成通用化的应用场景。BERT可能只是一个开始,基于视频等复杂环境的自监督学习可能会构建更好的“世界模型”(world model),这个模型的通用能力会进一步的提升。 模型的动态决策能力,复杂场景的应变能力还有较大的发展空间。模型的可解释性、可控性短期可能不会有比较大的突破,但是大的研究机构会持续的投入,并形成一些差异化的竞争力。 深度学习算法和生命科学,金融风控等场景结合,可能会逐步有更多突破性的应用进展。比如在生命科学、生物制药方向,可能会产生影响整个人类物种的技术。而一旦金融风控等领域取得重大突破,社会的许多治理会逐渐从人变成机器。 在虚拟世界(或者说是现在比较火的元宇宙),未来5~10年可能会先出现比较通用的智能体。原因是基于强化学习的相关技术在虚拟世界有较低的迭代成本和安全顾虑。
版权声明