
案例:使用K-Means对用户进行分群
K-Means 定义
K-Means 算法是聚类算法的一种,所以先了解聚类算法。
聚类分析是在没有给定划分类别情况下,根据数据相似度进行样本分组的一种方法。是一种无监督的学习算法。划分依据主要是自身的距离或相似度将他们划分为若干组,划分原则是组内样本最小化而组间(外部)距离最大化。聚类多数场景下用在「数据探索」环节,也就是用来了解数据。它无法提供明确的行动指向,更多是为后期挖掘和分析提供参考,无法回答“为什么”和“怎么办”的问题。
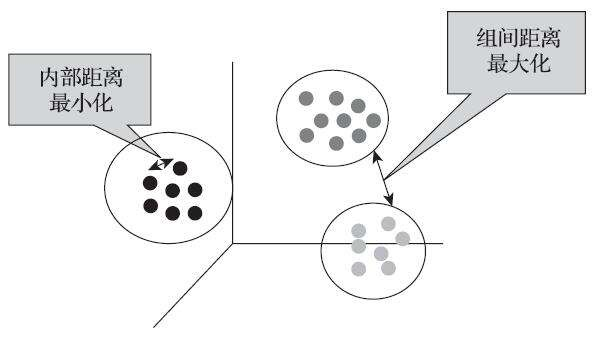
聚类分析和分类区别:分类是从特定的数据中挖掘模式,作出分类判断;聚类是根据数据本身特点,按照不同的模型来判断数据之间的相似性、相似性高的一组数据聚成一簇。
K-Means 算法是基于距离的聚类方法,在最小误差函数的基础上将数据划分为预定的类数 K,采用距离作为相似性的评价指标,认为两个对象的距离越近,其相似度越高。适用于连续型数据。使用场景可以是:用户分群分析。
算法过程
从 n 个样本数据中随机选取 K 个对象作为初始的聚类中心(在一开始确定 K 值上,凭业务经验划分,所以K值的选定不一定合理);
分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;
所有对象分配完成后,重新计算 K 个聚类的中心(类似重新计算虚拟中心);
与前一次计算得到的 K 个聚类中心比较,如果聚类中心发生变化,转至步骤 2,否则转至步骤 5;
当质心不发生变化时,停止并输出聚类结果;
度量距离:度量样本之间的相似性最常用的是欧几里得距离、曼哈顿距离和闵可夫斯基距离(Python 中目前支持欧氏距离)。
伪代码如图所示
初始质心如何确定比较好?
所以可以看到,在 K-Means 中有一个重要的环节,那就是如何放置初始质心,初始质心放置的位置不同,聚类的结果很可能不一样。一个好的初始质心可以避免更多的计算,让算法收敛稳定且更快。算法的第一步是在 n 个样本中随机抽取 K 个对象作为初始聚类中心,在初始的时候可能会生成在一起,导致算法运算慢且不收敛,对于此类问题可以采用 K-means++ 作为优化,其核心就是选择离已选中心点最远的点,初始质心相互间离得尽可能远。
如何确定K值?
在 K-Means 中,K 值是人为确定的,如果有业务经验,可以根据业务经验来判断,如果此类数据没有先验知识,也不知道如何聚类,划分的依据就依赖于组间差异最大化,组内差异最小化的评估指标。对于这个问题可以采用轮廓系数来判定,轮廓系数的取值为(-1,1),轮廓系数越接近于 1 越好,负数则表示聚类效果非常差。单个样本的轮廓系数计算公式如下: a:样本与其自身所在的簇中的其他样本的相似度,等于样本与同一簇中所有其他点之间的平均距离;
a:样本与其自身所在的簇中的其他样本的相似度,等于样本与同一簇中所有其他点之间的平均距离;
b:样本与其他簇中的样本的相似度,等于样本与下一个最近的簇中的所有点之间的平均距离。
值越接近 1 表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似;越接近 -1 说明样本点与簇外的样本更相似,与簇内样本不相似;当轮廓系数接近 0 时,则代表簇类差异和簇外差异的样本相似度一致,无明显分界。
K-Means 案例演示
数据集:航空公司客户特征字段。
分析流程为:
import pandas as pd
import numpy as np
import os
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.family'] = ['Arial Unicode MS']
pd.set_option('display.max_columns', None)
# sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
os.chdir('/data')
df = pd.read_csv('air_data.csv')
df.head()
 部分数据字段
部分数据字段
描述性统计分析
查看整体数据描述性分析
explore = df.describe(percentiles=[], include='all').T
explore
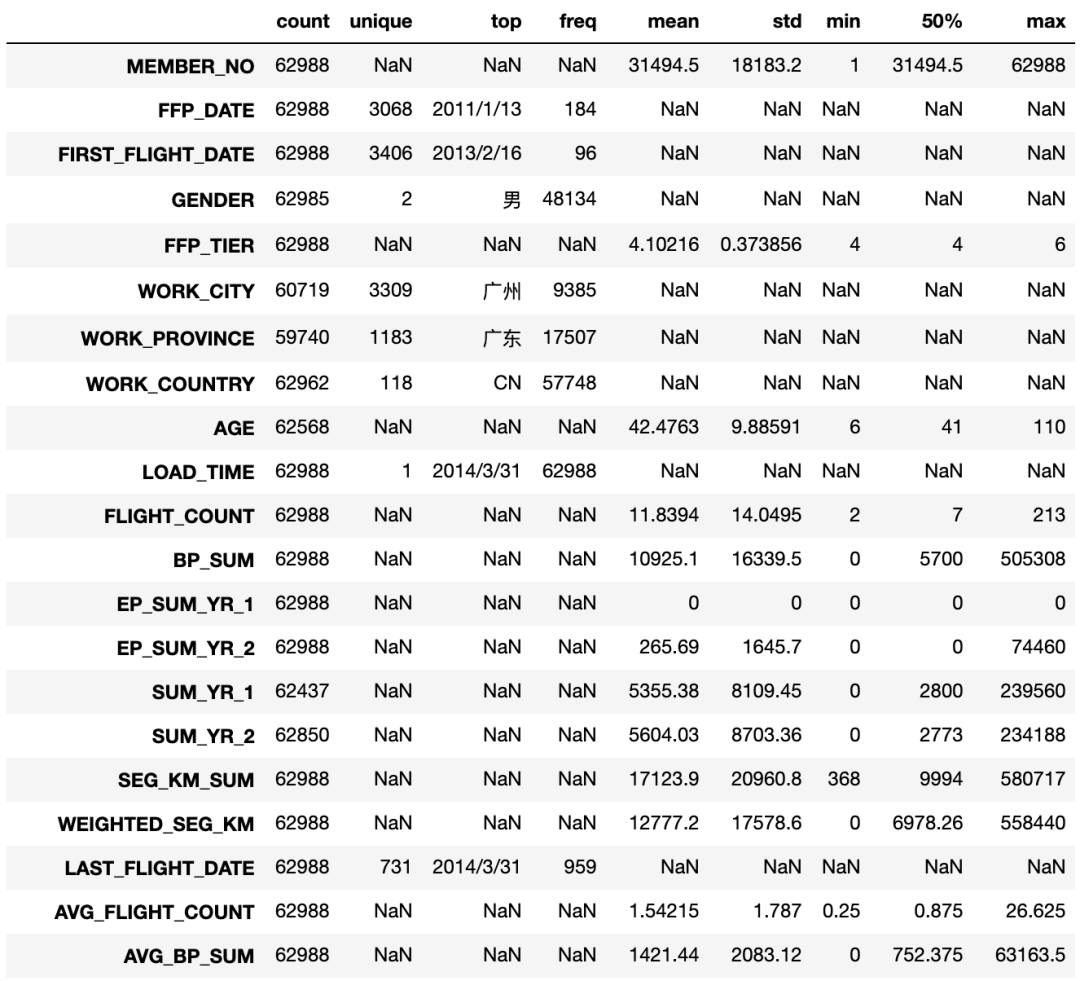 部分数据字段
部分数据字段
explore['null'] = len(df) - explore['count']
df_check = explore[['null', 'max', 'min']]
df_check.columns = [['空值记录数', '最大值', '最小值']]
df_check
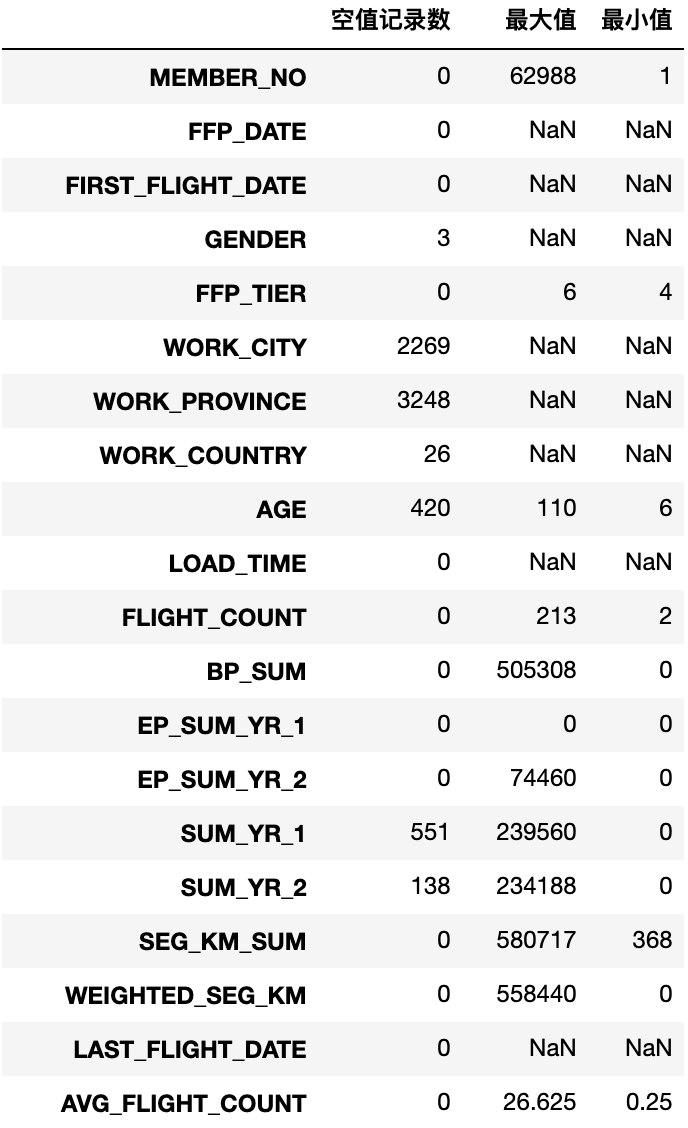 部分数据字段
部分数据字段
查看单个主体变量会员逐年增长情况
df['FFP_DATE_year'] = pd.to_datetime(df['FFP_DATE']).dt.year
# 获取每个年份的合计数量。方式一
count = df['FFP_DATE_year'].value_counts(sort=False).reset_index()
# 获取每个年份的合计数量。方式二
# count = df.groupby('FFP_DATE')['FFP_DATE'].count()
count.columns = ['入会时间', '入会人数']
count.plot(kind='bar', x='入会时间', y='入会人数', figsize=(12,8))
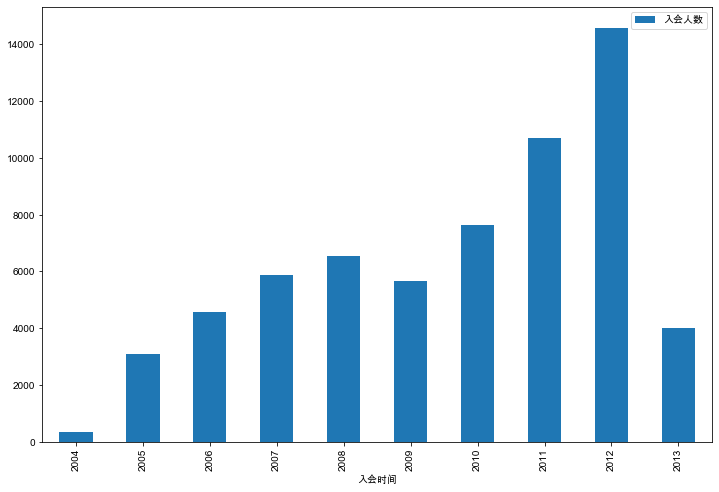
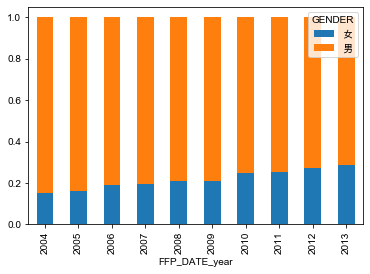
查看单个分类型变量比例变化情况(直方堆积图)
# 使用数据交叉表,计算每个年度时间节点,出现男女分类的数量情况
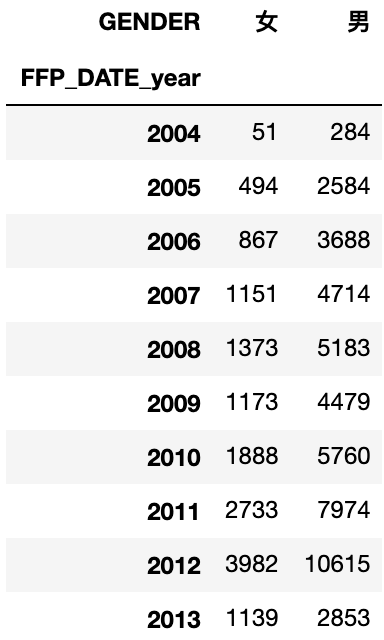
cross_table = pd.crosstab(index=df['FFP_DATE_year'],columns=df['GENDER'])
cross_table
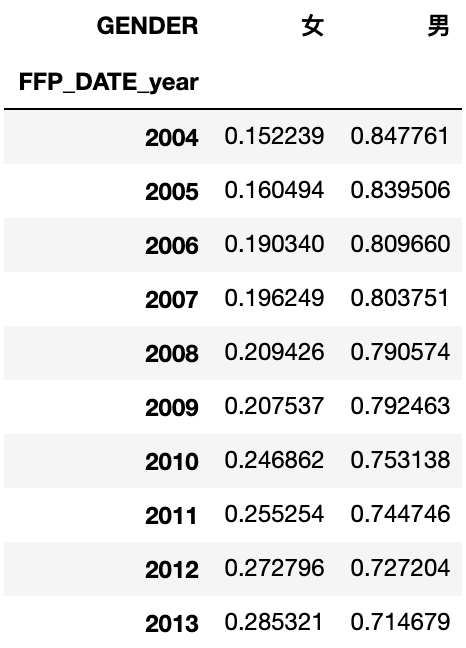
# 通过div函数,让分组每行合计等于1,用来看每个分组占比
cross_table = cross_table.div(cross_table.sum(1), axis=0)
cross_table
cross_table.plot(kind='bar', stacked=True)
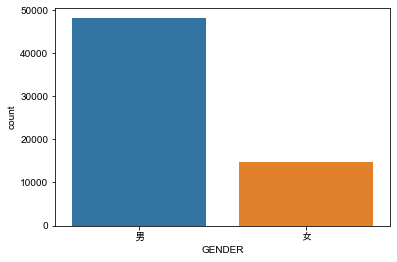
查看单个分类型变量占比情况(直方图&饼图)
# 男女分别数量合计占比
sns.countplot(x='GENDER',data=df)
# 男女会员分别所有数量。方式一
# male_count = df.groupby('GENDER')['GENDER'].count()[0]
# female_count = df.groupby('GENDER')['GENDER'].count()[1]
# 方式二
male_count = pd.value_counts(df['GENDER'])['男']
female_count = pd.value_counts(df['GENDER'])['女']
plt.pie([male_count, female_count],
labels=['男', '女'],
colors=['lightskyblue', 'lightcoral'],
autopct='%1.1f%%',
)
plt.show

查看单个分类型变量频数情况(直方图)
# 方式一: 直接使用sns.countplot 查看单个变量的分类情况
# sns.countplot(x='FFP_TIER',data=df)
# 方式二:
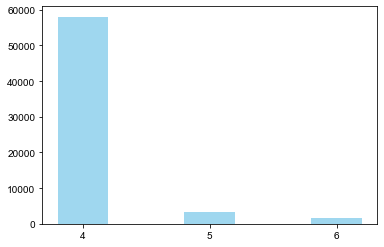
FFP_TIER_Level4 = pd.value_counts(df['FFP_TIER'])[4]
FFP_TIER_Level5 = pd.value_counts(df['FFP_TIER'])[5]
FFP_TIER_Level6 = pd.value_counts(df['FFP_TIER'])[6]
plt.bar(x=range(3),
height=[FFP_TIER_Level4, FFP_TIER_Level5, FFP_TIER_Level6],
width=0.4,
alpha=0.8,
color='skyblue')
plt.xticks([index for index in range(3)], [4, 5, 6])
plt.show()
查看单个数值型变量分布情况(箱型图)
# 会员年龄分布箱型图
plt.figaspect
plt.boxplot(df['AGE'].dropna(),
patch_artist=True,
vert=False,
boxprops = {'facecolor': 'lightblue'},
labels=['会员年龄'])
plt.grid(linestyle=":", color="r")
plt.title('会员年龄分布箱型图')
plt.show()

相关性分析
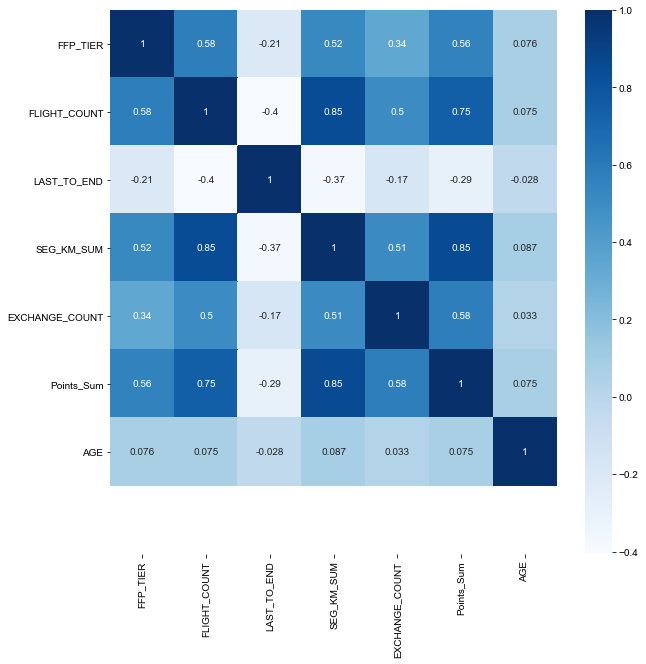
# 'FFP_TIER','FLIGHT_COUNT','LAST_TO_END','SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum','FFP_DATE'的相关系数分析
df_corr = df.loc[:, ['FFP_TIER','FLIGHT_COUNT','LAST_TO_END','SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum','FFP_DATE']]
age1 = df['AGE'].fillna(0)
df_corr['AGE'] = age1.astype('int64')
# df的相关系数
df_corr = df_corr.corr()
df_corr

# 设置图形大小
plt.subplots(figsize=(10,10))
# 特征数据热力图
ax = sns.heatmap(df_corr, annot=True, cmap='Blues')
ax.set_ylim([8, 0])
ax
数据预处理
数据清洗
# 去除票价为空的行
airline_notnull = df.loc[df['SUM_YR_1'].notnull() & df['SUM_YR_2'].notnull(), :]
# 保留票价非零数据,或者平均折扣率不为零且总飞行数大于0的记录;AGE去除大于100的记录
index1 = airline_notnull['SUM_YR_1'] != 0
index2 = airline_notnull['SUM_YR_2'] != 0
index3 = (airline_notnull['SEG_KM_SUM'] > 0) & (airline_notnull['avg_discount'] != 0)
index4 = airline_notnull['AGE'] > 100
airline = airline_notnull[(index1 | index2) & index3 & ~index4]
airline.head()
 部分数据字段
部分数据字段
属性归约
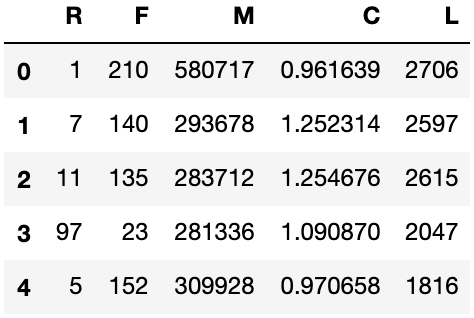
airline = airline[['FFP_DATE', 'LOAD_TIME', 'LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount' ]]
airline['FFP_DATE'], airline['LOAD_TIME'] = pd.to_datetime(airline['FFP_DATE']), pd.to_datetime(airline['LOAD_TIME'])
airline['L'] = (airline['LOAD_TIME'] - airline['FFP_DATE']).dt.days
airline = airline.drop(['FFP_DATE', 'LOAD_TIME'], axis=1)
airline.columns = ['R', 'F', 'M', 'C', 'L']
airline.head()
数据标准化
from sklearn.preprocessing import StandardScaler
data = StandardScaler().fit_transform(airline)
data[:5, :]
array([[-0.94493902, 14.03402401, 26.76115699, 1.29554188, 1.43579256],
[-0.91188564, 9.07321595, 13.12686436, 2.86817777, 1.30723219],
[-0.88985006, 8.71887252, 12.65348144, 2.88095186, 1.32846234],
[-0.41608504, 0.78157962, 12.54062193, 1.99471546, 0.65853304],
[-0.92290343, 9.92364019, 13.89873597, 1.34433641, 0.3860794 ]])
聚类分析
from sklearn.cluster import KMeans
# 构建模型,随机种子设为123
kmeans_model = KMeans(n_clusters=5, n_jobs=4, random_state=123)
# 模型训练
fit_kmeans = kmeans_model.fit(data)
# 查看聚类结果
kmeans_cc = kmeans_model.cluster_centers_
kmeans_cc
# 样本的类别标签
kmeans_lable = kmeans_model.labels_
# 统计不同类别样本数目
pd.Series(kmeans_model.labels_).value_counts()
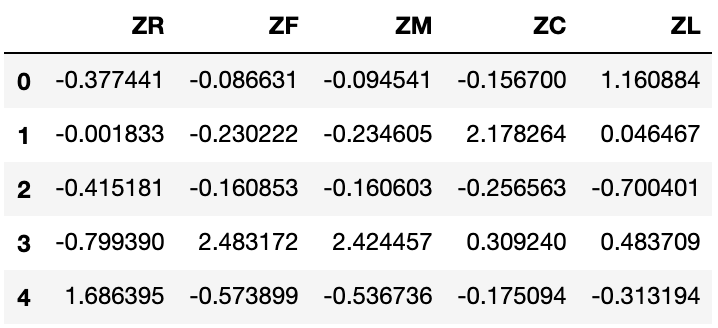
cluster_center = pd.DataFrame(kmeans_model.cluster_centers_, columns=['ZR','ZF','ZM','ZC','ZL'])
# cluster_center.index = pd.DataFrame(kmeans_model.labels_).drop_duplicates().iloc[:,0]
cluster_center
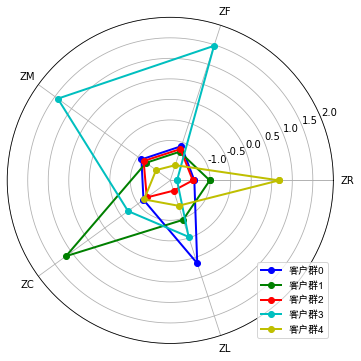
聚类分析可视化(雷达图)
#标签
labels = cluster_center.columns
#数据个数
k = 5
plot_data = kmeans_model.cluster_centers_
#指定颜色
color = ['b', 'g', 'r', 'c', 'y']
angles = np.linspace(0, 2*np.pi, k, endpoint=False)
# 闭合
plot_data = np.concatenate((plot_data, plot_data[:,[0]]), axis=1)
# 闭合
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(figsize=(8,6))
#polar参数
ax = fig.add_subplot(111, polar=True)
for i in range(len(plot_data)):
ax.plot(angles, plot_data[i], 'o-', color = color[i], label = u'客户群'+str(i), linewidth=2)# 画线
ax.set_rgrids(np.arange(0.01, 3.5, 0.5), np.arange(-1, 2.5, 0.5), fontproperties="SimHei")
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
plt.legend(loc = 4)
plt.show()
注:以上案例数据集来源于《Python数据分析与挖掘实战(第2版)》,但是整体分析流程有调整。可以互相查阅学习。
需要了解可以关注公众号,在对话框回复“0103”获取数据集 + 代码。