
单目标跟踪paper小综述
点击左上方蓝字关注我们

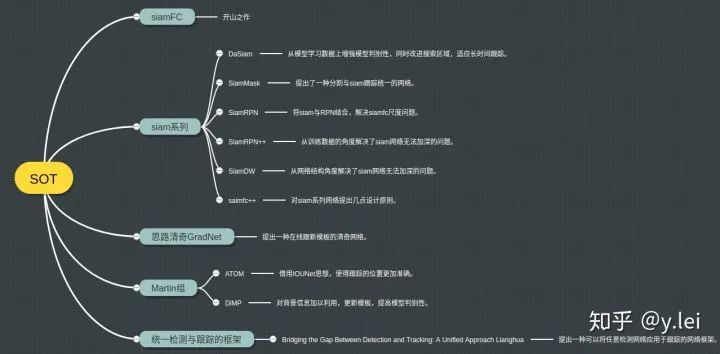
为了方便自己梳理脉络同时和大家交流讨论,将一些重要的paper整理在这。首先用一张图罗列下本文涉及到的paper:
一. 关于单目标跟踪
本人不了解传统的相关滤波法,所有想法总结仅仅建立在深度学习的基础上。对于单目标跟踪而言一般的解释都是在第一帧给出待跟踪的目标,在后续帧中,tracker能够自动找到目标并用bbox标出。关于SOT(single object track),有两条思路。第一种,我们可以把跟踪粗暴地当做一个配对问题,即把第一帧的目标当做模板,去匹配其他帧。基于这种思路,网络并不需要“理解”目标,只需当新的一帧图像来到时,拿着模板“连连看”找相同就可;siam系列实质上就是这个思路,每次两个输入,模板和新图片,然后通过网络在新图片上找和模板最相似的东西,所以这条思路的关键在于如何配得准。另一种思路是通过第一帧给出的目标“理解”目标,在后续帧中,不需要再输入模板,即只有一个输入,网络可以根据自己理解的模板,在新图片中预测出目标,所以这条思路的关键在于如何让网路仅仅看一眼目标(第一帧)就能向目标检测那样,“理解”目标,这就涉及到单样本学习问题,也是检测和跟踪的gap。
二. SiamFC
目前基于siamese系列的网络已经占据了单目标跟踪大半壁江山。这一切都源于2016年siamFC的提出,siamfc实际上就是将跟踪当做匹配问题,下面具体介绍siamfc。
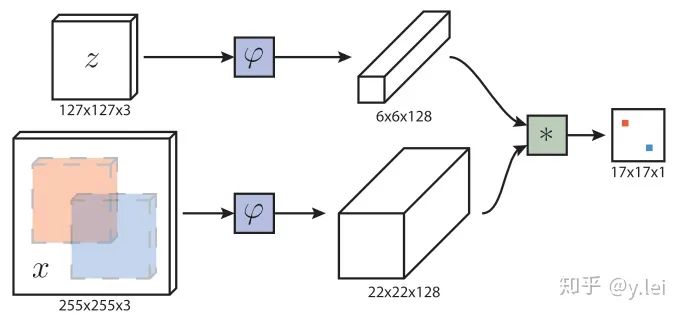
首先简单介绍下siamfc的网络框架,图中z是模板(即待跟踪的目标),x是当前帧的图像,  是用于提取图像特征的卷积网络,因为作用于x(srch_img)的与作用于z(template)的完全一样所以称为孪生网络(siamese),经过卷积网络提取特征后分别得到x和z的feature map,然后将二者卷积(
是用于提取图像特征的卷积网络,因为作用于x(srch_img)的与作用于z(template)的完全一样所以称为孪生网络(siamese),经过卷积网络提取特征后分别得到x和z的feature map,然后将二者卷积(  表示卷积),即将6×6×128的feature map当做卷积核,在22×22×128上进行卷积得到17×17×1的heatmap,heatmap上值最大的点就对应于x图像中目标的中心。
表示卷积),即将6×6×128的feature map当做卷积核,在22×22×128上进行卷积得到17×17×1的heatmap,heatmap上值最大的点就对应于x图像中目标的中心。
下面说一些细节,首先网络是5层不带padding的AlexNet。显然5层不符合深度学习“深”的理念,但是由于网络不能加padding所以限制了网络深度,为什么不能padding呢,事实上target在x上的位置,我们是从heatmap得到,这是基于卷积的平移等变性,即target在x上平移了n,相应的就会在heatmap上平移n/stride,且值不会变。但如果加入了padding,对于图像边缘的像素,虽然也会平移,但值会变,因为padding对图像的边缘进行了改变。siamRPN++和siamDW解决了这个问题,后面会详细讲。然后是训练时,x和z的获取方式:z是以第一帧的bbox的中心为中心裁剪出一块图像,再将这块图像缩放到127×127,255×255的srchimg也是类似得到的。这里有几个细节需要注意,第一,template与srch_img的中心就是目标的中心,且template是裁剪过的,如果不裁剪那么template中背景过多,导致匹配失败。不过在siamfc中背景信息完全被丢弃,换句话说,siamfc对缺乏对背景的利用,也导致模型的判别性不足,后续有相关工作对此进行改进。第二,训练阶段的标签怎么得到呢,如果只是简单将目标所在位置标为1,其他位置标为0,就会产生严重的样本不均衡问题,于是作者将离目标中心点r半径内的label都设置为1,其他设为0,loss function为  ,y为预测值,v为标签值,这里关于label的设置也有一些可以优化的点,使用focal loss是否对模型的判别性是否会更高呢。第三,在测试时,siamfc的template是不更新的,即一直为第一帧,这就导致模型的鲁棒性不佳,例如随着时间的变化template出现遮挡、模糊等情况,但是如果更新策略不佳又会引入模板污染、过拟合等问题,在这方面也有相关工作讨论。在测试时,首先搜索区域不是整个srchimg而只是之前的四倍大小的搜索区域,其次在feature map上加了余弦窗,最后为了解决尺度问题,对srch_img进行缩放了3种尺度。
,y为预测值,v为标签值,这里关于label的设置也有一些可以优化的点,使用focal loss是否对模型的判别性是否会更高呢。第三,在测试时,siamfc的template是不更新的,即一直为第一帧,这就导致模型的鲁棒性不佳,例如随着时间的变化template出现遮挡、模糊等情况,但是如果更新策略不佳又会引入模板污染、过拟合等问题,在这方面也有相关工作讨论。在测试时,首先搜索区域不是整个srchimg而只是之前的四倍大小的搜索区域,其次在feature map上加了余弦窗,最后为了解决尺度问题,对srch_img进行缩放了3种尺度。
三. Siam系列
1. SiamRPN
SiamRPN是CASIA在2018提出来的网络,它将siam与检测领域的RPN进行结合。关于RPN(faster RCNN)可以参看faster RCNN,这篇帖子写得非常好。在检测领域RPN本意是用作检测,它将feature map上的各个点当做锚点,并映射到映射到输入图片上,再在每个锚点周围取9个尺度不同的锚框,对每个锚框进行检测是否有物体以及位置回归。
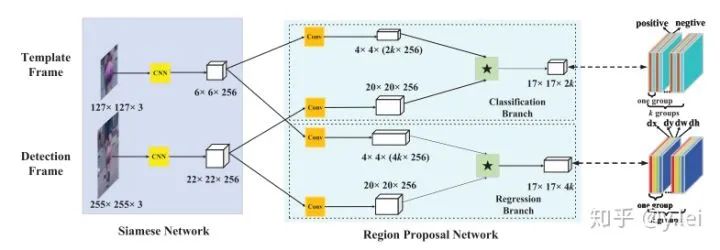
siamRPN的网络框架见上图,这里可以从one-shot的思路理解sianRPN,我们把template分支的embedding当作卷积核,srch_img分支当作feature map,在template与srchimg卷积之前,先将卷积核(即template得到的feature map)通过1*1卷积升维到原来的2k(用于cls)和4k(用于位置的reg)倍。然后拉出分类与位置回归两个分支。(建议没看多RPN的朋友看下上面推荐的那篇讲faster rcnn的帖子,看完这里就自然懂了)。这里的anchor到底是什么呢,根据笔者粗浅的理解,siamfc相当于直接将template与srching直接卷积匹配,而siamRPN在template上引入k个anchor相当于选取了k个尺度与srch_img进行匹配,解决了尺度问题。(笔者对anchor的理解还不够深入,后面深入研究下再写一篇文章专门探讨anchor的本质及其优缺点)
siamRPN无论是在A还是R上都优于siamfc(这里补充一下,对于跟踪而言主要有两个子指标A(accuracy)与R(robust), A主要是跟踪的位置要准,R主要是模型的判别性要高,即能够准确识别哪些是目标,从而判断出目标的大致位置。关于R与A可参见VOT评价指标),也就是说siamrpn的模型判别性与准确性都比siamfc好,结果见下图。
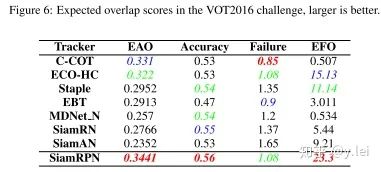
笔者认为,准确性的提升主要来自与siamrpn将位置回归单独拉出来作为一个分支,这一点在后续的siamfc++中也可以看到作者相关的论述。在模型判别性方面,笔者认为,提升的关键在于siamrpn在进行匹配(即template与srchimg卷积的过程)时,由于引入了k个anchors,相当于从k个尺度对template与srch_img进行更加细粒度的匹配,效果更好也是情理之中。另外很重要的一点就是sianrpn解决了尺度问题。
2. DaSiamRPN
关于这篇文章,笔者之前在github上做过一些笔记,这里就简单摘录一些,具体笔记见DaSiamRPN。
DasiamRPN并没有对siamfc的网络结构进行过多的改进,而是从训练数据,模板更新,搜索区域三个角度对模型的rubost进行了提升。使得SiamRPN网络能够适应长期跟踪。
首先作者对siamrpn的缺点进行了分析,主要有三点:
在训练阶段,存在样本不均衡问题。即大部分样本都是没有语义的背景(注:背景不是非target的物体,而是指那些既不属于target,也不属于干扰物,没有语义的图像块,例如大片白色。)这就导致了网络学到的仅仅是对于背景与前景的区分,即在图像中提取出物体,但我们希望网络还能够识别target与非target物体。作者从数据增强的角度解决此问题。
模型判别性不足,缺乏模板的更新,即在heatmap中很多非target的物体得分也很高;甚至当图像中没有目标时,依然会有很高的得分存在。作者认为与target相似的物体对于增强模型的判别性有帮助,因此提出了distractor-aware module对干扰(得分很高的框)进行学习,更新模板,从而提高siam判别性。但是排名靠前的都是与target很相似的物体,也就是说该更新只利用到了target的信息,没有利用到背景信息。
由于第二个缺陷,原始的siam以及siamRPN使用了余弦窗,因此当目标丢失,然后从另一个位置出现,此时siam不能重新识别target, (siamRPN的搜索区域是上一阵的中心加上预设的搜索区域大小形成的搜索框),该缺陷导致siam无法适应长时间跟踪的问题。对此作者提出了local-to-global的搜索策略,其实就是随着目标消失帧数的增加,搜索区域逐渐扩大。
针对这三个问题,作者给出了相应的解决方案。首先对于数据问题,当然是使用数据增强,主要方法有:增加训练集中物体的类别;训练时使用来自同一类别的负样本,以及来自不同类别的正样本辅助训练;增加图像的运动模糊。关于template的更新问题,作者对heatmap得到目标先NMS去除一些冗余框,然后将相似度靠前的框(干扰物)拿出来,让网络对其学习,拉大target_embedding与这些干扰物之间的相似度。这样的优点在于既综合了当前帧的信息,同时因NMS靠前的都与目标很相似,这就抑制了模板污染问题。
3. siamMask
关于siamMask,先放一张效果图,就可以知道他做的是什么工作。

简单来说siamMask就是将跟踪与分割结合到了一起,从其结果上,相比与之前的视频分割工作,其提升了速度,相比与之前的DasaimRPN其提升了A与R.

这里不对分割进行探讨,仅从跟踪的角度来看,笔者认为saimMask的提升相比与siamRPN主要来源与多任务学习(即更加精细的像素级的数据集与学习任务)。
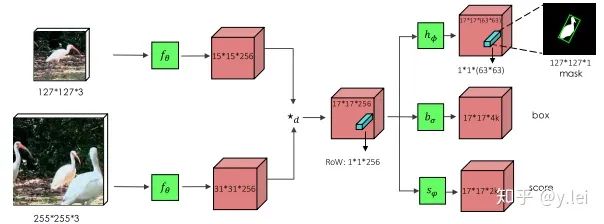
上图是siamMask的网络框架,从中我们也可以看出,就网络本身而言,siamMask只是比siamRPN多了一个(分割)分支,即多了一个学习任务。
4. siamRPN++
siamRPN++可以说是将siam系列网络又推向一个高峰,它解决的是如何将siam网络加深的问题。笔者在写siamfc那部分时提到,siamfc中的backbone使用的是只有5层的AlexNet,且不含padding, 其实在siamrpn的backbone也很浅。这是因为网络不能加padding, 不能加padding,那么随着网络深度的增加,feature map就会越来越小,特征丢失过多。而加padding则会破坏卷积的平移等变性。在siamrpn++中,作者是从实验效果的角度对padding进行探究。作者认为padding会给网络带来空间上的偏见。具体来说,padding就是在图片边缘加上黑边,但是黑边肯定不是我们的目标,而黑边总是在边缘,那么对于神经网络来说,它就会认为边缘都不是目标,即离边缘越远的越可能是目标。这就导致了神经网络总是习惯认为图像中心的是目标,而忽视目标本身的特征,而siamfc的训练方法target也确实是在图片中央。(这里需要指明的是,在siamfc的训练过程中,总是让template与srch_img处于图片的中央,作者在siamfc中说因为他们使用了全卷积的结构,所以在siamfc中不会有空间上的bias,显然这里的结果和siamrpn++的结果有矛盾,这也是笔者在写这篇贴子时想到的,siamfc到底有没有空间的bias还有待笔者代码测试,也欢迎评论区小伙伴讨论。)
回到siamrpn++上来,有了上面的分析,解决办法自然也就有了,既然网络总是习惯认为中心是目标,那让target不要总是在图片中央不就好了,于是siamrpn++最大的贡献就产生了,在训练时让目标相对于中心偏移几个像素,论文中实验表明偏移64个像素最佳.
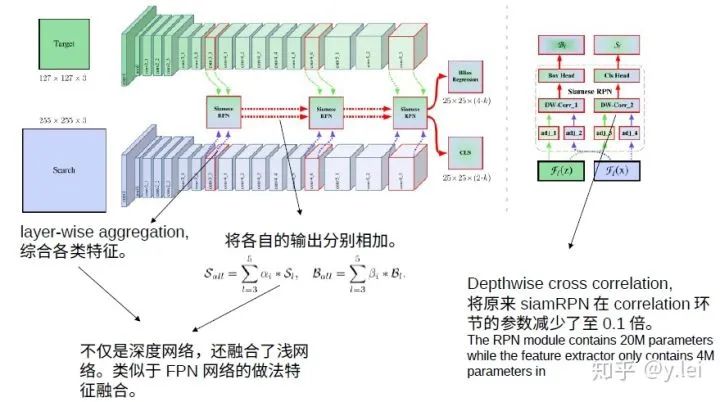
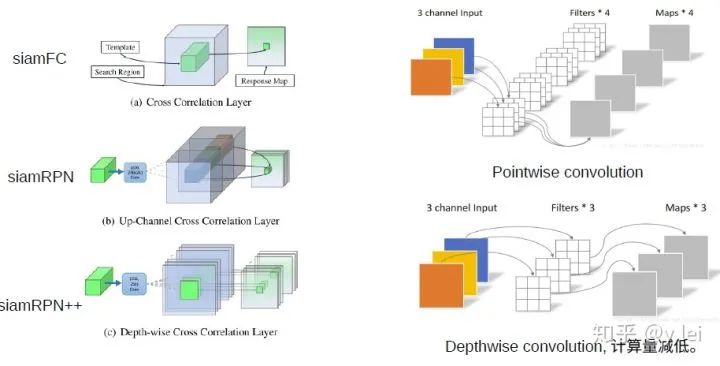
关于网络结构方面,siamrpn++也在siamrpn的基础上做了一些改进,见上图,首先当然是加深backbone,论文中使用了resNet50。此外在核相关环节,siamrpn是直接将template与srch_img的经过backbone后的embedding都先升维至原来的2k倍和4k倍,这样做的缺点是参数量的不平衡,即在核相关环节的参数量是其余环节的4倍,这为训练增加了难度(为什么增加了难度?)。这种参数量的不平衡主要来自与核相关的卷积操作,因此siamrpn++使用depthwise cross correlation的卷积方式,用下面这张网上截来的图来说明这种操作。
除此之外,siamrpn++还综合了更多的特征,见网络框架图。这中融合使得网络学会更多的图像特征,在最近的siamCAR中也使用了类似的方法,分刷得很高,看来特征融合确实是提分利器。
最后放下siamrpn++的测试结果,

不得不承认,siamrpn++的EAO(综合了A和R的指标)还真是高得惊人,不过仔细看A与R可以发现,siamrpn++的Accuracy非常出众,但robustness提升空间还很大,也就是说,网络的判别性并没有那么惊艳,但是讲道理网络深度加深而且还有特征融合的助力,最受益的应该就是R,这其中原因还有待笔者跑跑代码再做评论(盲猜是不是模板未更新的缘故,然而加入了模板更新的Dasiamrpn的R值更高)。
5. siamDW
与siamrpn++一样siamDW也是解决siam系列网络深度的问题,两篇都同为CVPR2019的oral。
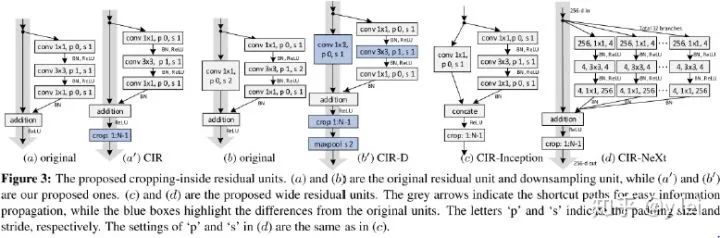
siamDW认为siam系列网络不能加深原因有二:第一,随着网络深度的增加,网络的感受野增加,从而减少了网络的判别性与回归的准确度;第二,padding会引入spatial bias,因为如果使用padding的话,对于卷积核(template)来说是一定带来说是一定带padding,而对于search image中间部分是没有padding的,只有边缘的才有padding,作者认为这会导致不连续,导致对于search image边缘的目标识别很差。因此本文的作者从两个方面探究了加深siam系列网络的办法:第一,感受野的问题,作者探究发现siam系列网络prefer small stride,4~8最宜,同时网络最后的感受野最好在整幅exemplar的60%至80%最佳,stride也要根据这个来调整;针对padding问题,作者设计了一种新的残差网络结构,先padding,得到feature map后再删除feature map上受padding影响元素。
再来看下结果
6. siamFC++
针对siam网络分析了之前的工作不合理的地方,提出了4条guidelines,并就这4条guidelines对siamfc进行了改进,个人认为这几点guidelines非常有意义。
跟踪网络分为两个子任务,一个是分类,一个是位置的准确估计。即网络需要有分类与位置估计两个分支。缺少分类分支,模型的判别性会降低,表现到VOT评价指标上就是R不高;缺少位置估计分支,目标的位置准确度会降低,表现到VOT评价指标上就是A不高。
分类与位置估计使用的feature map要分开。即不能分类的feature map上直接得到位置的估计,否则会降低A。
siam匹配的要是原始的exemplar,不能是与预设定的anchors匹配,否则模型的判别性会降低,siamFC++的A值略低于siamRPN++,但是R值在测试过的数据集上都比siamRPN++高,作者认为就是anchors的原因,在论文的实验部分,作者进行了实验发现siamRPN系列都是与anchors进行匹配而不是exemplar本身,但是anchors与exemplar之间存在一些差异,导致siamRPN的鲁棒性不高。
不能加入数据分布的先验知识,例如原始siamFC的三种尺度变换,anchors等实际上都是对目标尺度的一种先验,否则会影响模型的通用性。

网络结构如上图,值得注意的是siamfc++未使用anchors那么她是怎么解决尺度问题的呢,笔者在论文中似乎未见到作者关于这方面的提及,如果有朋友注意到还请在评论区告知,此外作者在论文中说他们追随了“per-pixel prediction fashion”,这是指什么也还有待开源代码后笔者再研究下。
另外值得注意的是作者在训练时是如何定义正副样本的。作者认为落在bbox内部的点都算positive,在计算loss时,只考虑positive的点,在对位置回归时,作者实验发现PSS loss比IOU loss高0.2个点,所以位置回归分支使用PSS loss,分类分支使用focal loss,quality分支使用BCE(即作者使用了两种不同的loss来训练分类分支)。在训练时,只使用了positive的点,该模型对背景的区分度可能不够(还是要运行代码看呀),如果把背景也加上会不会进一步提升模型的判别性。跟踪不仅仅是单纯的根据exemplar图像本身特征寻找,目标周围的环境对跟踪也有帮助,对loss进行改进。
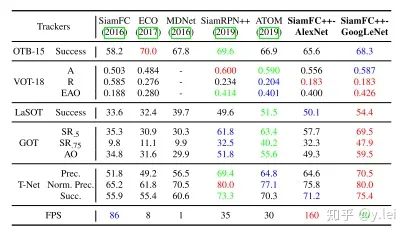
最后看下消融实验以及最后的结果

由该图可以看到siamFC++改进的各部分对于最后结果的提升(与原始的siamFC比较),位置回归对EAO提升最大,the regression branch (0.094), data source diversity (0.063/0.010), stronger backbone (0.026), and better head structure (0.020).
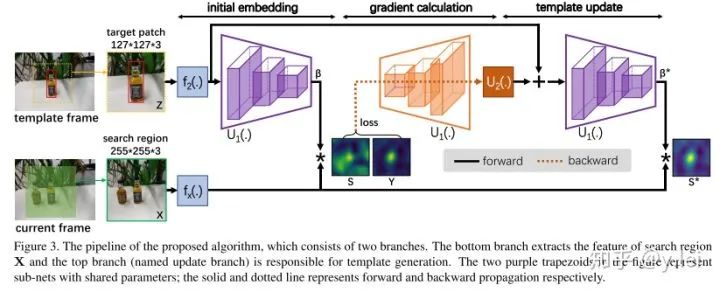
四. GradNet
GradNet主要解决的是网络在线更新template的问题,对于template的更新主要有两种一种是类似与Dasiamrpn融合template,另一种是梯度下降对template进行修正。作者的方法对标第二种,第二种最大的缺点在于要迭代很多次,GradNet思路清奇的训练了一个网络来替代这么多次梯度下降迭代优化。
关于这篇论文的笔记,请参考我在github上写的GradNet笔记
五. 统一检测与单目标跟踪的网络
详细笔记同样参见我在github上写的统一检测与单目标跟踪笔记
首先阐述下笔者关于将检测直接应用到单目标跟踪领域的难点:
如何将exemplar与srch img 融合到一起,目的就是告诉网络需要跟踪的对象,实际上也就是作者提出的第一个难点。
网络不可能提前知道要跟踪的目标从而进行相应的训练,如何使得网络能够识别出“临时”挑选的目标。采用meta-learning的方法如何避免过拟合。
siam成功的地方在于将上述两个问题转化为匹配问题,即在srch img中匹配exemplar,siam的问题在于网络的判别性,即不会匹配到背景,另外exemplar是否更新,如何更新,尺度变换问题如何解决。
然后这篇论文对于这几个问题的解决方案summary是:
提出了target-guidance module(TGM)将exemplar图像融合到检测的feature map里。
在线学习Meta-learning对classification head微调。
在线更新权重
anchored updating strategy减少Meta-learning的overfitting。

参考文献
[1]SiameseFC:Luca Bertinetto, Jack Valmadre, João F. Henriques, Andrea Vedaldi, Philip H.S. Torr. "Fully-Convolutional Siamese Networks for Object Tracking." ECCV workshop (2016).
[2]SiamRPN:Bo Li, Wei Wu, Zheng Zhu, Junjie Yan. "High Performance Visual Tracking with Siamese Region Proposal Network." CVPR (2018Spotlight).
[3]DaSiamRPN:Zheng Zhu, Qiang Wang, Bo Li, Wu Wei, Junjie Yan, Weiming Hu."Distractor-aware Siamese Networks for Visual Object Tracking." ECCV (2018).
[4]SiamDW:Zhipeng Zhang, Houwen Peng."Deeper and Wider Siamese Networks for Real-Time Visual Tracking." CVPR (2019oral).
[5]SiamMask:Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, Philip H.S. Torr."Fast Online Object Tracking and Segmentation: A Unifying Approach." CVPR (2019).
[6]SiamRPN++:Bo Li, Wei Wu, Qiang Wang, Fangyi Zhang, Junliang Xing, Junjie Yan."SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks." CVPR (2019oral).
[7]GradNet:Peixia Li, Boyu Chen, Wanli Ouyang, Dong Wang, Xiaoyun Yang, Huchuan Lu."GradNet: Gradient-Guided Network for Visual Object Tracking." ICCV (2019oral).
[8]Lianghua Huang, Xin Zhao, Kaiqi Huang."Bridging the Gap Between Detection and Tracking: A Unified Approach." ICCV (2019).
[9]Yinda Xu,Zeyu Wang,Zuoxin Li,Yuan Ye,Gang Yu."SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines." AAAI 2020
END
整理不易,点赞三连↓