
终于有人总结了图神经网络!

来源:Datawhale 本文约6000字,建议阅读10+分钟 本文从一个更直观的角度对当前经典流行的GNN网络,包括GCN、GraphSAGE、GAT、GAE以及graph pooling策略DiffPool等等做一个简单的小结。
一、为什么需要图神经网络?
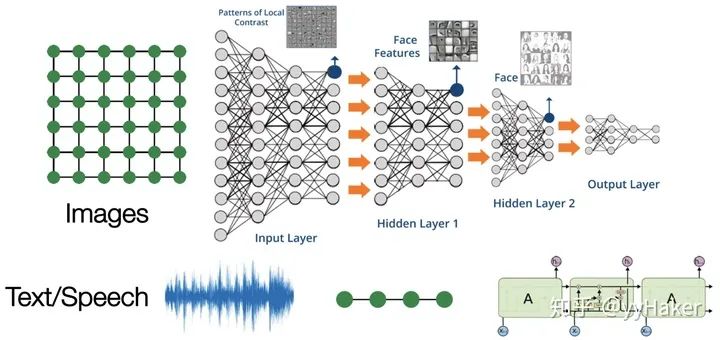
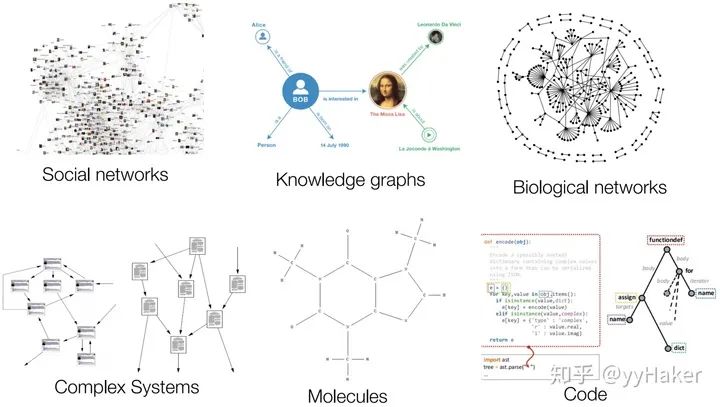
图的大小是任意的,图的拓扑结构复杂,没有像图像一样的空间局部性; 图没有固定的节点顺序,或者说没有一个参考节点; 图经常是动态图,而且包含多模态的特征。
二、图神经网络是什么样子的?
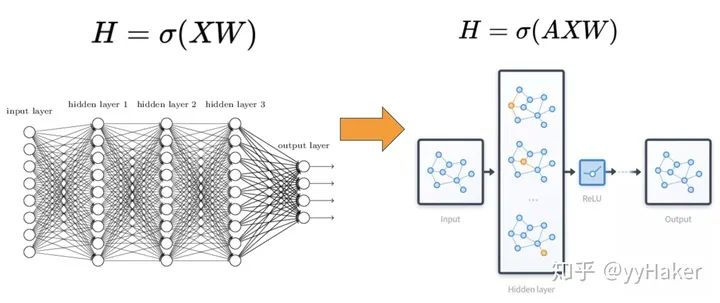
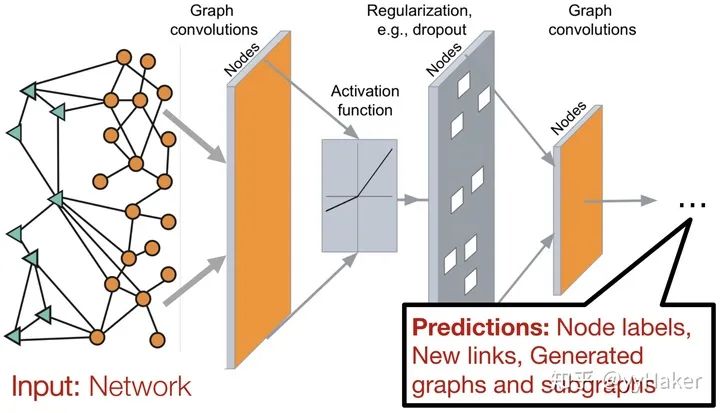
三、图神经网络的几个经典模型与发展
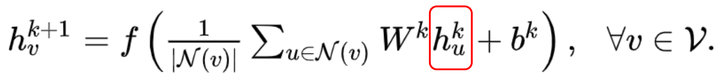
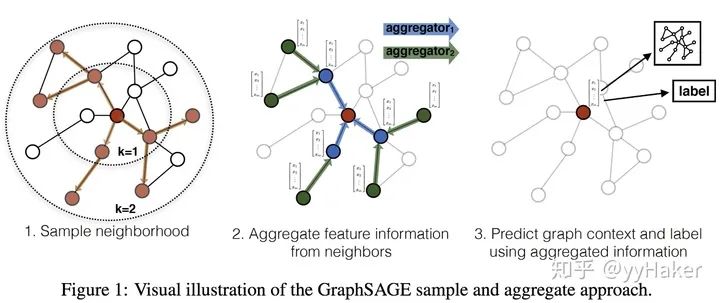



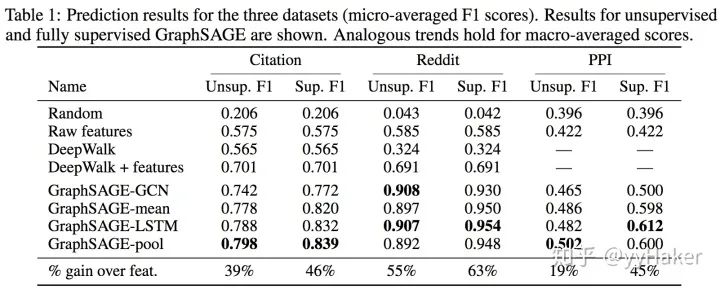
利用采样机制,很好的解决了GCN必须要知道全部图的信息问题,克服了GCN训练时内存和显存的限制,即使对于未知的新节点,也能得到其表示;
聚合器和权重矩阵的参数对于所有的节点是共享的;
模型的参数的数量与图的节点个数无关,这使得GraphSAGE能够处理更大的图;
既能处理有监督任务也能处理无监督任务。
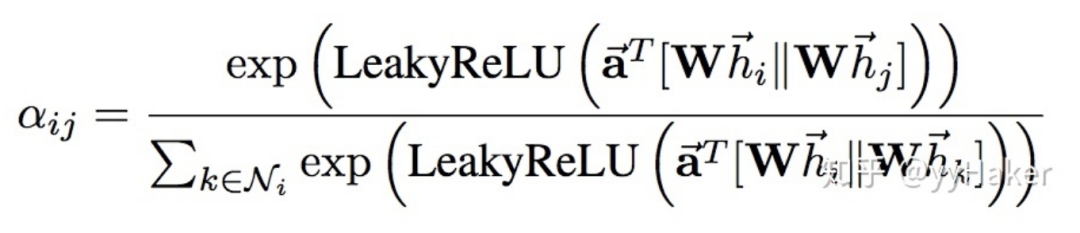
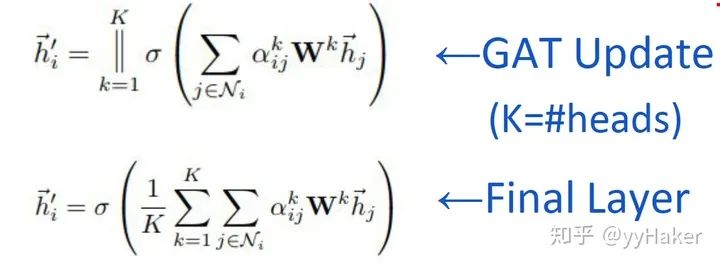
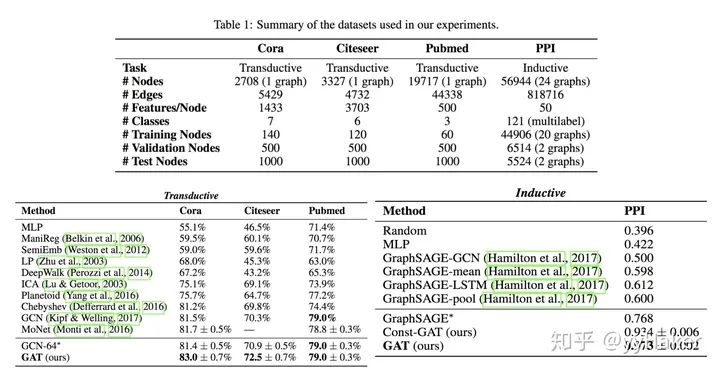
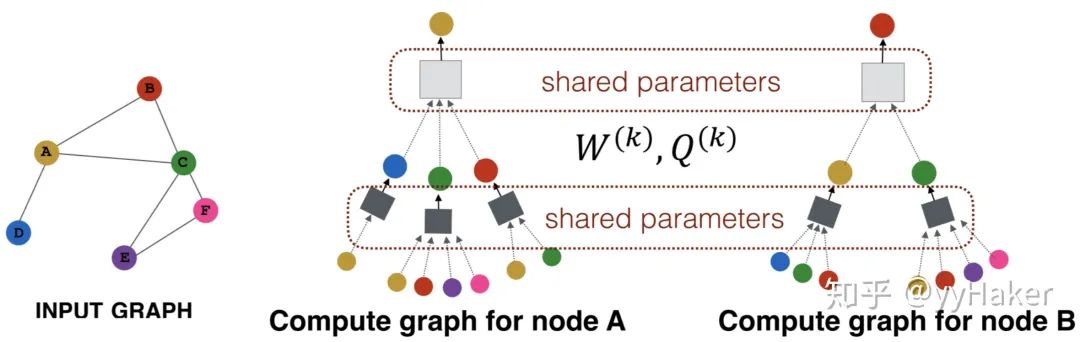
训练GCN无需了解整个图结构,只需知道每个节点的邻居节点即可;
计算速度快,可以在不同的节点上进行并行计算;
既可以用于Transductive Learning,又可以用于Inductive Learning,可以对未见过的图结构进行处理。
到此,我们就介绍完了GNN中最经典的几个模型GCN、GraphSAGE、GAT,接下来我们将针对具体的任务类别来介绍一些流行的GNN模型与方法。
四、无监督的节点表示学习(Unsupervised Node Representation)
由于标注数据的成本非常高,如果能够利用无监督的方法很好的学习到节点的表示,将会有巨大的价值和意义,例如找到相同兴趣的社区、发现大规模的图中有趣的结构等等。
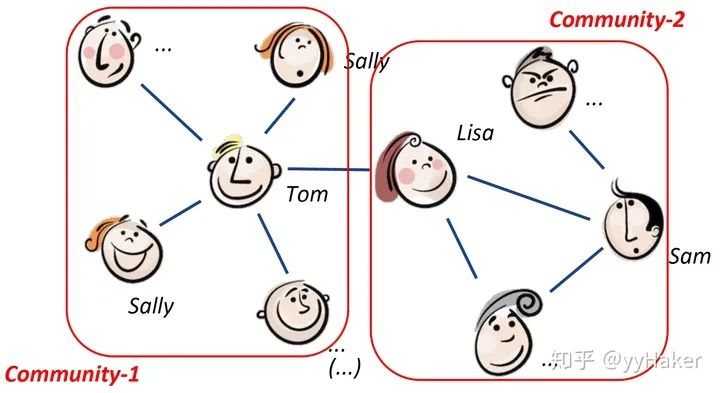
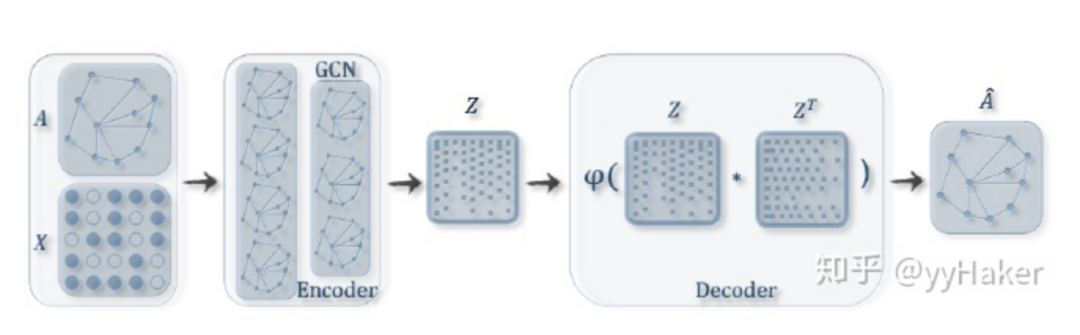

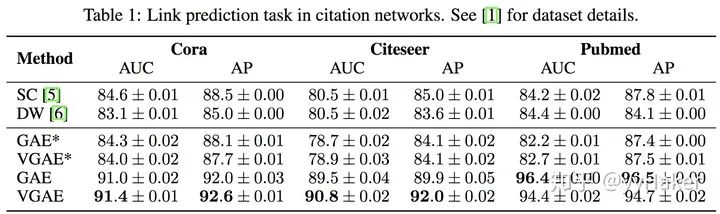
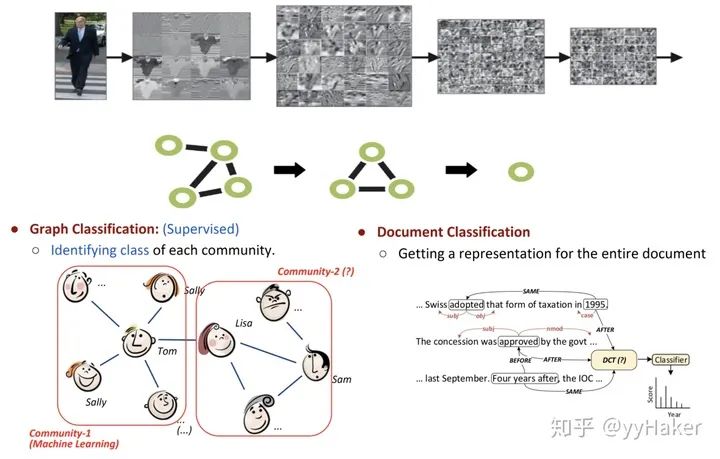
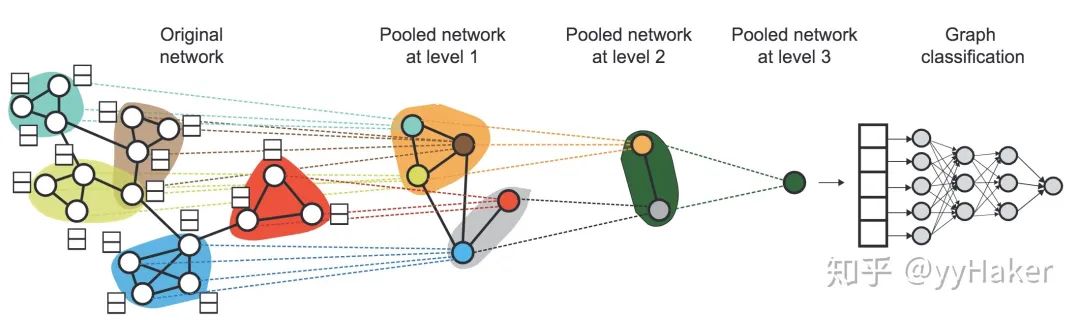
分配矩阵的学习
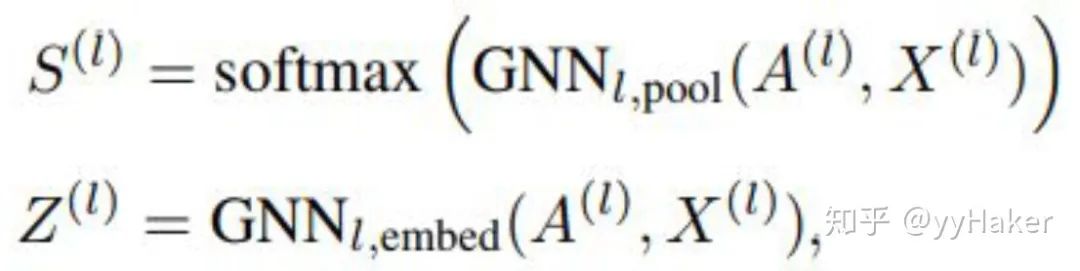
池化分配矩阵
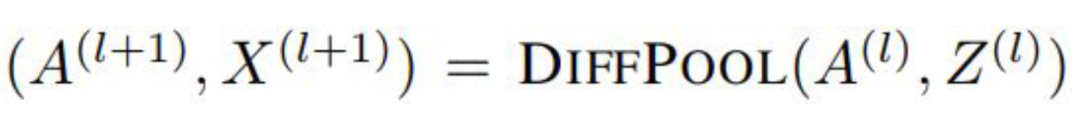
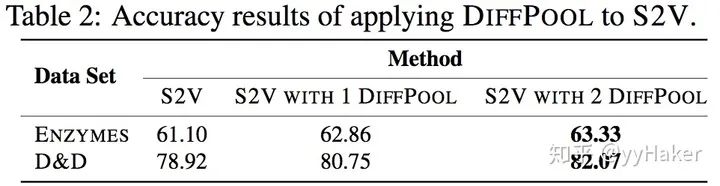
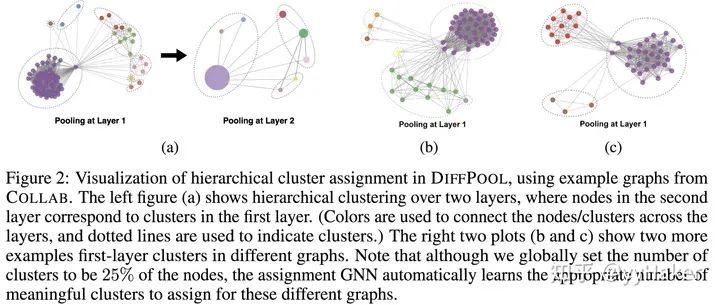
可以学习层次化的pooling策略;
可以学习到图的层次化表示;
可以以端到端的方式被各种图神经网络整合。
参考
【1】^Graph Neural Networks: A Review of Methods and Applications. arxiv 2018 https://arxiv.org/pdf/1812.08434.pdf
【2】^A Comprehensive Survey on Graph Neural Networks. arxiv 2019. https://arxiv.org/pdf/1901.00596.pdf
【3】^Deep Learning on Graphs: A Survey. arxiv 2018. https://arxiv.org/pdf/1812.04202.pdf
【4】^GNN papers https://github.com/thunlp/GNNPapers/blob/master/README.md
【5】^Semi-Supervised Classification with Graph Convolutional Networks(ICLR2017) https://arxiv.org/pdf/1609.02907
【6】^如何理解 Graph Convolutional Network(GCN)?https://www.zhihu.com/question/54504471
【7】^GNN 系列:图神经网络的“开山之作”CGN模型 https://mp.weixin.qq.com/s/jBQOgP-I4FQT1EU8y72ICA
【8】^Inductive Representation Learning on Large Graphs(2017NIPS) https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf
【9】^Graph Attention Networks(ICLR2018) https://arxiv.org/pdf/1710.10903
【10】^Variational Graph Auto-Encoders(NIPS2016) https://arxiv.org/pdf/1611.07308
【11】^VGAE(Variational graph auto-encoders)论文详解 https://zhuanlan.zhihu.com/p/78340397
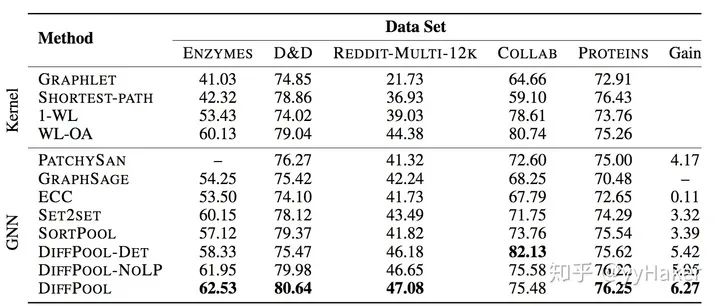
【12】^Hierarchical Graph Representation Learning withDifferentiable Pooling(NIPS2018) https://arxiv.org/pdf/1806.08
重点总结
GCN需要将整个图放到内存和显存,这将非常耗内存和显存,处理不了大图;
GCN在训练时需要知道整个图的结构信息(包括待预测的节点)。
利用采样机制,很好的解决了GCN必须要知道全部图的信息问题,克服了GCN训练时内存和显存的限制,即使对于未知的新节点,也能得到其表示;
聚合器和权重矩阵的参数对于所有的节点是共享的;
模型的参数的数量与图的节点个数无关,这使得GraphSAGE能够处理更大的图;
既能处理有监督任务也能处理无监督任务。
训练GCN无需了解整个图结构,只需知道每个节点的邻居节点即可;
计算速度快,可以在不同的节点上进行并行计算;
既可以用于Transductive Learning,又可以用于Inductive Learning,可以对未见过的图结构进行处理。
编辑:黄继彦