
终于有人总结了图神经网络!
导读
本文从一个更直观的角度对当前经典流行的GNN网络,包括GCN、GraphSAGE、GAT、GAE以及graph pooling策略DiffPool等等做一个简单的小结。
笔者注:行文如有错误或者表述不当之处,还望批评指正!
一、为什么需要图神经网络?

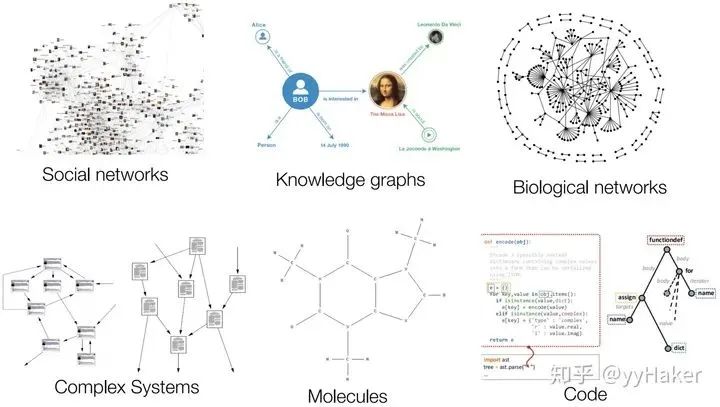
图的大小是任意的,图的拓扑结构复杂,没有像图像一样的空间局部性 图没有固定的节点顺序,或者说没有一个参考节点 图经常是动态图,而且包含多模态的特征
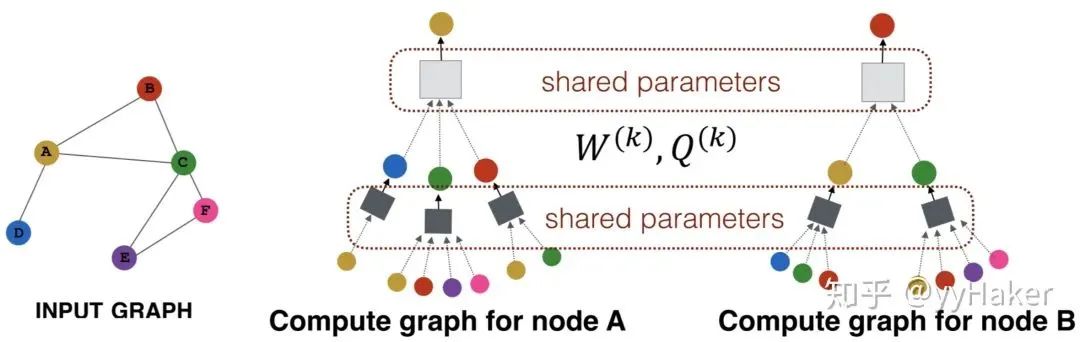
二. 图神经网络是什么样子的?
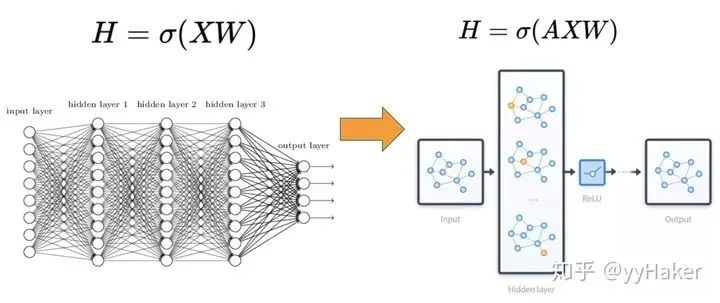
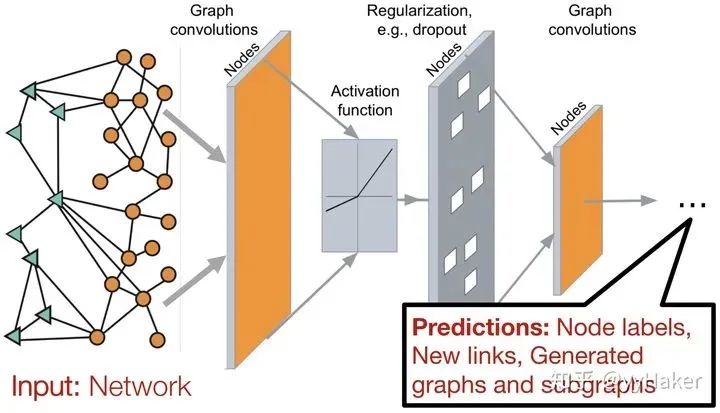
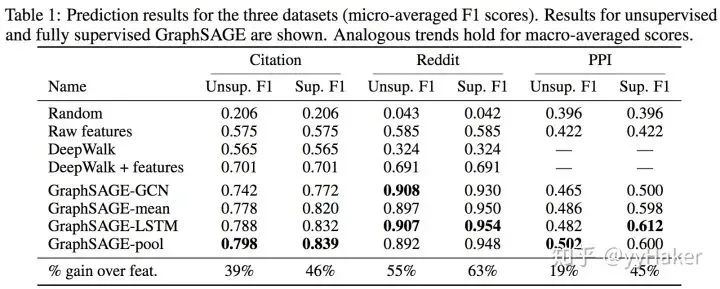
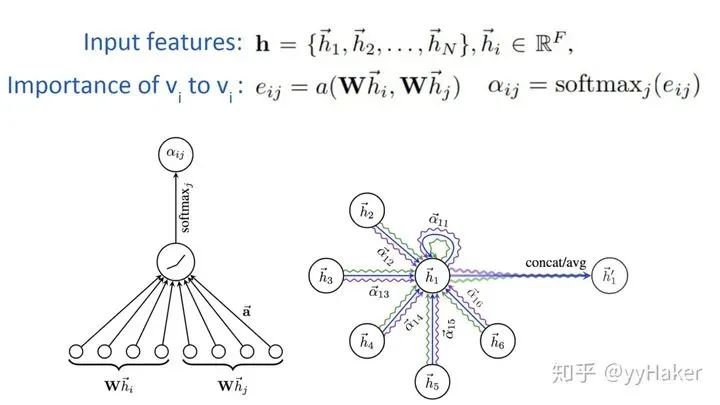
三、图神经网络的几个经典模型与发展
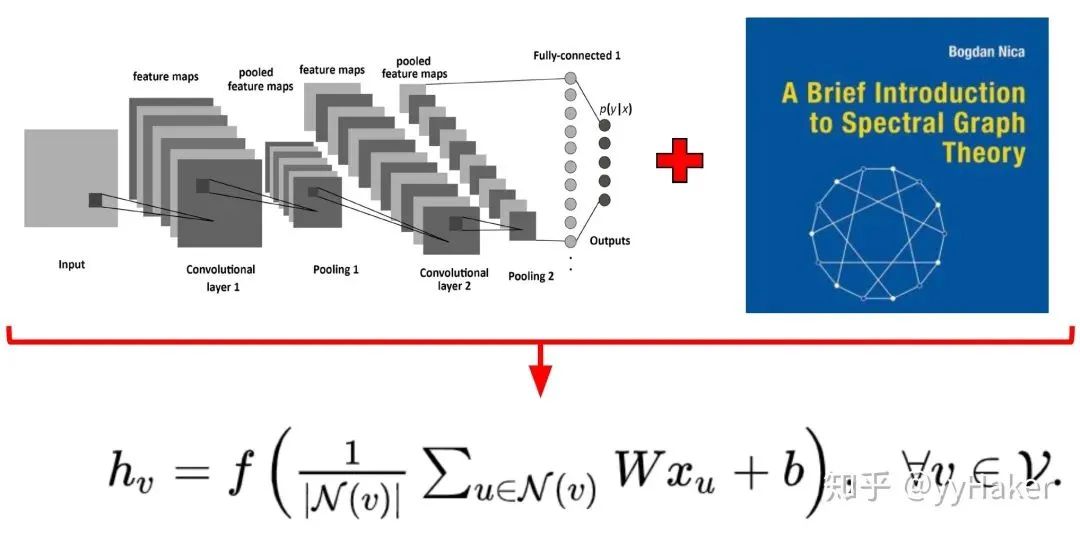
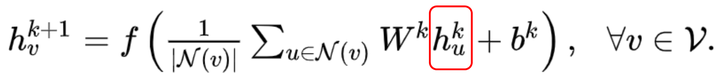
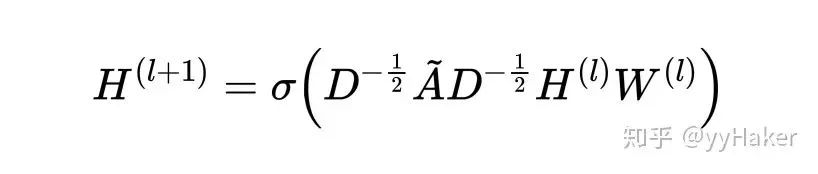
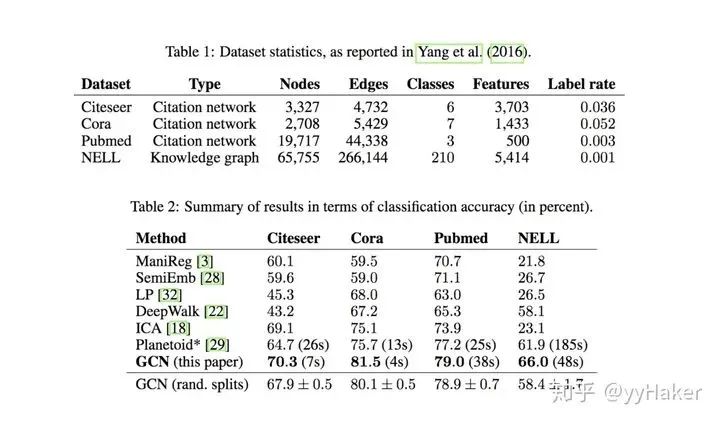
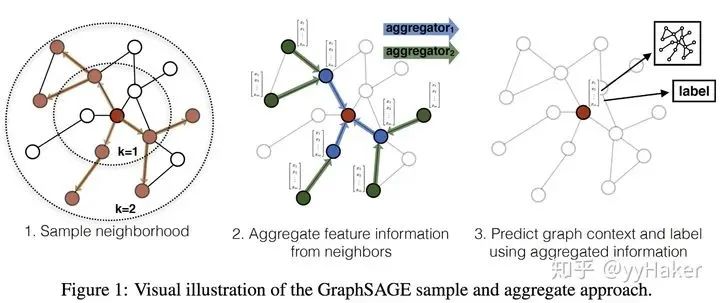



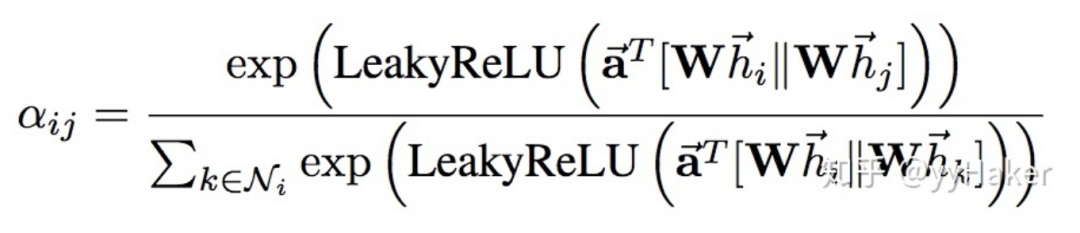
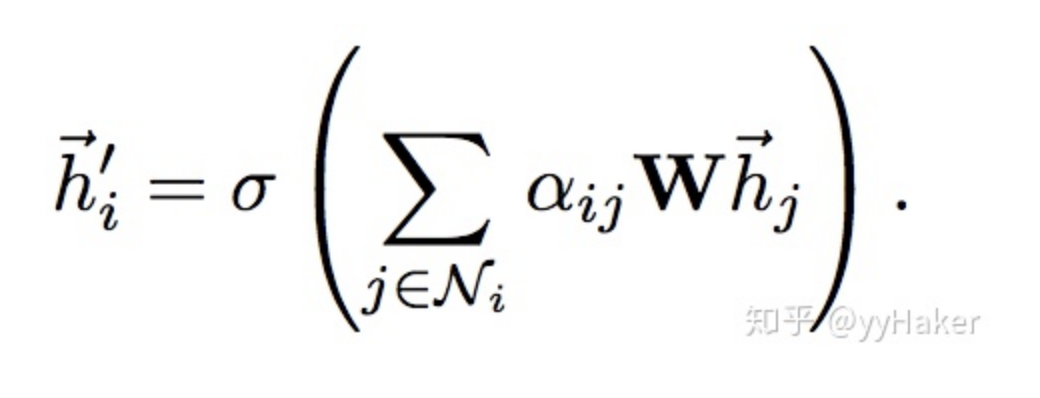
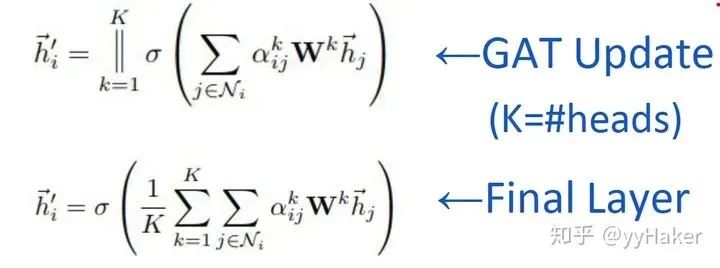
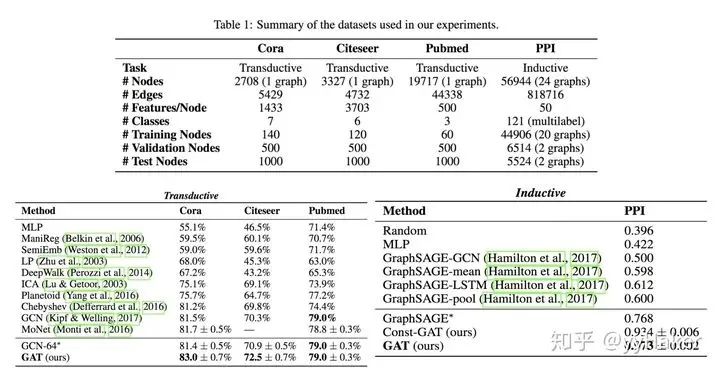
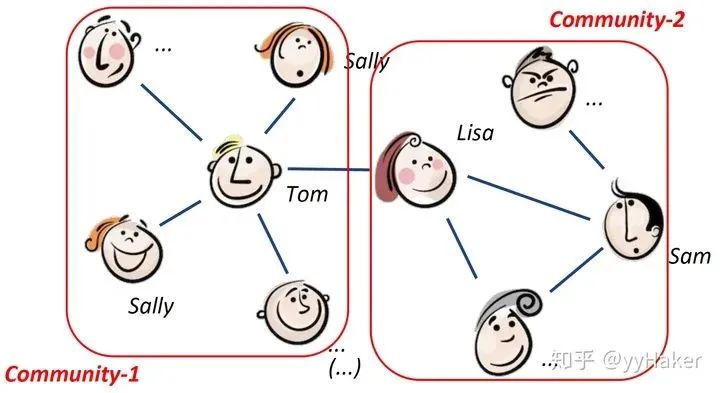
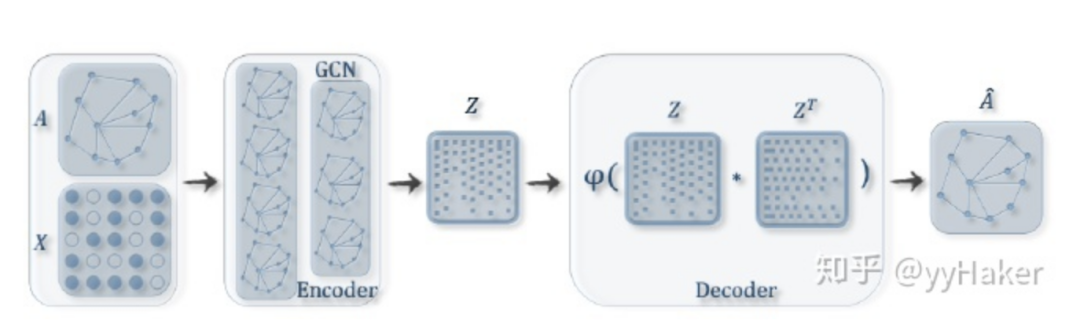
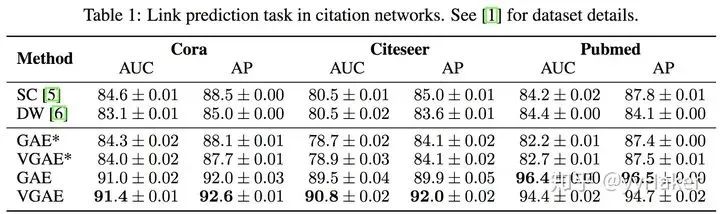
Graph Auto-Encoder(GAE)[10]

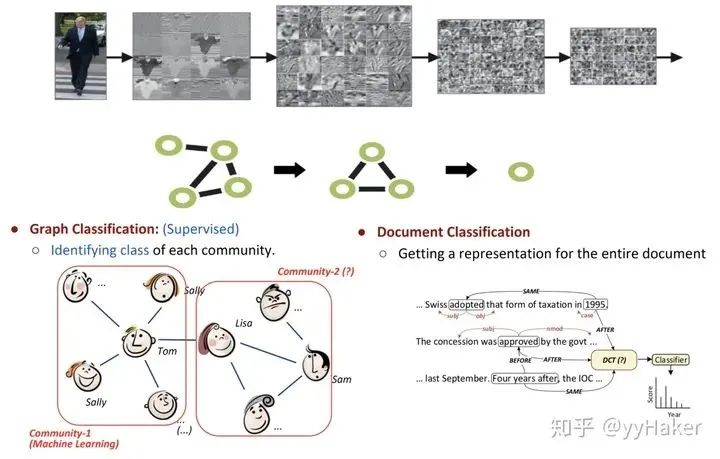
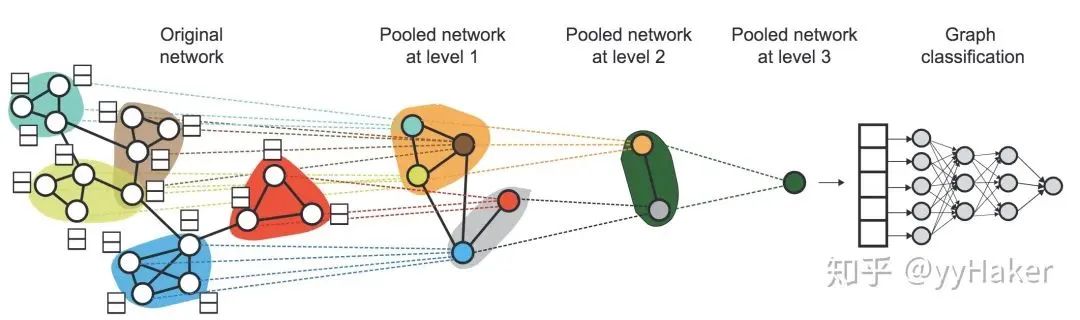
分配矩阵的学习
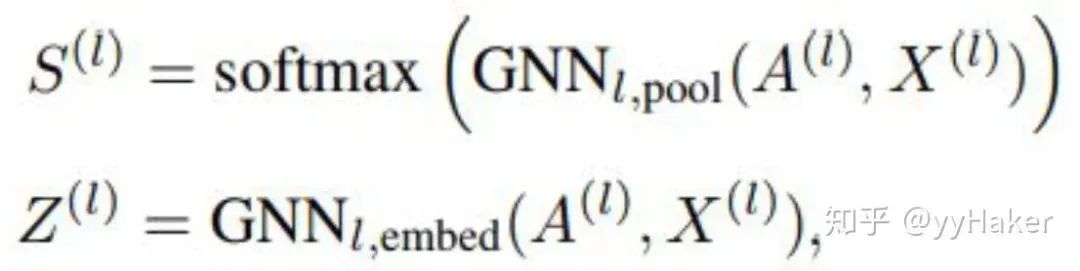
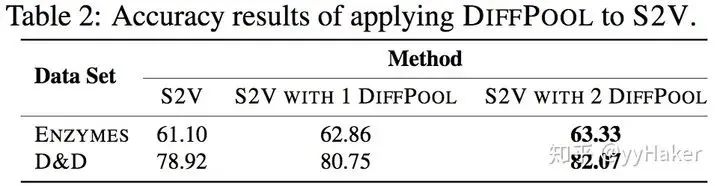
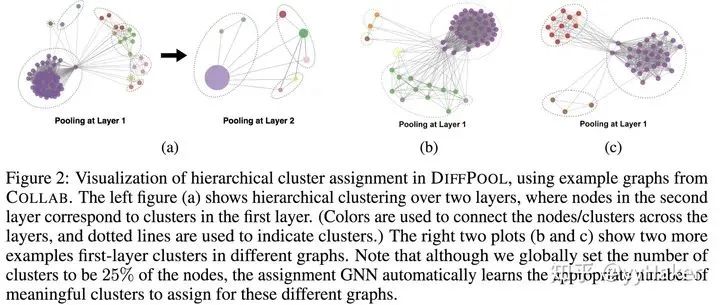
池化分配矩阵
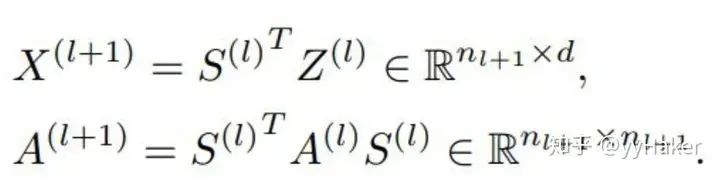
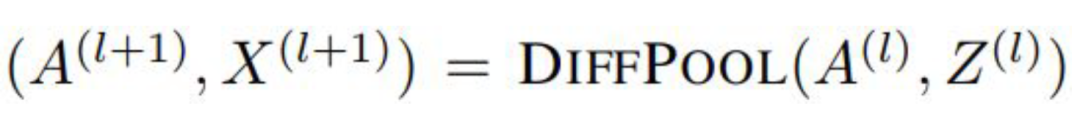
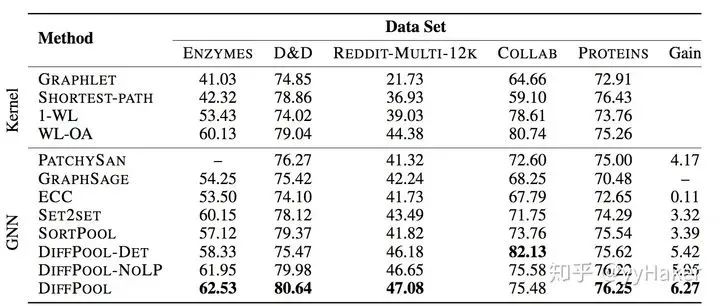
参考
重点总结
—版权声明—
作者:yyHaker@知乎
来源丨https://zhuanlan.zhihu.com/p/136521625
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
评论