
前端中如何使用 WebWorker 对用户体验进行革命性的提升
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
前言
随着前端应用场景的逐渐复杂化,伴随而来的对大数据的处理就不可避免。那么今天就以一个真实的应用场景为例来谈谈前端中如何通过子线程来处理大数据。
目前主流显示器的刷新率为 60Hz,即一帧为 16ms,因此播放动画时建议小于 16ms,用户操作响应建议小于 100ms,页面打开到开始呈现内容建议小于 1000ms。
-- 根据 Chrome 团队提出的用户感知性能模型 RAIL。
以上这段应用是 google 团队提出的用户最优体验模型,从 js 运行的角度,大致意思就是尽量保证每一个 js 任务在最短的时间内执行完毕。
案例场景
现代 web 程序中,要求数据、报表导出的需求已经非常普遍。导出的数据量越来越大、数据的复杂程度也越来越高,最常见的时间字段大多数情况下也可能需要前端去转换,因此对源数据的遍历总避免不了。现在以导出某站点各类因子的监测数据报表为例:
报表格式要求
每一条数据包含 若干项因子数据,每一个因子项数据包含改因子的监测数据以及对应的评价等级; 要求导出上一季度 90 天的小时数据,数据源大概在 2100 条左右(有分页查询的条件); 报表要求时间格式为 YYYY年MM月DD日 HH时(例如:2020年12月25日 23时),每一项因子内容为 因子数据 + 因子等级(例如:2.36(I))。
数据源格
后端返回数据格式如下
{
"dateTime": "2021-06-05 14:00:00",
"name": "站点一",
"factorDatas": [
{"code": "w01010", "grade": 1, "value": 26.93},
{"code": "w666666", "grade": 1, "value": 1.26}
]
}
复制代码
数据源基本处理
对应报表导出需求,对这 2000 多条数据的遍历总避免不了,甚至会有大循环嵌套小循环的处理。
大循环需要处理 dateTime 字段; 小循环中需要循环 factorDatas 字段,查询 grade 对应的等级名, 最后在拼接出报表需要的格式。
抛砖引玉
简单实现
以下代码仅是模拟代码,默认前端已经完成了所有数据的加载
正常的开发流程当然是采用 for 循环不断的调用分页的接口不断地查询数据,直到数据查询完毕,然后再进行统一循环处理每一行数据。为方便对数据处理单独将某些公共方法单独抽一个工具类:
class UtilsSerice {
/**
* 获取水质类别信息
* @param waterType
* @param keyValue
* @param keyName?
*/
static async getGradeInfo(waterType: WaterTypeStringEnum, keyValue: string | number, keyName?: string): Promisenull | undefined> {
// 缓存中数据的 key
const flagId: string = waterType + keyValue;
// 缓存中有对应的值,直接返回
if (TEMP_WATER_GRADE_MAP.get(flagId)) {
return TEMP_WATER_GRADE_MAP.get(flagId);
}
// 获取等级列表
const gradeList: WaterGrade[] = await this.getEnvData(waterType);
// 查询等级值对应的等级信息
const gradeInfo: WaterGrade = gradeList.find((item: WaterGrade) => {
const valueName: string | number | undefined = keyName === 'id' ? 'id' : item.hasOwnProperty('value') ? 'value' : 'level';
return item[valueName] === keyValue;
}) as WaterGrade;
// 将查询到的等级信息缓,方便下一次查询该等级时直接返回
if (gradeInfo) {
TEMP_WATER_GRADE_MAP.set(flagId, gradeInfo);
}
return gradeInfo;
}
}
复制代码
数据导出逻辑如下:
// 假设 allList 已经是 2100 条数据集合
const allList = [{"dateTime": "2021-06-05 14:00:00", "code": "sssss", "name": "站点一", "factorDatas": [{"code": "w01010", "grade": 1, "value": 26.93}, {"code": "w666666", "grade": 1, "value": 1.26}]}]
const table: ObjectUnknown[] = [];
for (let i = 0; i < allList.length; i ++) {
const rows = {...allList[i]}
// 按需求处理时间格式
rows['tiemStr'] = moment(allList[i].dateTime).format('YYYY年MM月DD日 HH时')
for (let j = 0; j < allList[i].factorDatas.length; j ++) {
const code = allList[i].factorDatas[j].code
const value = allList[i].factorDatas[j].value
const grade = allList[i].factorDatas[j].grade
// 此处按需求异步获取等级数据---- 此方法已经尽可能的做了性能优化
const gradeStr = await UtilsSerice.getGradeInfo('surface', grade, 'value')
rows[code] = `${value}(${gradeStr})`
}
table.push(rows)
}
const downConfig: ExcelDownLoadConfig = {
tHeader: ['点位名称', '接入编码', '监测时间', '因子1', '因子2', '因子2' ],
bookType: 'xlsx',
autoWidth: 80,
filename: `数据查询`,
filterVal: ['name', 'code', 'tiemStr', 'w01010', 'w01011', 'w01012'],
multiHeader: [],
merges: []
};
// 此方法是通用的 excel 数据处理逻辑
const res: any = await ExcelService.downLoadExcelFileOfMain(table, downConfig);
const file = new Blob([res.data], { type: 'application/octet-stream' });
// 文件保存
saveAs(file, res.filename);
复制代码
由于 JS 引擎线程是单线程且与 GUI 渲染线程是互斥的,因此在执行复杂的 js 计算任务时,用户的直观感受就是系统卡顿,例如输入框无法输入、动画停止、按钮无效等。以上代码可以实现数据的导出,可以看到在主线程导出数据时图片旋转已经停止、输入框已经无法输入。

我相信无论多么好说话的甲方,对于这样的系统估计也是无法接受的。
问题思考
稍微有编程经验的开发多多少少都会明白,是因为大数据的 for 循环遍历阻塞了其他脚本的执行,基于这个思想,有性能优化经验的开发工程师大概率会将这个大遍历拆分成多个小的任务来较少卡顿,这种方案也可以一定程度上解决卡顿的问题。但这种时间分片、任务拆分的优化方案并不适合并不是所有的大数据处理,尤其是前后数据有强依赖关系的,在这篇文章中暂不探讨这种优化方案。这篇文章来聊聊 webWorker:
它允许在 Web 程序中并发执行多个 JavaScript脚本,每个脚本执行流都称为一个线程,彼此间互相独立,并且有浏览器中的 JavaScript引擎负责管理。这将使得线程级别的消息通信成为现实。使得在 Web 页面中进行多线程编程成为可能。
-- IMWeb社区
webWorker 有几个特点:
能够长时间运行(响应) 快速启动和理想的内存消耗 天然的沙箱环境
webWorker使用
创建
//创建一个Worker对象,并向它传递将在新线程中执行的脚本url
const worker = new Worker('worker.js');
复制代码
通信
// 发送消息
worker.postMessage({first:1,second:2});
// 监听消息
worker.onmessage = function(event){
console.log(event)
};
复制代码
销毁
主线程中终止worker,此后无法再利用其进行消息传递。注意:一旦 terminate 后,无法重新启用,只能另外创建。
worker.terminate();
复制代码
导出功能迁移
接下来聊聊如何把数据导出这部分的代码迁移到 webWorker 中,在功能迁移前,首先需要梳理下数据导出的先决条件:
1:在 webWorker 中需要能调用 ajax 获取接口数据;2:在 webWorker 中要能加载 excel.js 的脚本;3:能正常调用 file-saver 中的 saveAs 功能;
基于以上的条件,我们逐一讨论,第一点很幸运 webWorker 支持发起 ajax 请求数据;第二点 webWorker 中提供了 importScripts() 接口,因此在 webWorker 中也能生成 Excel 的实例;第三点有些遗憾,webWorker 中是无法使用 DOM 对象, 而 file-saver 正好使用了 DOM,因此只能是子线程中处理完数据后传递数据给主线程由主线程执行文件保存操作(此处有个小优化,后续讲)。
方案对比
目前行业内集成 webWorker 的方案有很多,以下简单做个对比(来自腾讯前端团队):
| 项目 | 简介 | 构建打包 | 底层API封装 | 跨线程调用申明 | 可用性监控 | 易拓展性 |
|---|---|---|---|---|---|---|
| worker-loader[1] | Webpack 官方,源码打包能力 | ✔️ | ✘ | ✘ | ✘ | ✘ |
| promise-worker[2] | 封装基本 API 为 Promise 化通信 | ✘ | ✔️ | ✘ | ✘ | ✘ |
| comlink[3] | Chrome 团队, 通信 RPC 封装 | ✘ | ✔️ | 同名函数(基于Proxy) | ✘ | ✘ |
| workerize-loader[4] | 社区目前比较完整的方案 | ✔️ | ✔️ | 同名函数(基于AST生成) | ✘ | ✘ |
| alloy-worker[5] | 面向事务的高可用 Worker 通信框架 | 提供构建脚本 | 通信️控制器 | 同名函数(基于约定), TS 声明 | 完整监控指标, 全周期错误监控 | 命名空间, 事务生成脚本 |
| webpack5[6] | webpack5 中用于替换 worker-loader | 提供构建脚本 | ✘ | ✘ | ✘ | ✘ |
基于以上对比和我个人对 ts 的偏爱吧,该案例采用 alloy-worker 来做 webWorker 的集成,由于官方的 npm 包有问题,无法一次到位的集成,所以只能手动集成。
worker集成
官方集成文档[7]
首先将核心的基础的 worker 通信源码复制到项目目录 src/worker下。
声明事务
第一步在 src/worker/common/action-type.ts 中添加用于数据导出的事务。
export const enum TestActionType {
MessageLog = 'MessageLog',
// 声明数据导出的事务
ExportStationReportData = 'ExportStationReportData'
}
复制代码
请求、响应数据类型声明
在 src/worker/common/payload-type.ts 文件中声明请求、响应数据类型。
跨线程通信各事务的请求数据类型声明
export declare namespace WorkerPayload {
namespace ExcelWorker {
// 调用ExportStationReportData 导出数据时需要传这两个参数
type ExportStationData = {
factorList: SelectOptions[];
accessCodes: string[];
} & Transfer;
}
}
复制代码
跨线程通信各事务的响应数据类型声明
export declare namespace WorkerReponse {
namespace ExcelWorker {
type ExportStationData = {
data: any;
} & Transfer;
}
}
复制代码
主线程逻辑
src/worker/main-thread 下新建 excel.ts 文件,用于编写数据事务代码。
/**
* 第四步:声明主线程业务逻辑代码
* TODO
*/
export default class Excel extends BaseAction {
protected threadAction: IMainThreadAction;
/**
* 导出监测点数据
* @param payload
*/
public async exportStationReportData(payload?: WorkerPayload.ExcelWorker.ExportStationData): Promise {
return this.controller.requestPromise(TestActionType.ExportStationReportData, payload);
}
protected addActionHandler(): void {}
}
复制代码
主线程逻辑实例化
src/worker/main-thread/index 中引入 excel;
主线程声明事务命名空间
// 只声明事务命名空间, 用于事务中调用其他命名空间的事务
export interface IMainThreadAction {
// ....
excel: Excel;
}
复制代码
主线程声明事务实例化
export default class MainThreadWorker implements IMainThreadAction {
// ......
public excel: Excel;
public constructor(options: IAlloyWorkerOptions) {
// .....
this.excel = new Excel(this.controller, this);
}
// ........ 省略代码
}
复制代码
子线程逻辑
src/worker/worker-thread 下新建 excel.ts 文件,用于编写数据事务代码,此文件中是核心的数据导出功能。
数据请求、数据处理
export default class Test extends BaseAction {
protected threadAction: IWorkerThreadAction;
protected addActionHandler(): void {
this.controller.addActionHandler(TestActionType.ExportStationReportData, this.exportStationReportData.bind(this));
}
/**
* 获取数据查询
* @protected
*/
@HttpGet('/list')
protected async getDataList(@HttpParams() queryDataParams: QueryDataParams, factors?: SelectOptions[], @HttpRes() res?: any): Promise<{ total: number; list: TableRow[] }> {
return {list: res.rows}
}
/**
* 测试导出数据
* @private
*/
private async exportExcel(payload?: WorkerPayload.ExcelWorker.ExportExcel): Promise {
try {
// worker 中引入 xlsx
importScripts('https://cdnjs.cloudflare.com/ajax/libs/xlsx/0.16.9/xlsx.core.min.js');
const table: ObjectUnknown[] = [];
for (let i = 0; i < allList.length; i ++) {
const rows = {...allList[i]}
// 按需求处理时间格式
rows['tiemStr'] = moment(allList[i].dateTime).format('YYYY年MM月DD日 HH时')
for (let j = 0; j < allList[i].factorDatas.length; j ++) {
const code = allList[i].factorDatas[j].code
const value = allList[i].factorDatas[j].value
const grade = allList[i].factorDatas[j].grade
// 此处按需求异步获取等级数据---- 此方法已经尽可能的做了性能优化
const gradeStr = await UtilsSerice.getGradeInfo('surface', grade, 'value')
rows[code] = `${value}(${gradeStr})`
}
table.push(rows)
}
const downConfig: ExcelDownLoadConfig = {
tHeader: ['点位名称', '接入编码', '监测时间', '因子1', '因子2', '因子2' ],
bookType: 'xlsx',
autoWidth: 80,
filename: `数据查询`,
filterVal: ['name', 'code', 'tiemStr', 'w01010', 'w01011', 'w01012'],
multiHeader: [],
merges: []
};
const res = await ExcelService.downLoadExcelFile(table, downConfig, (self as any).XLSX);
// 由于之前提到的 worker 局限性(无法访问 DOM) 因此子线程中处理完 excel 所所需的对象后 将数据传递给主线程,由主线程进行数据导出
// 普通 postMessage 时会进行 树的克隆,但此处处理完的数据可能会非常大,估计直接将进行 transfer 传输数据
return {
transferProps: ['data'],
data: res.data,
filename: res.filename,
}
} catch (e) {
console.log(e);
}
}
}
复制代码
子线程逻辑实例化
src/worker/worker-thread/index 中引入 excel;
主线程声明事务命名空间
// 只声明事务命名空间, 用于事务中调用其他命名空间的事务
export interface IWorkerThreadAction {
// ....
excel: Excel;
}
复制代码
子线程声明事务实例化
class WorkerThreadWorker implements IWorkerThreadAction {
public excel: Excel
// ... 省略代码
public constructor() {
this.controller = new Controller();
this.excel = new Excel(this.controller, this);
// ... 省略代码
}
}
复制代码
至此,导出功能已完整迁移到子线程中。
主线程调用
主线程调用数据导出功能也很简单,首先实例化一个子线程,然后就可以愉快的将复杂的计算逻辑丢给子线程了,类似于这样。
class HomPage extends VueComponent {
public created() {
try {
// 实例化一个子线程,并将其挂载在 window 上
const alloyWorker = createAlloyWorker({
workerName: 'alloyWorker--test',
isDebugMode: true
});
}catch (e) {
console.log(e);
}
}
/**
* 子线程数据导出
* @private
*/
private async exportExcelFile() {
// 直接调用申明的方法就可以
(window as any).alloyWorker.excel.exportStationReportData({
factorList: factors,
accessCodes: [{ accessCode: 'sss', name: '测试监测点' }]
}).then((res: any) => {
// 大数据导出效果,子线程传回来的数据
console.log(res);
// 将子线程传回来的二进制数据转换为 Blob 方便文件保存
const file = new Blob([res.data], { type: 'application/octet-stream' });
// 保存文件
saveAs(file, res.filename);
});
}
}
复制代码
效果如下,可以明确感受到数据导出过程中,页面没有丝毫的卡顿之感。
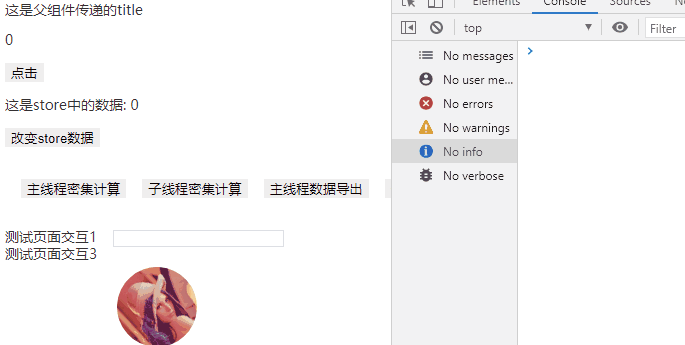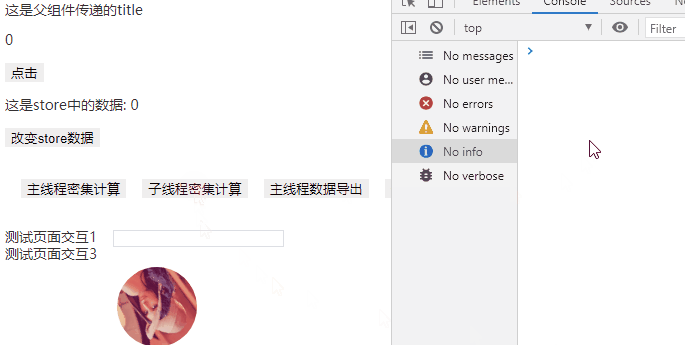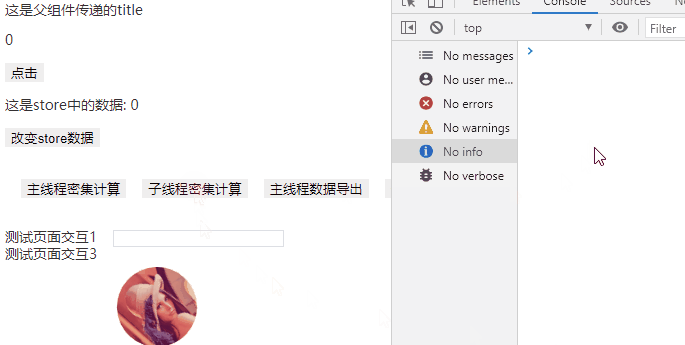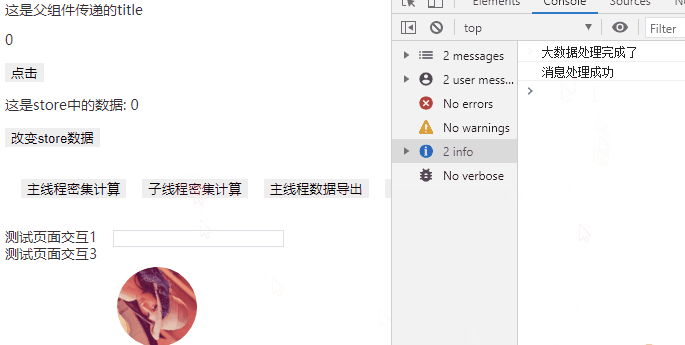
总结
以上代码中以一个真实的需求案例验证了 webWorker 对用户体验的提升是非常大的。这种需求在大多数的开发中可能也不多,但偶尔也会有。当然 webWorker 也并非是唯一解,在同等计算量的情况下,在子线程中做计算并不会比主线程快多少, 甚至会比主线程慢,因此只能将一些对及时反馈要求不高的计算放到子线程中计算。如果想单纯的提高计算效率,那只能从算法上入手或者使用 WebAssembly 来提高计算效率,关于 WebAssembly 在后续中可以再讲讲。
关于本文
来自:残月公子
https://juejin.cn/post/6970336963647766559
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
“分享、点赞、在看” 支持一波👍