爬虫必备Beautiful Soup包使用详解
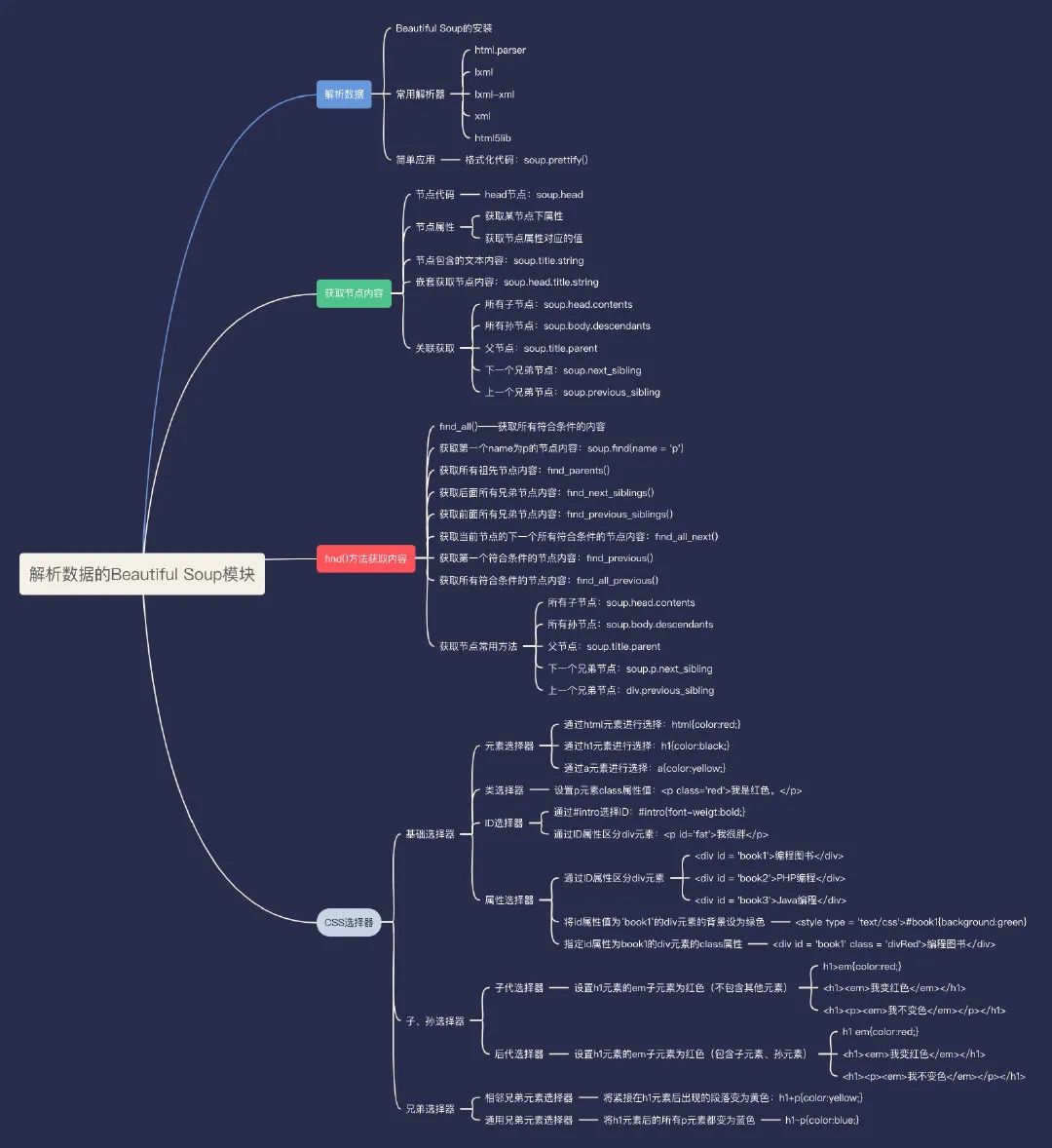
使用Beautiful Soup解析数据
Beautiful Soup是一个用于从HTML和XML文件中提取数据的Python模块。Beautiful Soup提供一些简单的函数用来处理导航、搜索、修改分析树等功能。Beautiful Soup 模块中的查找提取功能非常强大,而且非常便捷。Beautiful Soup自动输入文档转换为Unicode编码,输出文档转换为UTF-8编码。开发者不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。
Beautiful Soup 的安装
目前推荐使用的是Beautiful Soup 4, 已经被移植到bs4当中,需要from bs4 然后导入Beautiful Soup 。
pip install bs4
解析器
Beautiful Soup支持Python标准库中包含的HTML解析器,但它也支持许多第三方Python解析器,其中包含lxml解析器。根据不同的操作系统,您可以使用以下命令之一安装lxml:
§ apt-get install python-lxml
§ easy_install lxml
§ pip install lxml
另一个解析器是html5lib,它是一个用于解析HTML的Python库,按照Web浏览器的方式解析HTML。您可以使用以下命令之一安装html5lib:
§ apt-get install python-html5lib
§ easy_install html5lib
§ pip install html5lib
关于每个解析器的优缺点如下表:
| 解析器 | 用 法 | 优 点 | 缺 点 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, 'html.parser') | Python 标准库执行速度适中 | (在Python2.7.3或3.2.2之前的版本中)文档容错能力差 |
| lxml的HTML解析器 | BeautifulSoup(markup, 'lxml') | 速度快文档容错能力强 | 需要安装C语言库 |
| lxml的XML解析器 | BeautifulSoup(markup, 'lxml-xml') BeautifulSoup(markup,'xml') | 速度快唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, 'html5lib') | 最好的容错性,以浏览器的方式解析文档生成HTML5格式文档 | 速度慢,不依赖外部扩展 |
Beautiful Soup的简单应用
Beautiful Soup安装完成以后,下面将将介绍如何通过Beautiful Soup 库进行HTML的解析工作,具体示例步骤如下:
(1)导入bs4库,然后创建一个模拟HTML代码的字符串,代码如下:
# 作者 :liuxiaowei
# 创建时间 :2/5/22 9:25 PM
# 文件 :使用BeautifulSoup解析HTML代码.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
第一个 HTML 页面
body 元素的内容会显示在浏览器中。
title 元素的内容会显示在浏览器的标题栏中。
"""
(2)创建BeautifulSoup对象,并指定解析器为lxml,最后通过打印的方式将解析的HTML代码显示在控制台当中,代码如下:
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup) # 打印解析的HTML代码
print(type(soup)) # 打印数据类型
程序运行结果如下:
第一个 HTML 页面
body 元素的内容会显示在浏览器中。
title 元素的内容会显示在浏览器的标题栏中。
<class 'bs4.BeautifulSoup'>
说 明
如果将html_doc字符串中的代码,保存在index.html文件中,可以通过打开HTML文件的方式进行代码解析,并且可以通过prettify()方法进行代码的格式化处理,代码如下:
with open('index.html', 'w') as f:
f.write('html_doc')
soup = BeautifulSoup(open("index.html"), "lxml")
print(soup.prettify())
获取节点内容
使用Beautiful Soup 可以直接调用节点的名称,然后再调用对应的string属性便可以获取到节点内的文本信息。在单个节点结构层次非常清晰的情况下,使用这种方式提取节点信息的速度是非常快的。
获取节点对应的代码
示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/5/22 9:25 PM
# 文件 :使用BeautifulSoup解析HTML代码.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
第一个 HTML 页面
body 元素的内容会显示在浏览器中。
title 元素的内容会显示在浏览器的标题栏中。
"""
# 创建一个BeautifulSoup对象,获取页面正文
with open('index.html', 'w') as f:
f.write(html_doc)
soup = BeautifulSoup(open('index.html'), "lxml")
print(soup.prettify())
程序运行结果如下:
head节点内容为:
第一个 HTML 页面
body节点内容为:
body 元素的内容会显示在浏览器中。
title 元素的内容会显示在浏览器的标题栏中。
title节点内容为:
第一个 HTML 页面
p节点内容为:
body 元素的内容会显示在浏览器中。
注 意
在打印p节点对应的代码时,会发现只打印了第一个P节点内容,这说明当多个节点时,该选择方式只会获取第一个节点中的内容,其他后面的节点将被忽略。
说 明
除了通过制订节点名称的方式获取节点内容以外,还可以使用name属性获取节点的名称,示例代码如下:
# 获取节点名称
print(soup.head.name)
print(soup.body.name)
print(soup.title.name)
print(soup.p.name)程序运行结果如下:
head
body
title
p
获取节点属性
每个节点可能都会含有多个属性,例如, class或者id等。如果已经选择了一个指定的节点名称,那么只需要调用attrs即可获取这个节点下的所有属性。代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/6/22 10:17 AM
# 文件 :获取节点属性.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
横排响应式登录
登录
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('meta节点中属性如下:\n',soup.meta.attrs)
print('link节点中属性如下:\n',soup.link.attrs)
print('div节点中属性如下:\n',soup.div.attrs)
print('div节点中input属性如下:\n', soup.div.input.attrs)
程序运行结果如下:
meta节点中属性如下:
{'http-equiv': 'Content-Type', 'content': 'text/html', 'charset': 'utf-8'}
link节点中属性如下:
{'href': 'font/css/bootstrap.min.css', 'type': 'text/css', 'rel': ['stylesheet']}
div节点中属性如下:
{'class': ['glyphicon', 'glyphicon-envelope']}
div节点中input属性如下:
{'type': 'text', 'placeholder': '请输入邮箱'}
在以上的运行结果中可以发现,attrs的返回结果为字典类型,字典中的元素分别是对应属性名称与对应的值。所以
在attrs后面添加[]括号并在括号内添加属性名称即可获取指定属性对应的值。代码如下:
print('meta节点中http-equiv属性对应的值为:', soup.meta.attrs['http-equiv'])
print('link节点中href属性对应的值为:', soup.link.attrs['href'])
print('div节点中class属性对应的值为:', soup.div.attrs['class'])
程序运行结果如下:
meta节点中http-equiv属性对应的值为:Content-Type
link节点中href属性对应的值为:font/css/bootstrap.min.css
div节点中class属性对应的值为: ['glyphicon', 'glyphicon-envelope']
在获取节点中指定属性所对应的值时,除了使用上面的方式外,还可以不写attrs,直接在节点后面以中括号的形式直接添加属性名称,来获取对应的值。代码如下:
print('meta节点中http-equiv属性对应的值为:', soup.meta['http-equiv'])
print('link节点中href属性对应的值为:', soup.link['href'])
print('div节点中class属性对应的值为:', soup.div['class'])
获取节点包含的文本内容
实现获取节点包含的文本内容是非常简单的,只需要在节点名称后面添加string属性即可。代码如下:
print('title节点内包含的文本内容为:', soup.title.string)
print('h3节点所包含的文本内容为:', soup.h3.string)
程序运行结果如下:
title节点内包含的文本内容为: 横排响应式登录
h3节点所包含的文本内容为: 登录
嵌套获取节点内容
HTML代码中的每个节点都会出现嵌套的可能,而使用Beautiful Soup获取每个节点的内容时,以通过“."直接获取下一个节点中的内容(当前节点的子节点)。代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/6/22 11:49 AM
# 文件 :获取嵌套节点内容.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
横排响应式登录
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('head节点内容如下:\n',soup.head)
print('head节点数据类型为:',type(soup.head))
print('head节点中title节点内容如下:\n',soup.head.title)
print('head节点中title节点数据类型为:',type(soup.head.title))
print('head节点中title节点中的文本内容为:',soup.head.title.string)
print('head节点中title节点中文本内容的数据类型为:',type(soup.head.title.string))
程序运行结果如下:
head节点内容如下:
横排响应式登录
"utf-8" content="text/html" http-equiv="Content-Type"/>
"width=device-width" name="viewport"/>
"font/css/bootstrap.min.css" rel="stylesheet" type="text/css"/>
"css/style.css" rel="stylesheet" type="text/css"/>
head节点数据类型为: <class 'bs4.element.Tag'>
head节点中title节点内容如下:
<title>横排响应式登录title>
head节点中title节点数据类型为: <class 'bs4.element.Tag'>
head节点中title节点中的文本内容为: 横排响应式登录
head节点中title节点中文本内容的数据类型为: <class 'bs4.element.NavigableString'>
说 明
在上面的运行结果中可以看出,在获取head与其内部的title节点内容时数据类型均为“
关联获取
在获取节点内容时,不一定都能做到一步获取指定节点中的内容,有时还需要先确认某一个节点,然后以该节点为中心获取对应的子节点、孙节点、父节点以及兄弟节点。
• 1、获取子节点
在获取某节点下面的所有子节点时,可以使用contents或者是children属性来实现,其中contents返回的是一个列表,在这列表中的每个元素都是一个子节点内容,而children返回的则是一个"list_iterator"类型的可迭代对象。获取所有子节点的代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/6/22 1:18 PM
# 文件 :实现获取某节点下所有子节点内容.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
关联获取演示
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.head.contents) # 列表形式打印head下所有子节点
print(soup.head.children) # 可迭代对象形式打印head下所有子节点
程序运行结果如下:
['\n', 关联获取演示 , '\n', "utf-8"/>, '\n']
0x7f7cf94fcfa0>
从上面结果可以看出,通过head.contents所获取的所有子节点中有三个换行符\n以及两个子标题(title与meta)对应的所有内容。head.children所获取的则是一个'list_iterator'可迭代对象,如果需要的获取该对象中的所有内容可以直接将其转换为list类型或者通过for循环遍历的方式进行获取。代码如下:
print(list(soup.head.children)) # 打印将可迭代对象转换为列表形式的所有子节点
for i in soup.head.children: # 循环遍历可迭代对象中的所有子节点
print(i) # 打印子节点内容
程序运行结果如下:
['\n', 关联获取演示 , '\n', "utf-8"/>, '\n']
关联获取演示
"utf-8"/>
• 2、获取孙节点
在获取某节点下面所有的子孙节点时,可以使用descendants属性来实现,该属性会返回一个generator对象,获取该对象中的所有内容时,同样可以直接将其转换为list 类型或者通过for循环遍历的方式进行获取。这里以for循环遍历方式为例,代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/6/22 2:06 PM
# 文件 :使用descendants属性获取子孙节点内容.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
…此处省略…
此处为演示信息
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.body.descendants) # 打印body节点下所有子孙节点内容的generator对象
for i in soup.body.descendants: # 循环遍历generator对象中的所有子孙节点
print(i) # 打印子孙节点内容
程序运行如下:
所有子孙节点内容的generator对象
0x7ff1b24f3580>
此处为演示信息
li>
ul>
div>
div>body节点下所有子节点内容 body节点下所有孙节点及以下内容
此处为演示信息
li>
ul>
div>
<ul>
<li class="test3" value="user1234">
此处为演示信息
li>
ul>
<li class="test3" value="user1234">
此处为演示信息
li>
此处为演示信息
• 3.获取父节点
获取父节点有两种方式:一种是通过parent属性直接获取指定节点的父节点内容,还可以 通过parents属性获取指定节点的父节点及以上(祖先节点)内容,只是parents属性会返回一个generator对象,获取该对象中的所有内容时,同样可以直接将其转换为list类型或者通过for 循环遍历的方式进行获取。这里以for循环遍历方式为例,代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/6/22 2:34 PM
# 文件 :获取父节点及祖先节点内容.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
关联获取演示
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.title.parent) # 打印title节点的父节点内容
print(soup.title.parents) # 打印title节点的父节点及以上内容的generator对象
for i in soup.title.parents: # 循环遍历generator对象中的所有父节点及以上内容
print(i.name) # 打印父节点及祖先节点名称
直接获取title节点的父节点内容
关联获取演示
"utf-8"/>
父节点及以上内容的generator对象
0x7fb0b8df36d0>
循环遍历父节点及祖先节点的名称
head
html
[document]
说 明
在上面的运行结果可以看出,parents属性所获取父节点的顺序为head,html,最后的[document]表示文档对象,既是整个HTML文档,也是BeautifulSoup对象。
• 4、获取兄弟节点
兄弟节点也就是同级节点,表示在同一级节点内的所有子节点间的关系。如,在一段HTML代码中获取第一个p节点的下一个div兄弟节点时可以使用next_sibling属性,如果想获取当前div节点的上一个兄弟节点p时可以使用previous_sibling属性。通过这两个属性获取兄弟节点时,如果两个节点之间含有换行符(\n)、空字符或者是其他文本内容时,将返回这些文本节点。代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/6/22 8:16 PM
# 文件 :获取兄弟节点.py
# IDE :PyCharm
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
关联获取演示
零基础学Python
第一个p节点下文本
Python从入门到项目实践