
Disruptor高性能之道-局部性原理与缓冲行填充细节补充
在之前的文章中,我们讨论了Disruptor高性能实现机制中的:
RingBuffer环形队列及内存预加载 缓存行填充避免伪共享
本文对之前没有讲到的细节进行补充。
对于数组元素预加载的补充解释
private void fill(EventFactory eventFactory){
for (int i = 0; i < bufferSize; i++){
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
一次性填充满整个数组,这样做是一个比较有技巧的做法,Disruptor通过填充满数组,在运行时改变对象的值来达到防止Java垃圾回收(GC)产生的系统开销。
换句话说就是它不需要垃圾回收。
Disruptor是如何通过位运算提升取模效率的?
我们已经知道,RingBufferSize为2的N次方时,可以通过位于运算提升取模效率,公式为:
❝seq & (ringBufferSize - 1) == index
❞
即:当前event的sequence与RingBufferSize-1的差进行位于运算,就等价于sequence Mod RingBufferSize,但是效率更高。
在Disruptor的源码中具体是如何利用该机制的?
@Override
public E get(long sequence)
{
return elementAt(sequence);
}
❝Disruptor通过get(sequence)从RingBuffer中取出下一个可用的sequence位于RingBuffer中的下标,具体实现在elementAt方法中。
❞
// com.lmax.disruptor.RingBufferFields#elementAt
protected final E elementAt(long sequence) {
return (E) UNSAFE.getObject(entries, REF_ARRAY_BASE + ((sequence & indexMask) << REF_ELEMENT_SHIFT));
}
❝可以看到elementAt是通过UNSAFE直接调用底层方法getObject,通过递增序列号获取与序列号对应的数组元素。
❞
缓存行填充与局部性原理
我们知道Disruptor是通过缓存行填充避免了伪共享问题。
实际上这与 “局部性原理” 息息相关。
❝解释下什么叫做:局部性原理。
程序的局部性原理指的是在一段时间内程序的执行会限定在一个局部范围内。这里的“局部性”可以从两个方面来理解,一个是时间局部性,另一个是空间局部性。
时间局部性指的是程序中的某条指令一旦被执行,不久之后这条指令很可能再次被执行;如果某条数据被访问,不久之后这条数据很可能再次被访问。
而空间局部性是指某块内存一旦被访问,不久之后这块内存附近的内存也很可能被访问。
❞
CPU缓存读写就利用了局部性原理。
当CPU从主内存加载数据A时,它会将数据A缓存至CPU的高速缓存cache中。除了A会被缓存,A附近的数据也会被缓存。
根据局部性原理分析,由于A会被访问,那么A周围的其他数据也很有可能会被访问,如果一并加载则会提升程序的性能。
但是由于多核CPU同时修改同一缓存行,导致缓存行失效后重新加载主内存,因此出现了伪共享的问题。
再次分析Disruptor对变量的缓存行填充原理
首先看一下Disruptor中对 INITIAL_CURSOR_VALUE 的特殊处理。
public final class RingBuffer extends RingBufferFields implements Cursored, EventSequencer, EventSink
{
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
protected long p1, p2, p3, p4, p5, p6, p7;
RingBuffer继承于RingBufferField
abstract class RingBufferFields extends RingBufferPad
RingBufferFields继承于RingBufferPad
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
那么我们就知道,在INITIAL_CURSOR_VALUE前后各填充了7个long型变量。
前面的 7 个来自继承的 RingBufferPad 类,后面的 7 个则是直接定义在 RingBuffer 类里 面。
「这14个变量没有任何实际的用途。既不会去读也不会去写他们。」
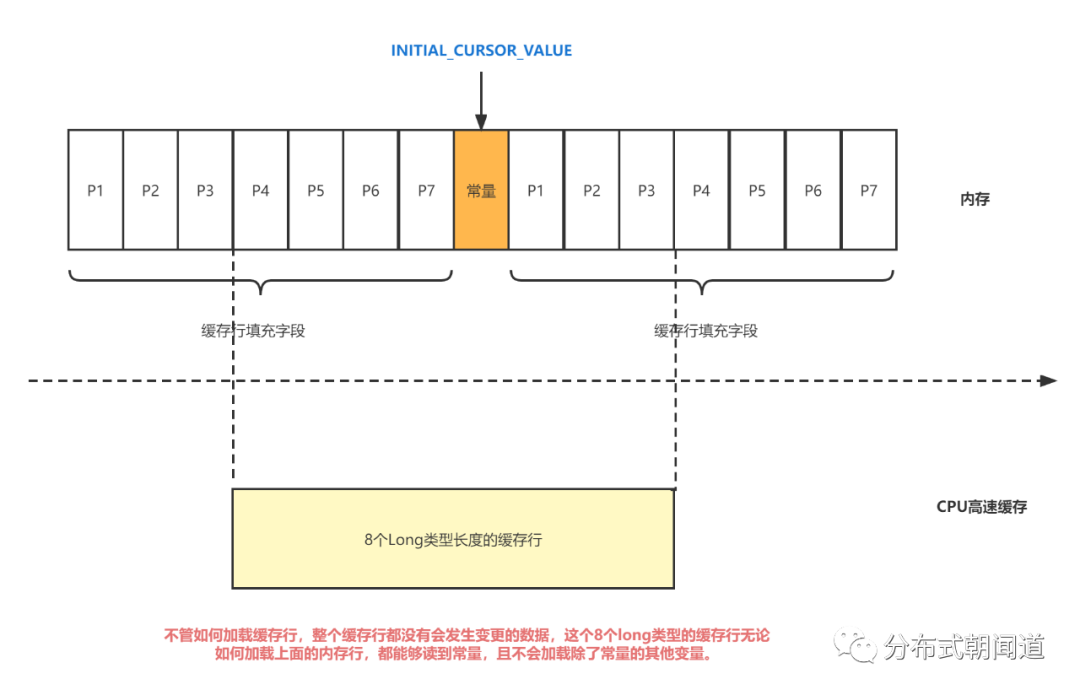
可以看到,常量INITIAL_CURSOR_VALUE前后各填充了7个long型变量,无论CPU高速缓存如何加载缓存行(一个缓存行8个long型长度),整个缓存行都没有会发生变更的数据,这个8个long类型的缓存行无论如何加载上面的内存行,都能够读到常量,且不会加载除了常量的其他变量。
❝而INITIAL_CURSOR_VALUE是一个常量,也不会进行修改。所以一旦它被加载到CPU Cache 之后,只要被频繁地读取访问,就不会再被换出 Cache 了。这也就意味着对于这个值的读取速度,会是「一直是 CPU Cache 的访问速度,而不是内存的访问速度」。
❞
这有效地解决了伪共享的问题。