
单目标跟踪方法-Siam系列
作者: 晟 沚
跟踪的定义:在第一帧中给定目标框,在后续帧中不断对目标定位,实际上是一个one-shot learning过程。
一般流程:
1)Trackingby online-learning用第一帧给定的label训练一个分类器,后续帧使用此分类器判别是否是目标,后续不断更新训练分类器
2)Similaritylearning 和第一帧判断,得到精确的目标估计需要很多例子,每采集的例子需要特征计算,耗时
3)Fully-convolutional Siamese 使用全卷积方式简化计算相关性,达到80fps,有数据驱动
VOT算法分类
VOT相关算法通常分为生成式(generative model)和判别式(discriminative model)。
生成式:采用特征模型描述目标的外观特征,再最小化跟踪目标与候选目标之间的重构误差来确认目标。此方法着重于目标本身的特征提取,忽略目标的背景信息,因而在目标外观发生剧烈变化或者遮挡时,容易出现目标漂移或目标丢失。
判别式:将目标跟踪看做一个二元分类问题,通过训练关于目标和背景的分类器来从候选场景中确定目标,可以显著区分背景和目标,性能鲁棒,渐渐成为目标跟踪领域主流方法,目前大多数基于深度学习的目标跟踪算法都属于判别式方法。
传统的单目标跟踪算法多为在线跟踪,在线更新模型(KCF)。这种方法的好处就是速度快,但是跟踪质量并不是很高,而深度学习方法多为离线训练,在线跟踪,这样做的好处就是跟踪质量好,但是速度比不上相关滤波的方法,但是从这篇SiamFC论文开始,基于深度学习的方法在速度上已经可以和传统的相关滤波并驾齐驱,甚至更优
单目标跟踪的性能其实主要依靠特征对比和逻辑推理。特征对比是多数工作的主流方向,因为在已知第一帧目标图像前提下,定位下一帧目标位置的最直观方法是把下一帧图像以滑动窗为单位(或者以物体proposal为单位)与目标图像特征进行比对,特征最相近便认为是目标物体。
难点:
目标出现遮挡,目标消失等长时跟踪问题
对于比较像的目标是会误判,比如都是人
目标形状变化较大时容易发生漂移
模板更新问题:模板不更新会导致模型鲁棒性不佳,出现遮挡模糊等无法识别;模板更新策略不佳又会引入模板污染、过拟合等问题
下面主要介绍两个算法:SiamFC和SiamRPN。
SiamFC
首先简单介绍下本算法:
使用孪生网络(Siamese Net)结构来进行相似度比较,对比模版图片(在训练前应该指定好)和需比较的目标图片之间的相似度。速度是SiameseFC的最大优势,可以用于追踪任意物体(不需要预先训练),在当时某几个benchmark上达到了最优。
还存在的问题:
由于要与模版图片对比,因此如果在追踪过程中,物体突然发生一些变换(比如正面到侧面等),会导致追踪失败。
如果背景物体中,有较多相似性物体,追踪效果也不好。
预测的边框好像都是原始边框的等比例变换(这个不确定,看源码好像是这样)。
如果位置发生突变,效果不好(物体超出搜索区域范围)。
SiamFC主要思想:
实际上就是将跟踪当做匹配问题,本质是估计每个滑窗的得分,先将搜索图像和目标图像做一个交叉相关,得到一个tensor,其实是相关feature的一个特征,代表了搜索图像和目标图像每个patch的相关信息,在通过1*1卷积就可以得到box 和score
动机是解决神经网络实时跟踪的问题。由于卷积网络先进行离线训练,在线跟踪时需要利用随机梯度下降法(SGD)微调网络权重,从而使速度下降,无法实时跟踪。作者利用全卷积孪生网络进行相似性学习,使用目标检测的ILSVRC数据集训练,再把模型从ImageNet Video域推广到其他视频跟踪数据集域,线上的跟踪过程只需推理即可。
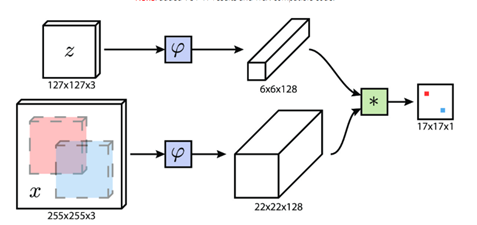
首先简单介绍下siamfc的网络框架,图中z是模板(即待跟踪的目标),x是当前帧的图像,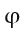 是用于提取图像特征的卷积网络,因为作用于x(srch_img)的 与作用于z(template)的 完全一样所以称为孪生网络(siamese),经过卷积网络提取特征后分别得到x和z的feature map,然后将二者卷积( * 表示卷积),即将6×6×128的feature map当做卷积核,在22×22×128上进行卷积得到17×17×1的heatmap,heatmap上值最大的点就对应于x图像中目标的中心。
是用于提取图像特征的卷积网络,因为作用于x(srch_img)的 与作用于z(template)的 完全一样所以称为孪生网络(siamese),经过卷积网络提取特征后分别得到x和z的feature map,然后将二者卷积( * 表示卷积),即将6×6×128的feature map当做卷积核,在22×22×128上进行卷积得到17×17×1的heatmap,heatmap上值最大的点就对应于x图像中目标的中心。
下面说一些细节,首先 网络是5层不带padding的AlexNet。显然5层不符合深度学习“深”的理念,但是由于网络不能加padding所以限制了网络深度,为什么不能padding呢,事实上target在x上的位置,我们是从heatmap得到,这是基于卷积的平移等变性,即target在x上平移了n,相应的就会在heatmap上平移n/stride,且值不会变。但如果加入了padding,对于图像边缘的像素,虽然也会平移,但值会变,因为padding对图像的边缘进行了改变。siamRPN++和siamDW解决了这个问题,后面会详细讲。然后是训练时,x和z的获取方式:z是以第一帧的bbox的中心为中心裁剪出一块图像,再将这块图像缩放到127×127,255×255的srchimg也是类似得到的。这里有几个细节需要注意,第一,template与srch_img的中心就是目标的中心,且template是裁剪过的,如果不裁剪那么template中背景过多,导致匹配失败。不过在siamfc中背景信息完全被丢弃,换句话说,siamfc对缺乏对背景的利用,也导致模型的判别性不足,后续有相关工作对此进行改进。第二,训练阶段的标签怎么得到呢,如果只是简单将目标所在位置标为1,其他位置标为0,就会产生严重的样本不均衡问题,于是作者将离目标中心点r半径内的label都设置为1,其他设为0,loss function
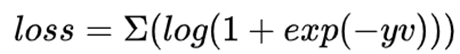
y为预测值,v为标签值,这里关于label的设置也有一些可以优化的点,使用focal loss是否对模型的判别性是否会更高呢。第三,在测试时,siamfc的template是不更新的,即一直为第一帧,这就导致模型的鲁棒性不佳,例如随着时间的变化template出现遮挡、模糊等情况,但是如果更新策略不佳又会引入模板污染、过拟合等问题,在这方面也有相关工作讨论。在测试时,首先搜索区域不是整个srchimg而只是之前的四倍大小的搜索区域,其次在featuremap上加了余弦窗,最后为了解决尺度问题,对srch_img进行缩放了3种尺度。
SiamFC预测时,不在线更新模板图像。这使得其计算速度很快,但同时也要求SiamFC中使用的特征具有足够鲁棒性,以便在后续帧中能够应对各种变化。另一方面,不在线更新模板图像的策略,可以确保跟踪漂移,在long-term跟踪算法上具有天然的优势。
图片输入:两个输入z与x的大小是确定的,其中第一帧的groundtruth是已知的(x_min,y_min,w,h),那么模板图像z的大小即为:
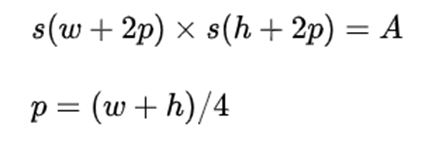
其中A=127^2,s是对图像进行的一种变换,即进行(w+2p)x(h+2p)的扩展,再resize成127x127的大小。
而对于搜索区域x来说,以上一帧预测的bbox的中心为裁剪中心,裁剪出255x255大小的图片。这里,作者为了提高跟踪性能,选取了多尺度进行预测,分别是1.025^{-2,-1,0,1,2},其中255x255对应尺度为1。之后作者又尝试了三种尺度的SiamFC-3s,提升了FPS。
这里特别指出,当模板和搜索图像不够裁剪时,要对不足的像素进行RGB通道的均值填充。
SiamRPN
商汤在CVPR2018上提出的,孪生候选区域生成网络(Siameseregion proposal network),简称Siamese-RPN,包含用于特征提取的孪生子网络和候选区域生成网络,其中候选区域生成网络包含分类和回归两条支路,借鉴了目标检测的RPN结构。在跟踪阶段将跟踪任务构造出局部单目标检测任务,作者预先计算孪生子网络中的模板支路(第一帧),并且将它构造成一个检测支路中区域提取网络里面的一个卷积层,用于在线跟踪。
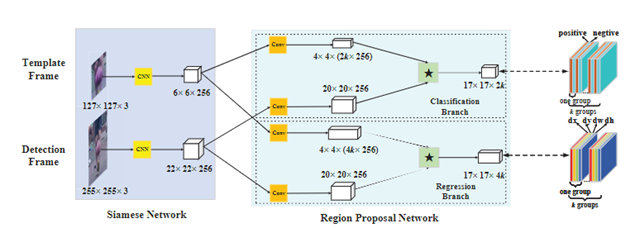
siamRPN的网络框架见上图,这里可以从one-shot的思路理解sianRPN,我们把template分支的embedding当作卷积核,srch_img分支当作feature map,在template与srchimg卷积之前,先将卷积核(即template得到的feature map)通过1*1卷积升维到原来的2k(用于cls)和4k(用于位置的reg)倍。然后拉出分类与位置回归两个分支。siamfc相当于直接将template与srching直接卷积匹配,而siamRPN在template上引入k个anchor相当于选取了k个尺度与srch_img进行匹配,解决了尺度问题。
siamRPN无论是在A还是R上都优于siamfc(这里补充一下,对于跟踪而言主要有两个子指标A(accuracy)与R(robust), A主要是跟踪的位置要准,R主要是模型的判别性要高,即能够准确识别哪些是目标,从而判断出目标的大致位置。关于R与A可参见VOT评价指标),也就是说siamrpn的模型判别性与准确性都比siamfc好。
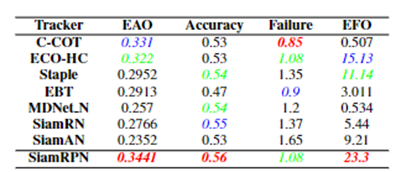
准确性的提升主要来自与siamrpn将位置回归单独拉出来作为一个分支,这一点在后续的siamfc++中也可以看到作者相关的论述。在模型判别性方面,笔者认为,提升的关键在于siamrpn在进行匹配(即template与srchimg卷积的过程)时,由于引入了k个anchors,相当于从k个尺度对template与srch_img进行更加细粒度的匹配,效果更好也是情理之中。另外很重要的一点就是sianrpn解决了尺度问题。
end
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助