
jetson中使用cuda
前言
昨天分享了 cuda在ubuntu的安装和使用,今天在jetson nano上进行测试验证使用cuda。在jetson nano上安装使用cuda和ubuntu有所区别,所以写了这篇文章。
首先cuda使用上还是有cuda库直接调用和opencv cuda库调用,最后还有在jetson nano内置的CUDA Samples。当然我们也可以自己在网络下载,这是官方链接:https://github.com/NVIDIA/cuda-samples
jetson nano安装cuda
cuda在jetson nano的镜像是默认安装了的,已安装版本是:
CUDA10.2,CUDNNv8,tensorRT,opencv4.1.1,python2,python3,tensorflow2.3,所以我们可以直接使用,不过oepncv的cuda库是没有的,需要我们进行安装,不过安装的方式和上一篇文章类似,不过是有些操作细节需要修改一下。
由于jetson nano上面已经自带了CUDA10.2,那么我们直接使用了哈。因为一些普通演示demo上篇文章就介绍过了,所以本次就写了 cuda在ubuntu的安装使用分享
简单信息查询demo
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
using namespace std;
int main()
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
for (int i = 0; i < deviceCount; i++)
{
cudaDeviceProp devPro;
cudaGetDeviceProperties(&devPro, i);
cout << "使用GPU:" << i << endl;
cout << "设备全局内存总量:" << devPro.totalGlobalMem << endl;
cout << "SM的数量:" << devPro.multiProcessorCount << endl;
cout << "每个线程块的共享内存大小:" << devPro.sharedMemPerBlock / 1024<< "KB" << endl;
cout << "每个线程块的最大线程数:" << devPro.maxThreadsPerBlock << endl;
cout << "一个线程块中可用的寄存器数:" << devPro.regsPerBlock << endl;
cout << "每个EM的最大线程数:" << devPro.maxThreadsPerMultiProcessor << endl;
cout << "每个EM的最大线束数:" << devPro.maxThreadsPerMultiProcessor / 32<< endl;
cout << "设备上多处理器的数量:" << devPro.multiProcessorCount << endl;
}
getchar();
return 0;
}
执行效果:

cuda sample库验证
这是就是前言里面说到的cuda的例子,大家可以写cuda的代码时候,可以参考里面的范例。而在nano里面,JetPack系统将 CUDA 环境安装在 /usr/local/cuda 下面。
有人可能发现在 /usr/local 下面有 cuda 目录与 cuda-10.2 目录,两者的内容完全一样。事实上 cuda 这个目录是cuda-10.2软链接,实际的内容指向 cuda-10.2 这个目录。因为 JetPack 以后会更新 CUDA 版本,所有 cuda-10.2 可能会改变,于是就使用 cuda 软连接来确保一致性。
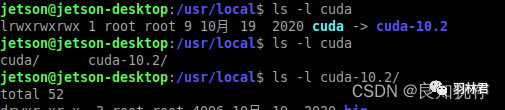
接下来进入 samples 目录
cd /usr/local/cuda/samples/,里面有早已经放置好的示例,但是都是没有编译的,当然我们可以在samples目录下直接使用sudo make -j4进行编译,但是实际上在我编译发现在主目录编译太费时间了,建议大家到各个子目录进行编译,然后验证。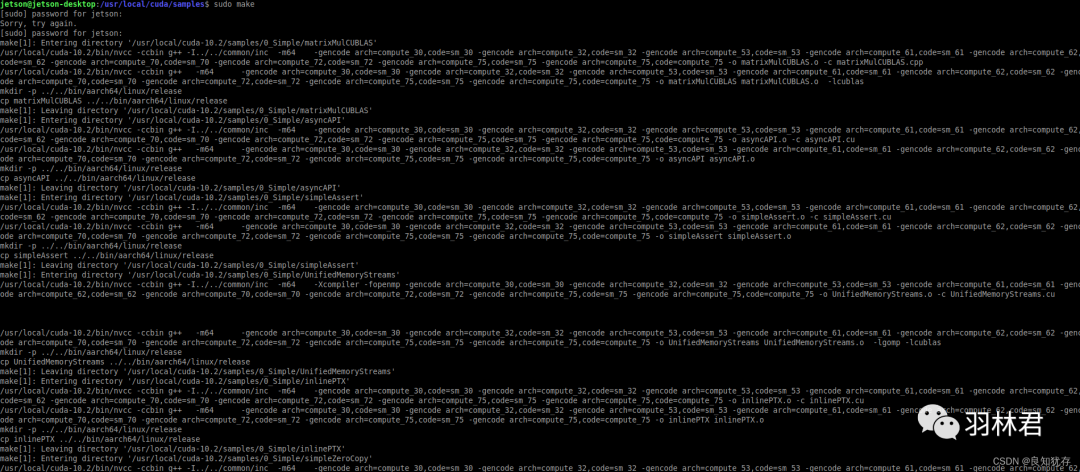
在每个目录下面都有对应的子Makefile文件,大家到子目录make即可。例如:cd 5_Simulations/nbody/,(nbody 是粒子碰撞模拟,大家也可以到其他目录验证测试,因为这个 nbody 范例提供 GPU 与 CPU 的执行,可以让大家更清楚两者之间的性能差距) 然后 sudo make -j4
ls -l 大家就可以看到绿色编译好的可执行文件,这个时候我们就可以 sudo ./nbody 进行测试
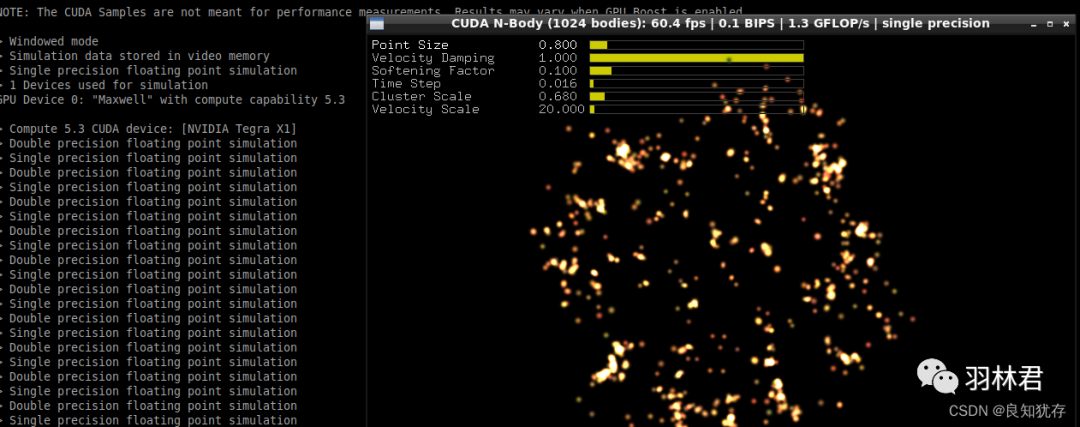
这个范例默认是在 GPU 上执行,并且预设粒子数量为 1024 个。可以视窗头部看到一些性能相关的信息,包括:模拟粒子数是1024个、渲染性能的帧率、指令性能BIPS(每秒百万次)、计算机性能GFLPOS(单精度状态)。此外在界面的左上角还有粒子大小、速度阻尼、软化系数、时间步长、集群规模、速度范围。
sudo ./nbody GPU跑的示意图
cpu执行的话是需要设置额外的参数 sudo ./nbody -cpu -numbodies=1024
CPU跑的示意图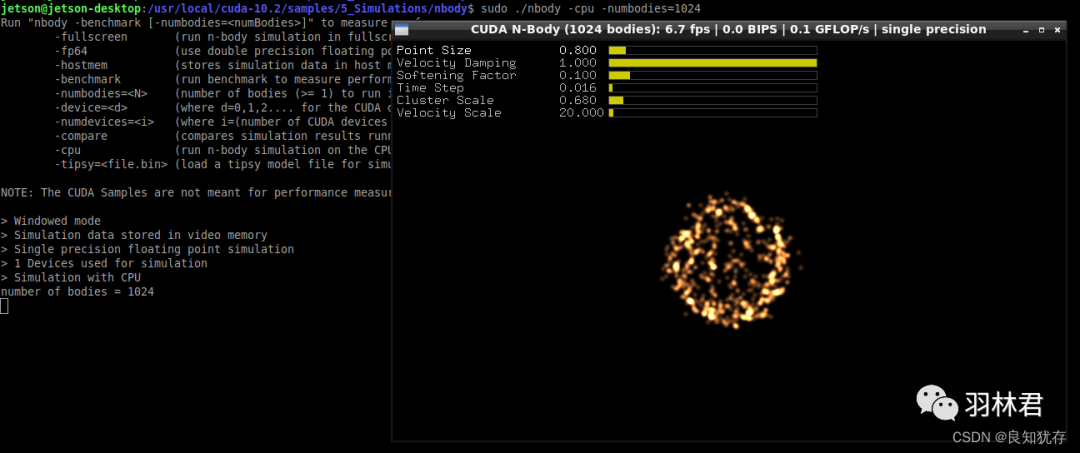
将视窗头部的性能数据与前一个在 GPU 上执行的结果进行比较,可以几项性能都有10倍左右的差距,这效果就非常显而易见了。这就是GPU使用的明显对比了哈。
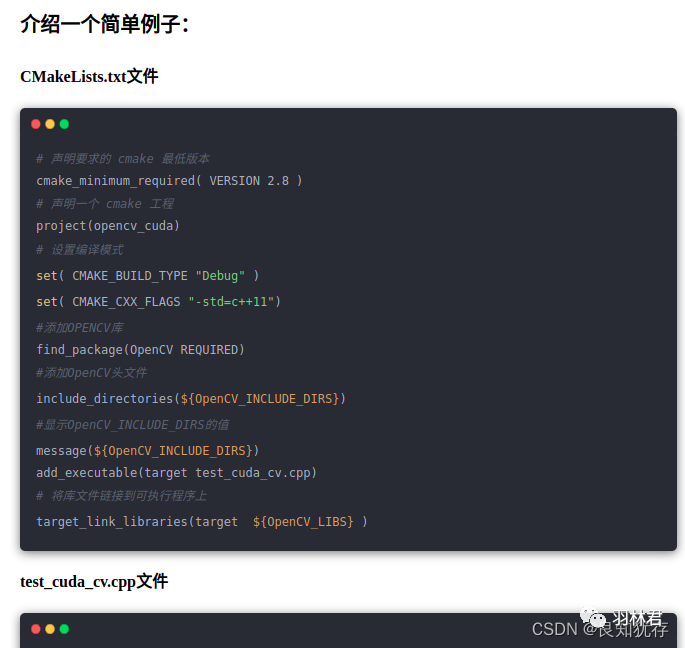
编译opencv的cuda库
这个和上一篇文件类似,也是要一些特殊的cmake选项,我执行编译的选项如下,大家把opencv_contrib-4.1.1替换成自己的目录即可。
cmake -D CMAKE_BUILD_TYPE=Release\
-D ENABLE_CXX11=ON\
-D CMAKE_INSTALL_PREFIX=/usr/local\
-D WITH_CUDA=ON\
-D CUDA_ARCH_BIN=${cuda_compute}\
-D CUDA_ARCH_PTX=""\
-D ENABLE_FAST_MATH=ON\
-D CUDA_FAST_MATH=ON\
-D WITH_CUBLAS=ON\
-D WITH_LIBV4L=ON\
-D WITH_GSTREAMER=ON\
-D WITH_GSTREAMER_0_10=OFF\
-D WITH_OPENGL=ON\
-D CUDA_NVCC_FLAGS="--expt-relaxed-constexpr" \
-D CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-10.2\
-D WITH_TBB=ON\
-D OPENCV_EXTRA_MODULES_PATH=/home/jetson/lyn_work/opencv_contrib-4.1.1/modules ../
不过这里我进行了先在我的ubuntu系统进行cmake 和make执行,把opencv-4.1.1和opencv_contrib-4.1.1两个文件夹打包拷贝到我的jetson nano编译。为什么这么做呢,因为遇到了一些编译错误,如下:
[ 98%] Linking CXX executable ../../bin/opencv_perf_xphoto
In file included from /home/jetson/lyn_work/opencv-4.1.1/modules/core/include/opencv2/core.hpp:54:0,
from /home/jetson/lyn_work/opencv-4.1.1/modules/core/include/opencv2/core/cuda.hpp:51,
from /home/jetson/lyn_work/opencv_contrib-4.1.1/modules/cudaoptflow/include/opencv2/cudaoptflow.hpp:50,
from /home/jetson/lyn_work/opencv-4.1.1/build/modules/cudaoptflow/precomp.hpp:48:
/home/jetson/lyn_work/opencv-4.1.1/modules/core/include/opencv2/core/base.hpp:320:40: error: expected constructor, destructor, or type conversion before ‘(’ token
#define CV_Error( code, msg ) cv::error( code, msg, CV_Func, __FILE__, __LINE__ )
网上也有一些相似问题,不过经过自己对比log之后,发现是jetson上面网络不好,在编译opencv中,下载一些包,网络不太通畅,导致下载失败,最终导致的编译error。所以我在自己ubuntu系统(有梯子)下载好之后再进行编译。
-- data: Download: face_landmark_model.dat

在拷贝到jetson nano之后,解压两个文件夹,在opencv的build目录删除掉 cmake的缓存文件,rm CMakeCache.txt ,重新cmake ,这个时候重新编译就不需要重新下载依赖的包了。
编译完之后,我们就可以使用,测试方法还是和上一篇文章类似,这里我就不多赘述了,大家可以参考上一篇的内容。cuda在ubuntu的安装使用分享
结语
这就是我自己的一些cuda在jetson nano的使用分享,下一篇我们聊聊cuda实际使用gpu加速和cpu使用的对比,以及它两使用场景分析。。如果大家有更好的想法和需求,也欢迎大家加我好友交流分享哈。
作者:良知犹存,白天努力工作,晚上原创公号号主。公众号内容除了技术还有些人生感悟,一个认真输出内容的职场老司机,也是一个技术之外丰富生活的人,摄影、音乐 and 篮球。关注我,与我一起同行。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧推荐阅读
【3】CPU中的程序是怎么运行起来的 必读
本公众号全部原创干货已整理成一个目录,回复[ 资源 ]即可获得。