
使用 eBPF 在生产环境调试 Go 应用

本文是描述我们如何在生产中使用 eBPF 调试应用程序的系列文章中的第一篇,无需重新编译/重新部署,这篇文章介绍了如何使用 gobpf[1] 和uprobes 为 Go 应用程序建立一个函数参数跟踪器,这种技术也可以扩展到其他编译语言,如 C++、Rust 等。
介绍
通常在调试应用的时候,我们对捕获程序的状态比较感兴趣,这可以让我们检查应用程序正在做什么,并确定我们代码中的错误所在,观察状态的一个简单方法是使用调试器来捕获函数参数,对于 Go 应用程序,我们经常使用的是 Delve 或 gdb。
Delve 和 gdb 在开发环境中调试效果很好,但在生产中并不经常使用,调试器会对程序造成很大的干扰,甚至允许状态变化,这可能就会导致生产环境的应用出现一些意外的故障。
为了更干净地捕获函数参数,我们将探索使用 Linux 4.x+ 中可用的增强型 BPF(eBPF[2])和更高级别的 Go 库 gobpf 的使用。
什么是 eBPF?
Extended BPF(eBPF)是 Linux 4.x+ 中的一种内核技术,你可以把它看作是一个轻量级的沙盒虚拟机,它运行在 Linux 内核内部,可以提供对内核内存的验证访问。
如下所示,eBPF 允许内核运行 BPF 字节码,虽然使用的前端语言可以不同,但通常都是 C 语言的限制子集,通常先用 Clang 将 C 代码编译成 BPF 字节码,然后对字节码进行验证以确保其安全执行。这些严格的验证保证了机器代码不会故意或意外地危害 Linux 内核,并且保证了 BPF 探针每次被触发时都能在一定数量的指令中执行,这些保证使得 eBPF 能够用于性能关键型的工作负载,如数据包过滤、网络监控等。
在功能上,eBPF 允许你在一些事件(如定时器、网络事件或函数调用)发生时运行受限的 C 代码,当触发一个函数调用时,我们把这些函数称为 probe,它们可以用来运行在内核内的函数调用上(kprobes),也可以运行在用户空间程序的函数调用上(uprobes)。接下来我们主要介绍如何使用 uprobes 来动态跟踪函数参数。
Uprobes
Uprobes 允许你通过插入一个调试陷阱指令(x86 上的 int3)来拦截用户空间程序,触发软中断,这也是调试器的工作方式。一个 uprobe 的流程基本上与任何其他 BPF 程序相同。编译和验证过的 BPF 程序作为 uprobe 的一部分被执行,结果可以写入缓冲区。

让我们看看 uprobes 是如何实际运行的,为了部署 uprobes 和捕获函数参数,我们将使用一个简单的演示程序。
// computeE computes the approximation of e by running a fixed number of iterations.
2func computeE(iterations int64) float64 {
3 res := 2.0
4 fact := 1.0
5
6 for i := int64(2); i < iterations; i++ {
7 fact *= float64(i)
8 res += 1 / fact
9 }
10 return res
11}
12
13func main() {
14 http.HandleFunc("/e", func(w http.ResponseWriter, r *http.Request) {
15 // Parse iters argument from get request, use default if not available.
16 // ... removed for brevity ...
17 w.Write([]byte(fmt.Sprintf("e = %0.4f\n", computeE(iters))))
18 })
19 // Start server...
20}
main() 函数中启动了一个简单的 HTTP 服务器,它在 /e 上暴露了一个单一的 GET 端点,该端点使用迭代近似计算欧拉数(e),computeE 接收一个单一的查询参数(iters),它指定了近似运行的迭代次数。迭代次数越多,近似越精确,但代价是计算周期,我们不需要了解函数背后的数学知识点,这里我们主要是了解如何跟踪 computeE 的调用参数。
为了了解 uprobes 是如何工作的,我们来看看二进制文件内部是如何跟踪符号的。由于 uprobes 是通过插入调试陷阱指令来工作的,所以我们需要得到函数所在的地址,Linux 上的 Go 二进制文件使用 ELF 来存储调试信息,即使在优化的二进制文件中,这些信息也是可用的,除非调试数据被剥离了,我们可以使用命令 objdump 来检查二进制中的符号。
[0] % objdump --syms app|grep computeE
00000000006609a0 g F .text 000000000000004b main.computeE
从输出可以看出来函数 computeE 位于地址 0x6609a0,要查看它周围的指令,我们可以要求 objdump 将其拆解为二进制(通过添加 -d 完成),拆解后的代码是这样的。
[0] % objdump -d app | less
00000000006609a0 :
6609a0: 48 8b 44 24 08 mov 0x8(%rsp),%rax
6609a5: b9 02 00 00 00 mov $0x2,%ecx
6609aa: f2 0f 10 05 16 a6 0f movsd 0xfa616(%rip),%xmm0
6609b1: 00
6609b2: f2 0f 10 0d 36 a6 0f movsd 0xfa636(%rip),%xmm1
从中我们可以看到调用 computeE 时的情况,第一条指令是 mov 0x8(%rsp),%rax,这将内容偏移 0x8 从 rsp 寄存器移到 rax 寄存器,这其实就是上面的输入参数迭代,Go 的参数是在栈上传递的。
有了这些信息,我们现在就可以编写代码来跟踪 compute 的参数了。
构建 Tracer
为了捕捉事件,我们需要注册一个 uprobe 函数,并有一个可以读取输出的用户空间函数。我们将编写一个名为 tracer 的二进制,负责注册 bPF 代码和读取 bPF 代码的结果,如图所示,uprobe 将简单地写入一个 perf-buffer,一个用于 perf 事件的 linux 内核数据结构。

接下来让我们来看看当我们添加一个 uprobe 时发生的细节,下图显示了 Linux 内核是如何用 uprobe 修改二进制的。软中断指令(int3)作为main.computeE 的第一条指令被插入,这将引起一个软中断,允许 Linux 内核执行我们的 BPF 函数,然后我们将参数写入 perf-buffer,由 tracer 异步读取。

这里的 BPF 函数比较简单,C 代码如下所示。我们注册这个函数,这样每次调用 main.computeE 时都会调用它,一旦它被调用,我们只需读取函数参数并将其写入 perf buffer。大量的模板需要来设置缓冲区等,这可以在 完整的示例[3] 中找到。
#include
BPF_PERF_OUTPUT(trace);
inline int computeECalled(struct pt_regs *ctx) {
// The input argument is stored in ax.
long val = ctx->ax;
trace.perf_submit(ctx, &val, sizeof(val));
return 0;
}
现在,我们有了一个功能完备的 main.computeE 函数的端到端参数跟踪器,其结果如下所示。
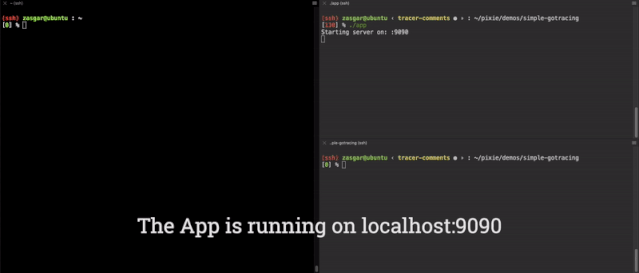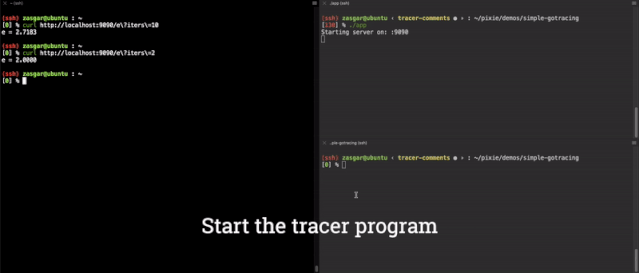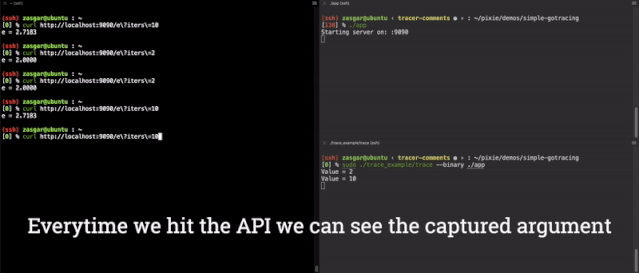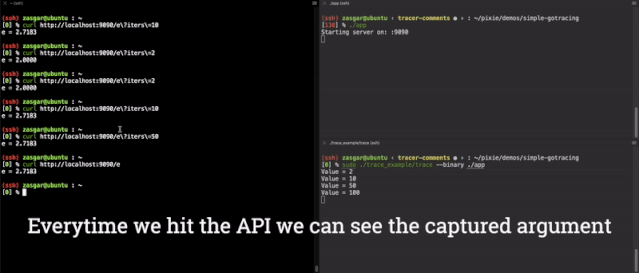
我们实际上可以使用 GDB来 查看对二进制的修改,在这里,我们在运行跟踪二进制之前,将 0x6609a0 地址的指令转储起来。
(gdb) display /4i 0x6609a0
10: x/4i 0x6609a0
0x6609a0 : mov 0x8(%rsp),%rax
0x6609a5 : mov $0x2,%ecx
0x6609aa : movsd 0xfa616(%rip),%xmm0
0x6609b2 : movsd 0xfa636(%rip),%xmm1
这是我们运行跟踪二进制后的情况,我们可以清楚地看到,现在第一条指令是 int3。
(gdb) display /4i 0x6609a0
7: x/4i 0x6609a0
0x6609a0 : int3
0x6609a1 : mov 0x8(%rsp),%eax
0x6609a5 : mov $0x2,%ecx
0x6609aa : movsd 0xfa616(%rip),%xmm0
虽然我们为这个特殊的例子硬编码了追踪器,但我们可以想办法把这个过程通用化。Go 的许多特性,如嵌套指针、接口、通道等,使得这个过程具有挑战性,但是解决这些问题可实现现有系统中不存在的另一种检测模式。另外,由于这个过程是在二进制层面工作的,所以它可以与其他语言(C++、Rust 等)的原生编译二进制一起使用,我们只需要考虑到它们各自 ABI 的不同点即可。
总结
使用 uprobes 的 BPF 跟踪有它自己的优点和缺点,当我们需要对二进制状态进行观察时,使用 BPF 是有好处的,即使是在附加调试器会有问题或有害的环境中运行时也是如此(例如生产二进制文件)。最大的缺点是,即使是很小的应用程序状态的跟踪也需要我们去编写代码,因为 BPF 的代码的编写和维护还是相对较复杂的。
参考文档
https://github.com/iovisor/gobpf https://github.com/iovisor/bcc https://www.youtube.com/watch?v=SlcBq3xDc7I
原文链接:https://blog.pixielabs.ai/blog/ebpf-function-tracing/post/
参考资料
gobpf: https://github.com/iovisor/gobpf
[2]eBPF: https://ebpf.io/
[3]完整的示例: https://github.com/pixie-labs/pixie/blob/main/demos/simple-gotracing/trace_example/trace.go
训练营推荐


 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习