
Pandas数据排序,人人都能学会的几种方法
来源:Python数据之道 (ID:PyDataLab)
作者:阳哥
Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。
Pandas是一种高效的数据处理库,它以 dataframe 和 series 为基本数据类型,呈现出类似excel的二维数据。
在数据处理过程中,咱们经常需要将数据按照一定的要求进行排序,以方便展示。
这里,阳哥来给大家分享下 在 Pandas 中排序的几种常用方法,主要包括 sort_index 和 sort_values 。
01 按索引排序
数据准备
文中主要使用了 pandas 和 numpy ,首先导入 Python 库,如下:
import pandas as pd
import numpy as np
print(f'pandas version: {pd.__version__}')
# pandas version 1.3.2
本次使用的数据如下:
data = {
'brand':['Python数据之道','价值前瞻','菜鸟数据之道','Python','Java'],
'B':[4,6,8,12,10],
'A':[10,2,5,20,16],
'D':[6,18,14,6,12],
'years':[4,1,1,30,30],
'C':[8,12,18,8,2],
}
index = [9,3,4,5,2]
df = pd.DataFrame(data=data,index=index)
df
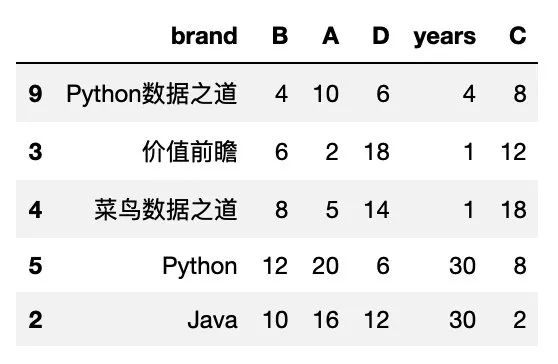
按行索引排序
sort_index() 是 pandas 中按索引排序的函数,默认情况下, sort_index 是按行索引来排序。
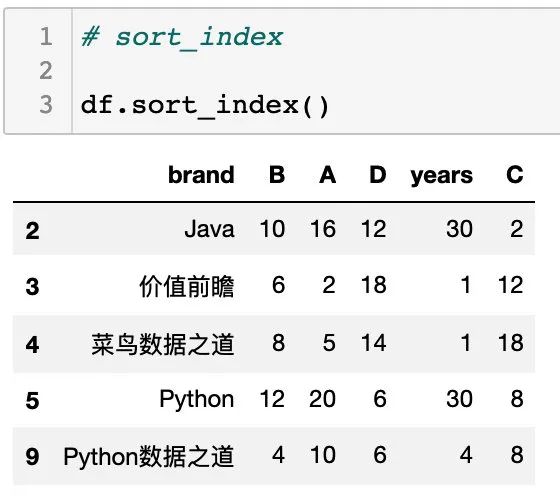
通过设置参数 ascending 可以设置升序或降序排列,默认情况下是 ascending=True ,为升序排列。
设置 ascending=False 时,为降序排列,如下:
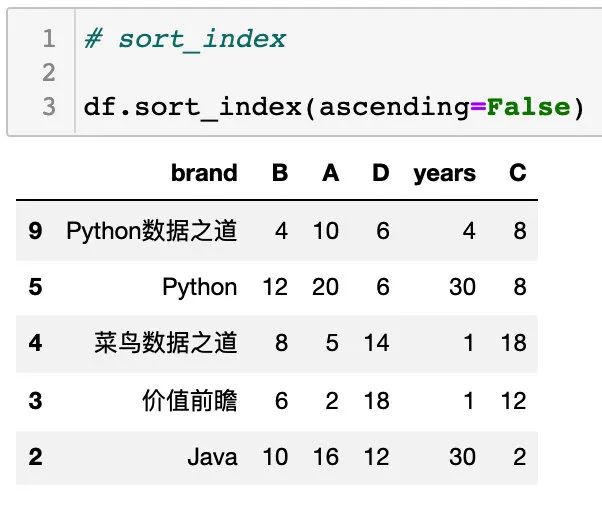
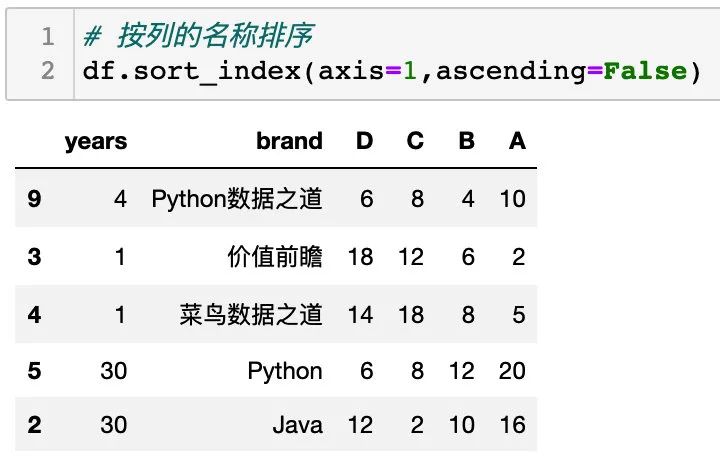
按列的名称排序
通过设置参数 axis=1 可实现按列的名称排序,如下:
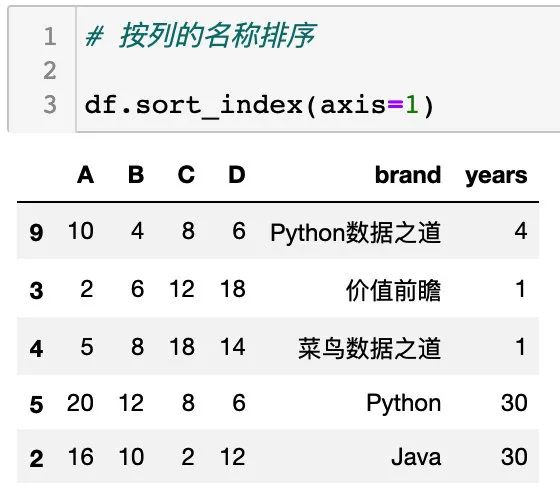
同样的,可以设置 参数 ascending 的值,如下:
关于按列的名称排序,更多的方法,可以参考下面的内容:
02 按数值排序
sort_values() 是 pandas 中按数值排序的函数。
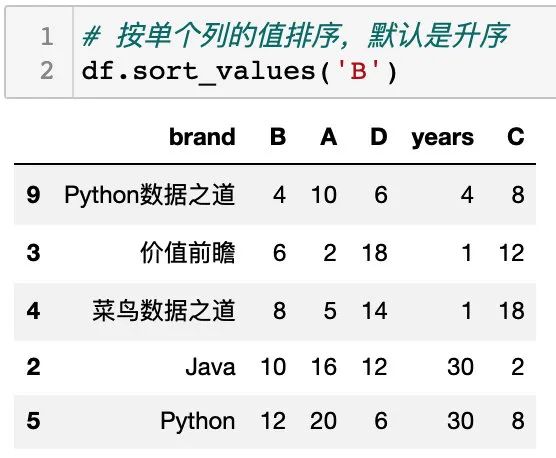
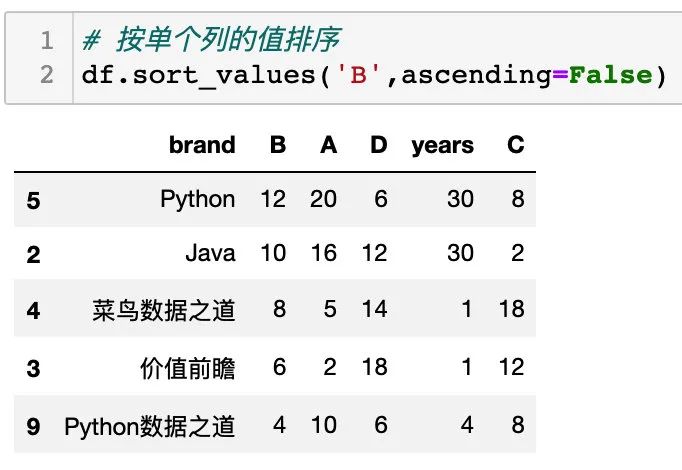
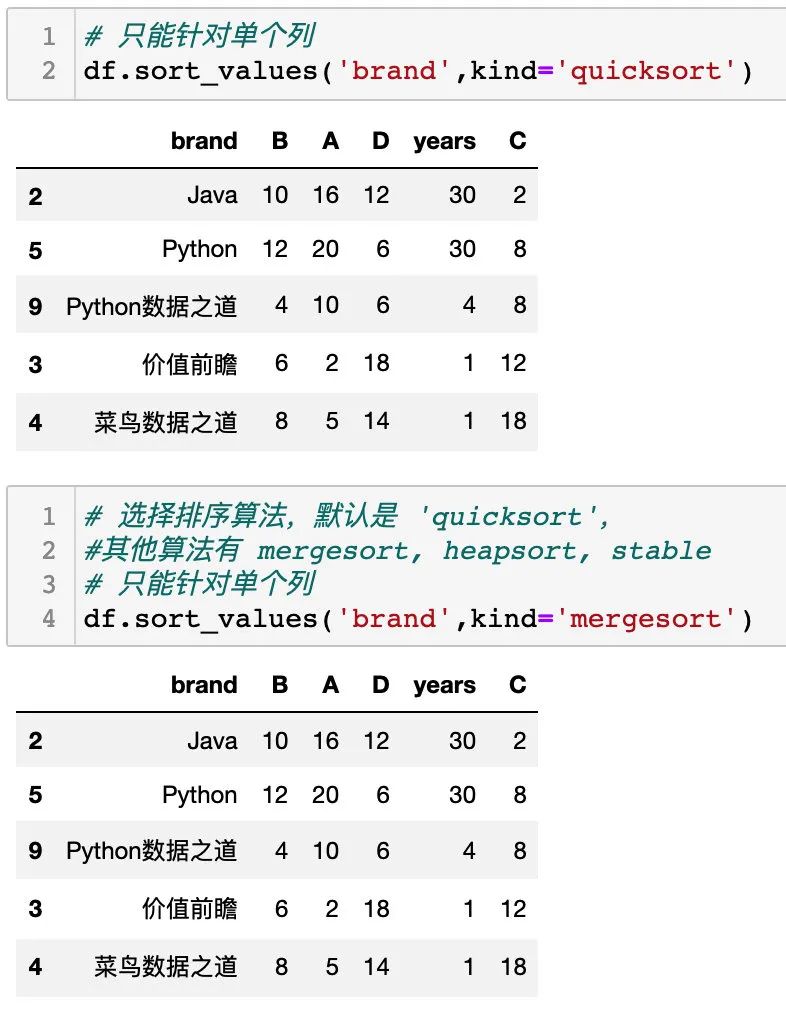
按单个列的值排序
sort_values() 中设置单个列的列名称,可以对单个列进行排序,通过设置参数 ascending 可以设置升序或降序排列,如下:
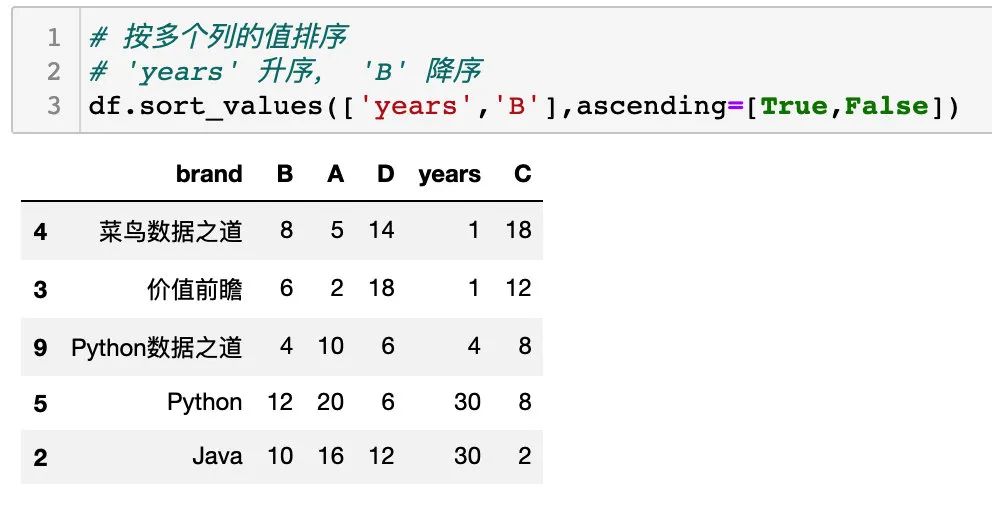
按多个列的值排序
同时,sort_values() 可以对多个列进行不同的排序,通过设置列明和排序方式组合来实现,如下:
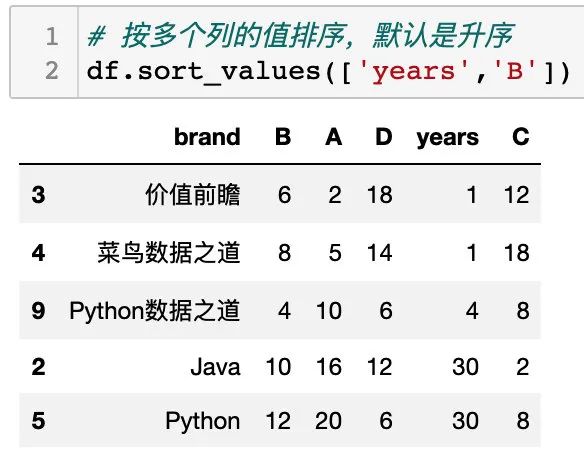
设置参数 ascending ,years 列为升序,B 列为降序,如下:
选择排序算法
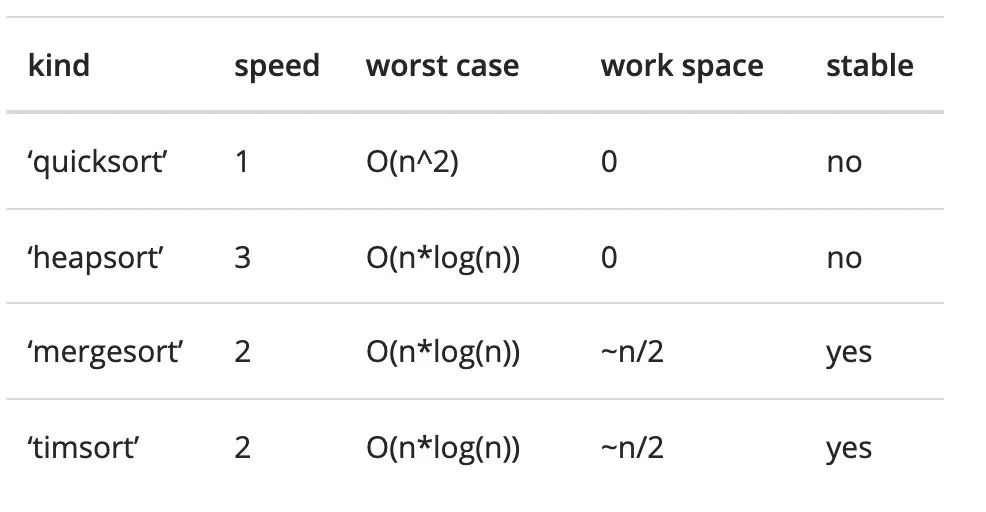
选择排序算法,参数 kind 默认是 'quicksort',其他算法有 mergesort, heapsort, stable。
该参数只针对单个列时才有效。

在 numpy 的 sort文档中,对几种排序的特点进行了描述,主要是程序运行时占用的资源和运行速度有差异。
numpy 文档地址:
https://numpy.org/doc/stable/reference/generated/numpy.sort.html#numpy.sort
示例如下:
忽略索引
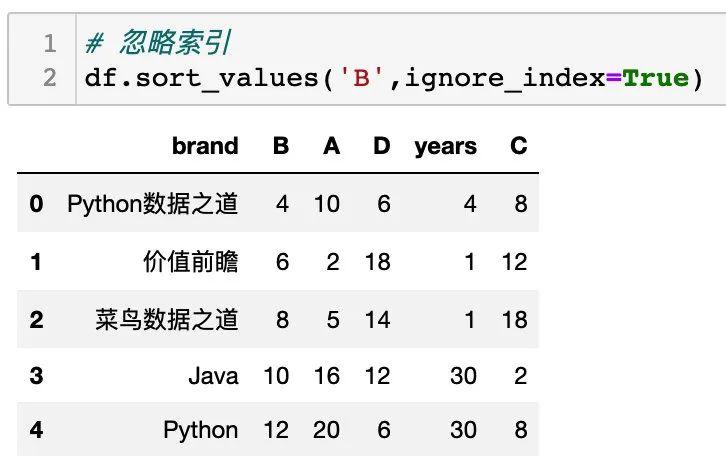
在排序过程中,还可以引入 ignore_index 参数,来对行索引重新设置,如下:
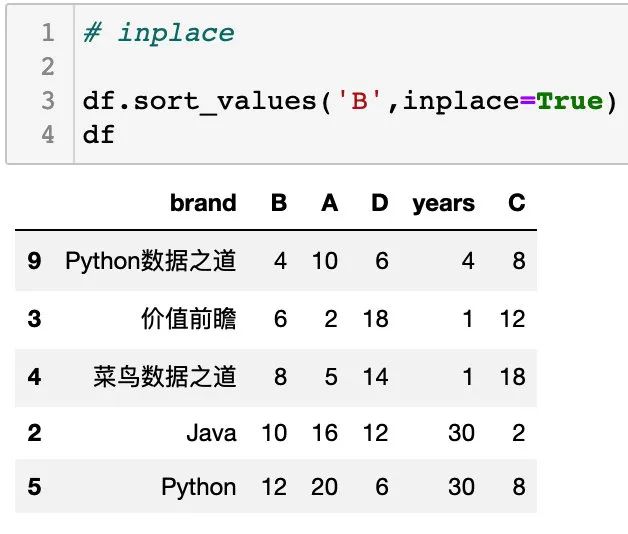
inplace
inplace 是 pandas 中常见的一个参数。
inplace = True:不创建新的对象,直接对原始对象进行修改;默认是 False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似。
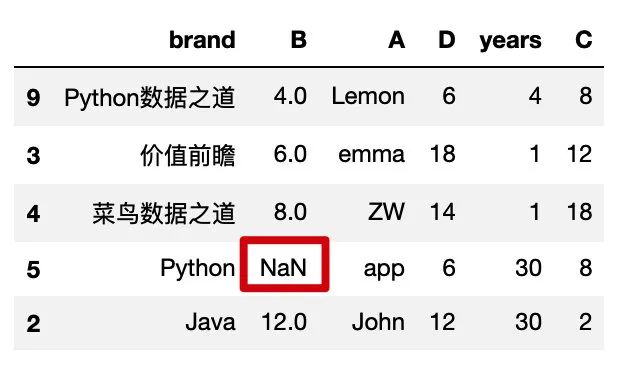
缺失值
先构造一个含缺失值的 dataframe,如下:
data = {
'brand':['Python数据之道','价值前瞻','菜鸟数据之道','Python','Java'],
'B':[4,6,8,np.nan,12],
'A':['Lemon','emma','ZW','app','John'],
'D':[6,18,14,6,12],
'years':[4,1,1,30,30],
'C':[8,12,18,8,2],
}
index = [9,3,4,5,2]
df1 = pd.DataFrame(data=data,index=index)
df1
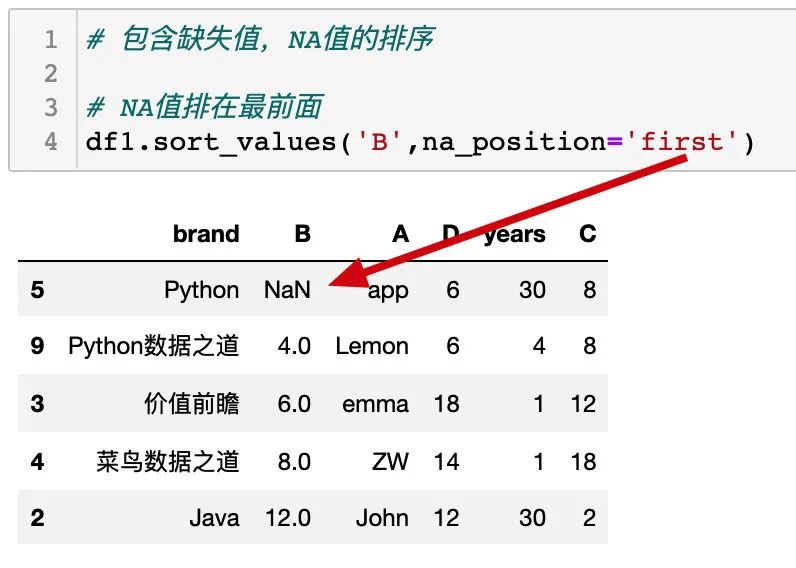
缺失值排在最前面:
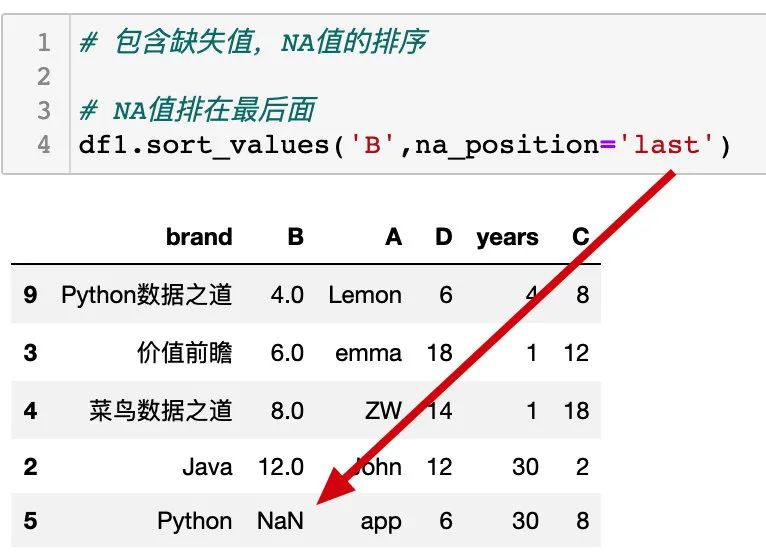
缺失值排在最后面:
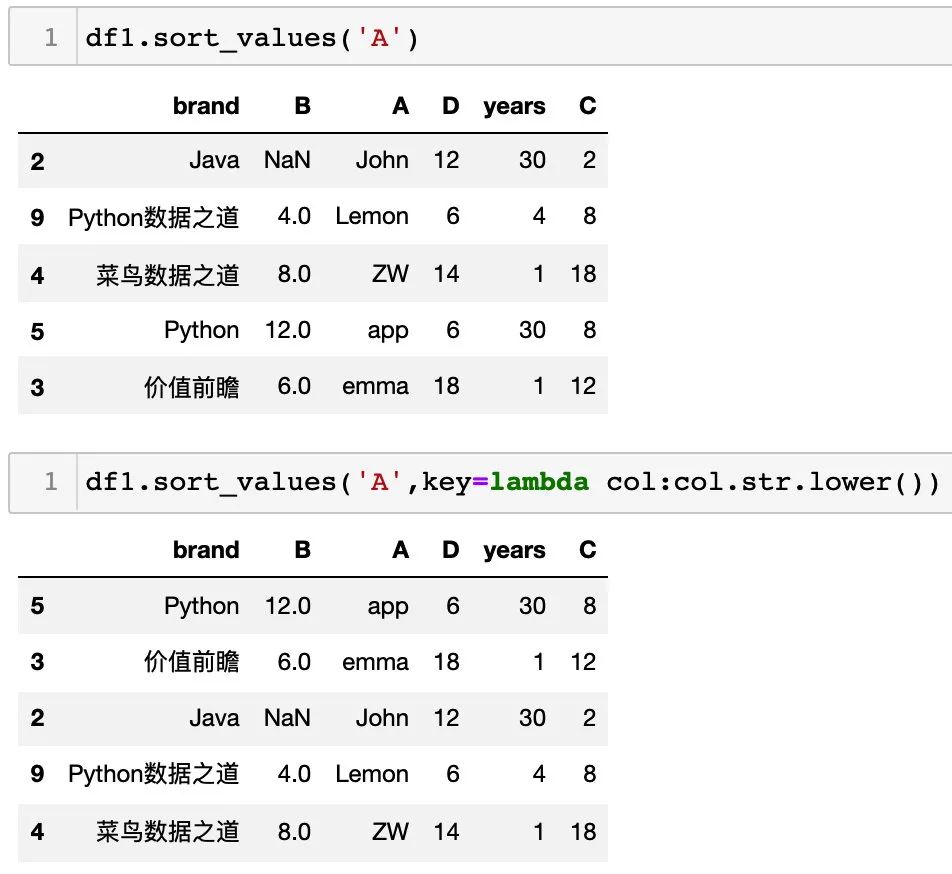
key 参数
通过设置 key 参数,可以将列按照特定条件进行排序,对比下下面的排序:
源代码文件
以上就是关于 Pandas 中排序的介绍,欢迎大家来畅聊,Pandas 中有哪些实用的小技巧~~
Python数据分析,包括Pandas、Numpy等,代码地址:
https://github.com/liyangbit/python_data_analysis
推荐阅读
推荐阅读