
NVIDIA GPU / CUDA 中使用 OpenCV 深度神经网络模块

在本教程中,您将学习如何将 OpenCV 的“深度神经网络”(DNN) 模块与 NVIDIA GPU、CUDA 和 cuDNN 结合使用,以将推理速度提高 211-1549%。
早在 2017 年 8 月,我发表了我的第一个关于使用 OpenCV 的“深度神经网络”(DNN)模块进行图像分类的教程。
PyImageSearch 的读者非常喜欢 OpenCV 的 dnn 模块的便利性和易用性,因此我陆续发布了有关 dnn 模块的一些教程。
这些教程都使用 OpenCV 的 dnn 模块来进行下面操作:
(1) 从磁盘加载预训练的网络;
(2) 对输入图像进行预测;
(3) 显示结果,允许您构建自己的自定义计算机视觉 /deep learning 管道用于您的特定项目。
然而,OpenCV 的 dnn 模块最大的问题是缺乏 NVIDIA GPU/CUDA 支持——这些模型你不能轻易地使用 GPU 来提高管道的每秒帧数 (FPS) 处理率。
对于 Single Shot Detector (SSD) 教程来说,这并不是什么大问题,它可以轻松地在 CPU 上以 25-30+ FPS 的速度运行,但对于 YOLO 和 Mask R-CNN 来说,这是一个巨大的问题,它们很难做到在 CPU 上获得超过 1-3 FPS。
这一切在 2019 年的 Google Summer of Code (GSoC) 中发生了变化。
在 dlib 的 Davis King 的带领下,由 Yashas Samaga 实施,OpenCV 4.2 现在支持使用 OpenCV 的 dnn 模块进行推理的 NVIDIA GPU,将推理速度提高了 1549%!
在今天的教程中,我将向您展示如何编译和安装 OpenCV 以利用您的 NVIDIA GPU 进行深度神经网络推理。
然后在下周的教程中,我将为您提供 Single Shot Detector、YOLO 和 Mask R-CNN 代码,这些代码可用于使用 OpenCV 来利用您的 GPU。接着我们将对结果进行基准测试,并将它们与仅使用 CPU 的推理进行比较,以便您了解哪些模型可以从使用 GPU 中获益最多。
要了解如何使用 NVIDIA GPU、CUDA 和 cuDNN 支持编译和安装 OpenCV 的“dnn”模块,请继续阅读!
如何在 NVIDIA GPU、CUDA 和 cuDNN 中使用 OpenCV 的“dnn”模块
在本教程的其余部分,我将向您展示如何从源代码编译 OpenCV,以便您可以利用 NVIDIA GPU 加速推理来进行预训练的深度神经网络。
为 NVIDIA GPU 支持编译 OpenCV 时的假设
为了在 NVIDIA GPU 支持下编译和安装 OpenCV 的“深度神经网络”模块,我将做出以下假设:
1、你有一个 NVIDIA GPU。这应该是一个明显的假设。如果您没有 NVIDIA GPU,则无法编译具有 NVIDIA GPU 支持的 OpenCV 的“dnn”模块。
2、您正在使用 Ubuntu 18.04(或其他基于 Debian 的发行版)。说到深度学习,我强烈推荐基于 Unix 的机器而不是 Windows 系统(实际上,我在 PyImageSearch 博客上不支持 Windows)。如果您打算使用 GPU 进行深度学习,请在 macOS 或 Windows 上使用 Ubuntu——它更容易配置。
3、您知道如何使用命令行。我们将在本教程中使用命令行。如果您不熟悉命令行,我建议您先阅读此命令行介绍,然后花几个小时(甚至几天)练习。同样,本教程不适用于那些全新的命令行。
4、您能够阅读终端输出并诊断问题。如果您以前从未这样做过,从源代码编译 OpenCV 可能具有挑战性——有很多事情会让您感到困惑,包括丢失的包、不正确的库路径等。即使使用我的详细指南,您也可能会犯错误一路上。不要气馁!花点时间了解您正在执行的命令、它们的作用,最重要的是,阅读命令的输出!不要盲目复制粘贴;你只会遇到错误。
说了这么多,让我们开始为 NVIDIA GPU 推理配置 OpenCV 的“dnn”模块。
第 1 步:安装 NVIDIA CUDA 驱动程序、CUDA Toolkit 和 cuDNN

本教程假设您已经拥有:
一个英伟达 GPU已安装该特定 GPU 的 CUDA 驱动程序CUDA Toolkit 和 cuDNN 配置和安装
如果您的系统上有 NVIDIA GPU,但尚未安装 CUDA 驱动程序、CUDA Toolkit 和 cuDNN,则您需要先配置您的机器——我不会在本指南中介绍 CUDA 配置和安装。一旦您安装了正确的 NVIDIA 驱动程序和工具包,您就可以返回本教程。
第 2 步:安装 OpenCV 和“dnn”GPU 依赖项
为 NVIDIA GPU 推理配置 OpenCV 的“dnn”模块的第一步是安装适当的依赖项:
$ sudo apt-get update$ sudo apt-get upgrade$ sudo apt-get install build-essential cmake unzip pkg-config$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev$ sudo apt-get install libv4l-dev libxvidcore-dev libx264-dev$ sudo apt-get install libgtk-3-dev$ sudo apt-get install libatlas-base-dev gfortran$ sudo apt-get install python3-dev
如果您遵循我的 Ubuntu 18.04 深度学习配置指南,那么应该已经安装了大多数这些软件包,但为了安全起见,我建议运行上述命令。
第 3 步:下载 OpenCV 源代码
没有支持 NVIDIA GPU 的“pip-installable”版本的 OpenCV——相反,我们需要使用正确的 NVIDIA GPU 配置集从头开始编译 OpenCV。
这样做的第一步是下载 OpenCV v4.2 的源代码:
$ cd ~$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.2.0.zip$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.2.0.zip$ unzip opencv.zip$ unzip opencv_contrib.zip$ mv opencv-4.2.0 opencv$ mv opencv_contrib-4.2.0 opencv_contrib
我们现在可以继续配置我们的构建。
第 4 步:配置 Python 虚拟环境

如果您遵循我的 Ubuntu 18.04、TensorFlow 和 Keras 深度学习配置指南,那么您应该已经安装了 virtualenv 和 virtualenvwrapper:
如果您的机器已配置,请跳至本节中的 mkvirtualenv 命令。
否则,请按照以下每个步骤配置您的机器。
Python 虚拟环境是 Python 开发的最佳实践。它们允许您在隔离的、独立的开发和生产环境中测试不同版本的 Python 库。Python 虚拟环境被认为是 Python 世界中的最佳实践——我每天都在使用它们,你也应该这样做。
如果您还没有安装 pip,Python 的包管理器,您可以使用以下命令安装:
$ wget https://bootstrap.pypa.io/get-pip.py$ sudo python3 get-pip.py
安装 pip 后,您可以同时安装 virtualenv 和 virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper$ sudo rm -rf ~/get-pip.py ~/.cache/pip
然后,您需要打开 ~/.bashrc 文件并更新它以在打开终端时自动加载 virtualenv/virtualenvwrapper。我更喜欢使用 nano 文本编辑器,但您可以使用最适合的编辑器:
$ nano ~/.bashrc打开 ~/.bashrc 文件后,滚动到文件底部,然后插入以下内容:
# virtualenv and virtualenvwrapperexport WORKON_HOME=$HOME/.virtualenvsexport VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3source /usr/local/bin/virtualenvwrapper.sh
从那里,保存并退出您的终端(ctrl + x , y ,回车)。然后,您可以在终端会话中重新加载 ~/.bashrc 文件:
$ source ~/.bashrc你只需要运行一次上面的命令——因为你更新了你的 ~/.bashrc 文件,当你打开一个新的终端窗口时,virtualenv/virtualenvwrapper 环境变量将自动设置。
最后一步是创建你的 Python 虚拟环境:
$ mkvirtualenv opencv_cuda -p python3mkvirtualenv 命令使用 Python 3 创建一个名为 opencv_cuda 的新 Python 虚拟环境。然后,您应该将 NumPy 安装到 opencv_cuda 环境中:
$ pip install numpy如果您曾经关闭终端或停用 Python 虚拟环境,您可以通过 workon 命令再次访问它:
$ workon opencv_cuda如果您不熟悉 Python 虚拟环境,我建议您花一点时间阅读它们的工作原理——它们是 Python 世界中的最佳实践。如果您选择不使用它们,那完全没问题,但请记住,您的选择并不能免除您学习正确的 Python 最佳实践的责任。现在就花时间投资于您的知识。
第 5 步:确定您的 CUDA 架构版本
在编译支持 NVIDIA GPU 的 OpenCV 的“dnn”模块时,我们需要确定我们的 NVIDIA GPU 架构版本:
1、当我们在下一节的 cmake 命令中设置 CUDA_ARCH_BIN 变量时,这个版本号是必需的。2、NVIDIA GPU 架构版本取决于您使用的 GPU,因此请确保提前了解您的 GPU 型号。3、未能正确设置 CUDA_ARCH_BIN 变量可能导致 OpenCV 仍在编译但无法使用 GPU 进行推理(使诊断和调试变得麻烦)。
确定您的 NVIDIA GPU 架构版本的最简单方法之一是简单地使用 nvidia-smi 命令:
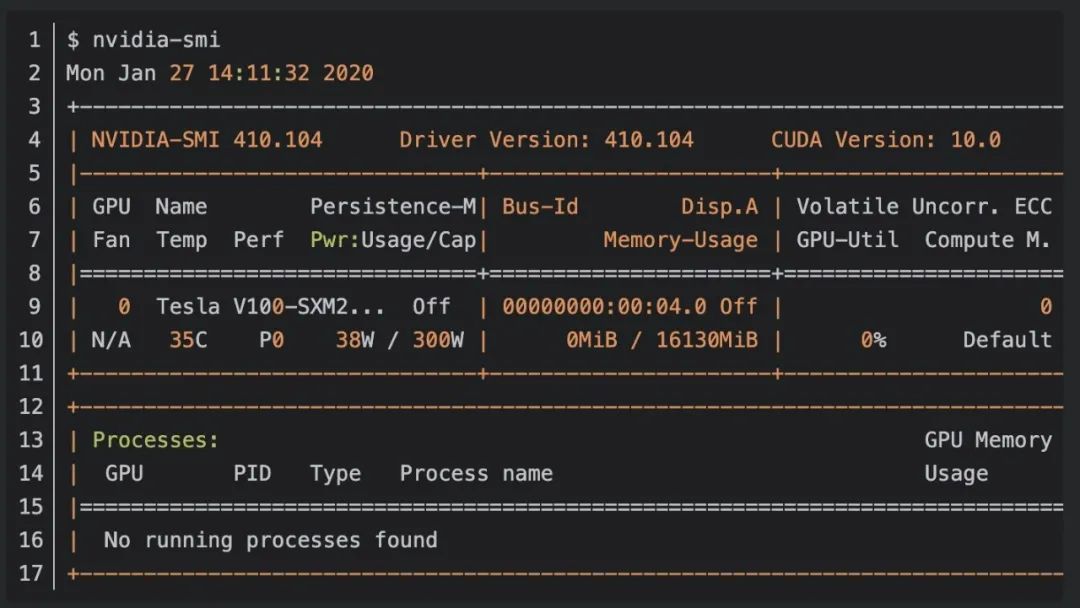
检查输出,您可以看到我使用的是 NVIDIA Tesla V100 GPU。在继续之前,请确保您自己运行 nvidia-smi 命令以验证您的 GPU 模型。
现在我有了我的 NVIDIA GPU 模型,我可以继续确定架构版本。
您可以使用此页面找到适用于您的特定 GPU 的 NVIDIA GPU 架构版本:
https://developer.nvidia.com/cuda-gpus向下滚动到支持 CUDA 的 Tesla、Quadro、NVS、GeForce/Titan 和 Jetson 产品列表:
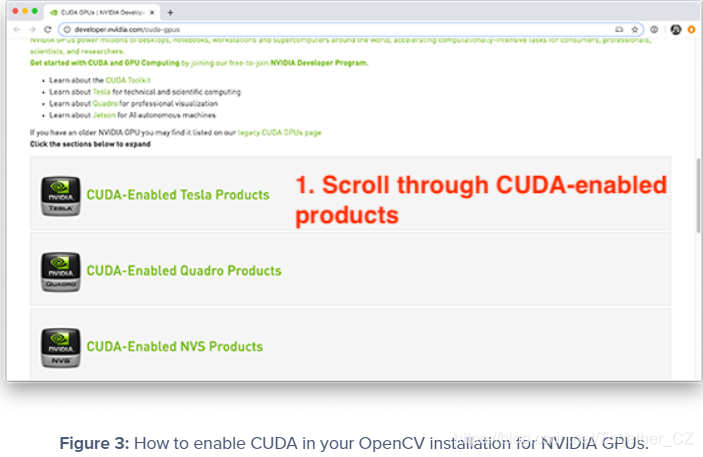
由于我使用的是 V100,我将单击“启用 CUDA 的 Tesla 产品”部分:
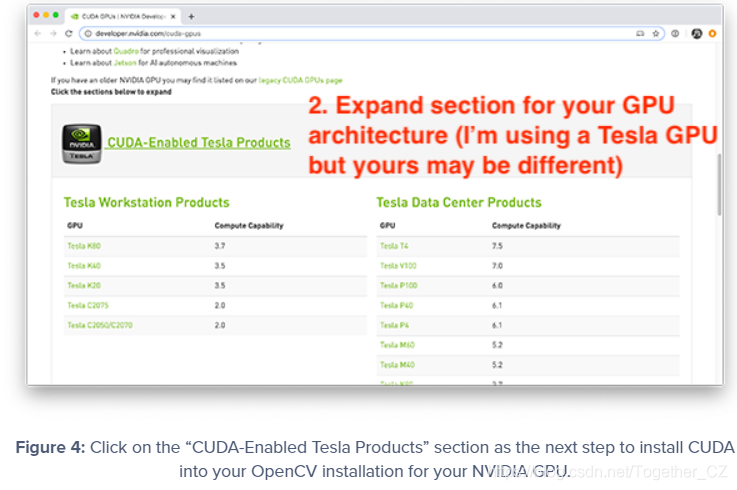
向下滚动,我可以看到我的 V100 GPU:

如您所见,我的 NVIDIA GPU 架构版本是 7.0 — 您应该为自己的 GPU 模型执行相同的过程。确定 NVIDIA GPU 架构版本后,请记下它,然后继续下一部分。
第 6 步:使用 NVIDIA GPU 支持配置 OpenCV
此时,我们已准备好使用 cmake 命令配置我们的构建。cmake 命令扫描依赖项,配置构建,并生成 make 实际编译 OpenCV 所需的文件。要配置构建,首先确保您位于用于编译具有 NVIDIA GPU 支持的 OpenCV 的 Python 虚拟环境中:
$ workon opencv_cuda接下来,将目录更改为您下载 OpenCV 源代码的位置,然后创建一个构建目录:
$ cd ~/opencv$ mkdir build$ cd build
然后,您可以运行以下 cmake 命令,确保根据您在上一节中找到的 NVIDIA GPU 架构版本设置 CUDA_ARCH_BIN 变量:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \-D CMAKE_INSTALL_PREFIX=/usr/local \-D INSTALL_PYTHON_EXAMPLES=ON \-D INSTALL_C_EXAMPLES=OFF \-D OPENCV_ENABLE_NONFREE=ON \-D WITH_CUDA=ON \-D WITH_CUDNN=ON \-D OPENCV_DNN_CUDA=ON \-D ENABLE_FAST_MATH=1 \-D CUDA_FAST_MATH=1 \-D CUDA_ARCH_BIN=7.0 \-D WITH_CUBLAS=1 \-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \-D HAVE_opencv_python3=ON \-D PYTHON_EXECUTABLE=~/.virtualenvs/opencv_cuda/bin/python \-D BUILD_EXAMPLES=ON ..
在这里您可以看到我们正在编译 OpenCV,同时启用了 CUDA 和 cuDNN 支持(分别为 WITH_CUDA 和 WITH_CUDNN)。
我们还指示 OpenCV 构建具有 CUDA 支持的“dnn”模块(OPENCV_DNN_CUDA)。我们还使用 ENABLE_FAST_MATH、CUDA_FAST_MATH 和 WITH_CUBLAS 进行优化。
最重要且容易出错的配置是您的 CUDA_ARCH_BIN — 确保正确设置!
CUDA_ARCH_BIN 变量必须映射到您在上一节中找到的 NVIDIA GPU 架构版本。
如果您错误地设置了这个值,OpenCV 仍然可以编译,但是当您尝试使用 dnn 模块执行推理时,您将收到以下错误消息:
File "ssd_object_detection.py", line 74, indetections = net.forward()cv2.error: OpenCV(4.2.0) /home/a_rosebrock/opencv/modules/dnn/src/cuda/execution.hpp:52: error: (-217:Gpu API call) invalid device function in function 'make_policy'
如果您遇到此错误,那么您就知道您的 CUDA_ARCH_BIN 设置不正确。您可以通过查看输出来验证您的 cmake 命令是否正确执行:
...-- NVIDIA CUDA: YES (ver 10.0, CUFFT CUBLAS FAST_MATH)-- NVIDIA GPU arch: 70-- NVIDIA PTX archs:---- cuDNN: YES (ver 7.6.0)...
在这里可以看到 OpenCV 和 cmake 已经正确识别了我的支持 CUDA 的 GPU、NVIDIA GPU 架构版本和 cuDNN 版本。
我还喜欢查看 OpenCV 模块部分,特别是待构建部分:
-- OpenCV modules:-- To be built: aruco bgsegm bioinspired calib3d ccalib core cudaarithm cudabgsegm cudacodec cudafeatures2d cudafilters cudaimgproc cudalegacy cudaobjdetect cudaoptflow cudastereo cudawarping cudev datasets dnn dnn_objdetect dnn_superres dpm face features2d flann fuzzy gapi hdf hfs highgui img_hash imgcodecs imgproc line_descriptor ml objdetect optflow phase_unwrapping photo plot python3 quality reg rgbd saliency shape stereo stitching structured_light superres surface_matching text tracking ts video videoio videostab xfeatures2d ximgproc xobjdetect xphoto-- Disabled: world-- Disabled by dependency: --- Unavailable: cnn_3dobj cvv freetype java js matlab ovis python2 sfm viz-- Applications: tests perf_tests examples apps-- Documentation: NO-- Non-free algorithms: YES
在这里您可以看到有许多 cuda* 模块,这表明 cmake 正在指示 OpenCV 构建我们支持 CUDA 的模块(包括 OpenCV 的“dnn”模块)。
您还可以查看 Python 3 部分以验证您的 Interpreter 和 numpy 是否都指向您的 Python 虚拟环境:
-- Python 3:-- Interpreter: /home/a_rosebrock/.virtualenvs/opencv_cuda/bin/python3 (ver 3.5.3)-- Libraries: /usr/lib/x86_64-linux-gnu/libpython3.5m.so (ver 3.5.3)-- numpy: /home/a_rosebrock/.virtualenvs/opencv_cuda/lib/python3.5/site-packages/numpy/core/include (ver 1.18.1)-- install path: lib/python3.5/site-packages/cv2/python-3.5
确保你也记下安装路径!当我们完成 OpenCV 安装时,您将需要该路径。
第 7 步:使用“dnn”GPU 支持编译 OpenCV
如果 cmake 没有错误退出,您可以使用以下命令编译具有 NVIDIA GPU 支持的 OpenCV:
$ make -j8您可以将 8 替换为处理器上可用的内核数。由于我的处理器有 8 个内核,我提供 8 个内核。如果您的处理器只有 4 个内核,请将 8 替换为 4 。
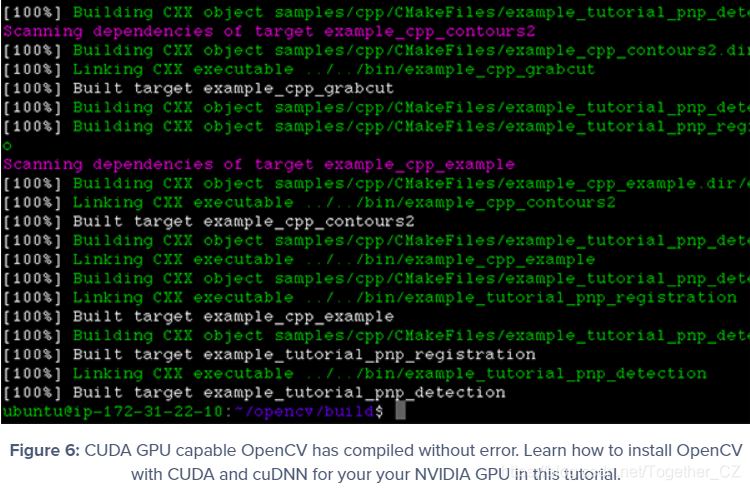
如您所见,我的编译完成且没有错误:
您可能会看到的一个常见错误如下:
$ makemake: * No targets specified and no makefile found. Stop.
如果发生这种情况,您应该返回第 6 步并检查您的 cmake 输出 - cmake 命令可能会因错误退出。如果 cmake 出现错误退出,则无法生成 make 的构建文件,因此 make 命令报告没有可供编译的构建文件。如果发生这种情况,请返回到您的 cmake 输出并查找错误。
第 8 步:安装支持“dnn”GPU 的 OpenCV
如果您在步骤 #7 中的 make 命令成功完成,您现在可以通过以下方式安装 OpenCV:
$ sudo make install$ sudo ldconfig
最后一步是将 OpenCV 库符号链接到您的 Python 虚拟环境中。
为此,您需要知道安装 OpenCV 绑定的位置——您可以通过步骤 #6 中的安装路径配置确定该路径。
就我而言,安装路径是 lib/python3.5/site-packages/cv2/python-3.5。这意味着我的 OpenCV 绑定应该在 /usr/local/lib/python3.5/site-packages/cv2/python-3.5 中。
我可以使用 ls 命令确认位置:
$ ls -l /usr/local/lib/python3.5/site-packages/cv2/python-3.5total 7168-rw-r--r-1 root staff 7339240 Jan 17 18:59 cv2.cpython-35m-x86_64-linux-gnu.so
在这里你可以看到我的 OpenCV 绑定被命名为 cv2.cpython-35m-x86_64-linux-gnu.so——你的名字应该与你的 Python 版本和 CPU 架构相似。
现在我知道了 OpenCV 绑定的位置,我需要使用 ln 命令将它们符号链接到我的 Python 虚拟环境中:
$ cd ~/.virtualenvs/opencv_cuda/lib/python3.5/site-packages/$ ln -s /usr/local/lib/python3.5/site-packages/cv2/python-3.5/cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
花一点时间先验证您的文件路径——如果 OpenCV 绑定的路径不正确,ln 命令将“静默失败”。
再次提醒,不要盲目复制粘贴上面的命令!仔细检查您的文件路径!
第 9 步:验证 OpenCV 是否使用带有“dnn”模块的 GPU
最后一步是验证:
OpenCV 可以导入到您的终端OpenCV 可以通过 dnn 模块访问您的 NVIDIA GPU 进行推理
让我们首先验证我们是否可以导入 cv2 库:
$ workon opencv_cuda$ pythonPython 3.5.3 (default, Sep 27 2018, 17:25:39)[GCC 6.3.0 20170516] on linuxType "help", "copyright", "credits" or "license" for more information.>>> import cv2>>> cv2.__version__'4.2.0'>>>
请注意,我使用 workon 命令首先访问我的 Python 虚拟环境——如果您使用的是虚拟环境,您应该这样做。
从那里我导入 cv2 库并显示版本。
果然,报出的OpenCV版本是v4.2,确实是我们编译而来的OpenCV版本。
接下来,让我们验证 OpenCV 的“dnn”模块是否可以访问我们的 GPU。确保 OpenCV 的“dnn”模块使用 GPU 的关键可以通过在模型加载后和推理执行之前立即添加以下两行来完成:
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
上面两行指示 OpenCV 应该使用我们的 NVIDIA GPU 进行推理。
要查看运行中的 OpenCV + GPU 模型的示例,请首先使用本教程的“下载”部分下载我们的示例源代码和预训练的 SSD 对象检测器。
从那里,打开一个终端并执行以下命令:
$ python ssd_object_detection.py --prototxt MobileNetSSD_deploy.prototxt \--model MobileNetSSD_deploy.caffemodel \--input guitar.mp4 --output output.avi \--display 0 --use-gpu 1[INFO] setting preferable backend and target to CUDA...[INFO] accessing video stream...[INFO] elasped time: 3.75[INFO] approx. FPS: 65.90
--use-gpu 1 标志指示 OpenCV 使用我们的 NVIDIA GPU 通过 OpenCV 的“dnn”模块进行推理。
如您所见,我使用 NVIDIA Tesla V100 GPU 获得了约 65.90 FPS。
然后,我可以将我的输出与仅使用 CPU(即不使用 GPU)进行比较:
$ python ssd_object_detection.py --prototxt MobileNetSSD_deploy.prototxt \--model MobileNetSSD_deploy.caffemodel --input guitar.mp4 \--output output.avi --display 0[INFO] accessing video stream...[INFO] elasped time: 11.69[INFO] approx. FPS: 21.13
这里我只获得了约 21.13 FPS,这意味着通过使用 GPU,我获得了 3 倍的性能提升!
“make_policy”错误
检查、双重检查和三重检查 CUDA_ARCH_BIN 变量是非常非常重要的。如果设置不正确,在运行上一节中的 ssd_object_detection.py 脚本时可能会遇到以下错误:
File "real_time_object_detection.py", line 74, indetections = net.forward()cv2.error: OpenCV(4.2.0) /home/a_rosebrock/opencv/modules/dnn/src/cuda/execution.hpp:52: error: (-217:Gpu API call) invalid device function in function 'make_policy'
该错误表明您的 CUDA_ARCH_BIN 值在运行 cmake 时设置不正确。
您需要返回第 5 步(在此确定您的 NVIDIA CUDA 架构版本),然后重新运行 cmake 和 make。
我还建议您在运行 cmake 和 make 之前删除构建目录并重新创建它:
$ cd ~/opencv$ rm -rf build$ mkdir build$ cd build
从那里你可以重新运行 cmake 和 make——在一个新的构建目录中这样做将确保你有一个干净的构建并且任何以前的(不正确的)配置都消失了。
概括
在本教程中,您学习了如何在 NVIDIA GPU、CUDA 和 cuDNN 支持下编译和安装 OpenCV 的“深度神经网络”(DNN)模块,让您获得 211-1549% 的推理和预测速度。
使用 OpenCV 的“dnn”模块需要你从源代码编译——你不能“pip install”支持 GPU 的 OpenCV。在下周的教程中,我将针对 CPU 和 GPU 推理速度对流行的深度学习模型进行基准测试,包括:SSD、YOLO、MaskR-CNN使用此信息,您将了解使用 GPU 最能受益的模型,确保您可以就 GPU 是否适合您的特定项目做出明智的决定。

作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者




点击下方阅读原文加入社区会员