
LeetCode刷题实战15题: 三数之和
共 5409字,需浏览 11分钟
·
2020-08-19 18:07
算法的重要性,我就不多说了吧,想去大厂,就必须要经过基础知识和业务逻辑面试+算法面试。所以,为了提高大家的算法能力,这个公众号后续每天带大家做一道算法题,题目就从LeetCode上面选 !
今天和大家聊的问题叫做三数之和 ,我们先来看题面:
https://leetcode.com/problems/3sum/
描述
给定一个整数的数组,要求寻找当中所有的a,b,c三个数的组合,使得三个数的和为0.注意,即使数组当中的数有重复,同一个数也只能使用一次。
Given an array nums of n integers, are there elements a , b , c innums such that a + b + c = 0? Find all unique triplets in the array
which gives the sum of zero.
Note:
The solution set must not contain duplicate triplets.
样例
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
题解
这道题是之前LeetCode第一题2 Sum的提升版,在之前的题目当中,我们寻找的是和等于某个值的两个数的组合。而这里,我们需要找的是三个数。从表面上来看似乎差别不大,但是实际处理起来要麻烦很多。
暴力求解
我们先理一下思路,从最简单的方法开始入手。这题最简单的方法当然就是暴力法,我们已经明确了要找的是三个数的和,既然数量确定了,就好办了,我们直接枚举所有三个数的组合,然后所有和等于0的组合就是答案。但是这里有一个小问题,当我们找到了答案之后,我们并不能直接返回,因为数组当中重复的元素很有可能会导致答案的重复,我们必须要去掉这些重复的答案,保证答案当中每一个都是唯一的。
那我们先对原数组做处理,去除掉其中重复的元素之后再来寻找答案可不可以呢?
很遗憾,这个想法很好,但是不可行。原因也很简单,因为答案不能重复,但是答案里的数是可以重复的。
举个例子,比如数组是[-1, -1, 2, 0, -2],那么[-1, -1, 2]是一个答案,如果一开始就出去掉了重复的-1,那么这个答案显然就无法构成了。唯一的解决方法是用容器来维护答案,保证容器内的答案是唯一的,不过这个会带来额外的时间和空间开销。
所以,总体看来,暴力枚举并不是个好方法,复杂度不低,如果使用C++和Java等语言的话,使用容器也很麻烦。
ret = set()for i in range(n):for j in range(i+1, n):for k in range(j+1, n):if a[i] + a[j] + a[k] == 0:ret.add((i, j, k))return list(ret)
利用2 Sum
还有一个思路是利用之前的2 Sum的解法,在之前的2 Sum问题当中,我们通过巧妙地使用map,来达成了在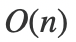 复杂度内找到了所有和等于某个值的元素对。所以,我们可以先枚举第一个数的大小,然后在剩下的元素当中进行2 Sum操作。
复杂度内找到了所有和等于某个值的元素对。所以,我们可以先枚举第一个数的大小,然后在剩下的元素当中进行2 Sum操作。
假设我们枚举的数是a[i],那么我们在剩下的元素当中做2 Sum,来寻找和等于-a[i]的两个数。最后,将这三个数组成答案。如果遗忘2 Sum解法的同学可以点击下方链接回到之前的文章。LeetCode 1 Two Sum——在数组上遍历出花样
这个方法看起来巧妙很多,但是还是逃不掉重复的问题。举个例子:[-1, -1, -1, -1, -1, 2]。如果我们枚举-1,那么会出现多个[-1, -1, 2]的结果。所以我们依然免不了手动过滤重复的答案。不过利用2 Sum的解法要比暴力快一些,因为2 Sum的时间复杂度是,再乘上枚举元素的复杂度,不考虑去重情况下的整体复杂度是O(n^2),要比枚举的O(n^3)更优。
我们利用2 sum写出新的算法:
def two_sum(array, idx, target):"""two sum的部分"""n = len(array)ret = []# 用来记录所有出现过的元素appear = set()# 用来判断2 sum的答案出现重复used = set()for i in range(idx + 1, n):# 如果 target - array[i]之前出现过,说明可以构成答案if target - array[i] in appear:# 判断答案是否重复if array[i] in used or target - array[i] in used:continue# 记录used.add(array[i])used.add(target - array[i])ret.append((array[i], target - array[i]))appear.add(array[i])return retdef three_sum(array):n = len(array)# 记录枚举过的元素used = set()ret = []# 防止答案重复duplicated = set()for i in range(n):# 如果出现过,说明已经枚举过,跳过if array[i] in used:continue# 拿到2 sum的答案combinations = two_sum(array, i, -array[i])if len(combinations) > 0:for combination in combinations:# 组装答案answer = tuple(sorted((array[i], *combination)))# 判断答案是否重复if answer in duplicated:continue# 记录ret.append(answer)duplicated.add(answer)used.add(array[i])return ret
尺取法
这题的另一个解法是尺取法,也就是two pointers,也叫做两指针算法。这个在我们之前的文章当中也有过介绍,有遗忘或者错过的同学可以点击下方的链接回顾一下。LeetCode3 一题学会尺取算法
尺取法的精髓是通过两个指针控制一个区间,保证区间满足一定的条件。在这题当中,我们要控制的条件其实是三个数的和。由于我们的指针数量是2,也就是说我们只有两个指针,但是我们却需要找到三个数组成的答案。显然,我们直接使用尺取法是不行的。我们稍作变通就可以解决这个问题,就是第一个解法的思路,我们先枚举一个数,然后再通过尺取法去寻找另外两个数。
使用尺取法需要我们根据现在区间内的信息,制定策略如何移动区间。显然,如果区间里的数杂乱无章,我们是很难知道应该怎么维护区间的。所以我们首先对数组当中的元素进行排序,保证元素的有序性。区间里的元素有序了,那么我们就方便了。
假设我们当前枚举的数是a[i],那么我们就需要找到另外的两个数b和c,使得b + c = -a[i]。对于每一个i来说,这样的b和c可能存在,也可能不存在,我们必须要寻找过了才知道。
和2 Sum一样,为了优化时间复杂度,加快算法的效率,我们需要人为设置一些限制。我们限制b和c只能在a的右侧,当然也可以限制在一左一右,总之,我们需要把这三个数的顺序固定下来。因为三个数调换顺序只会产生重复,所以我们固定顺序可以避免重复。所以我们枚举a的位置之后,在a的右侧通过尺取法寻找另外两个元素。
方法也很简单,我们一开始设置b的位置是i+1, c的位置是n。如果b+c > -a,那么说明两者的和过大,因为b已经是最小值了,所以只能将c向左移动。如果b+c < -a,说明两者的和过小,需要增大,所以应该将b往右侧移动增大数值。如此往复,当这个区间遍历完成之后,继续移动a的位置,寻找下一组解,这里需要注意,a需要跳过所有重复的数字,避免重复。
我们写出代码:
def three_sum(array):n = len(array)# 先对array进行排序array = sorted(array)ret = []for i in range(n-2):# 判断第一个数是否重复if i > 0 and array[i] == array[i-1]:continueused.add(array[i])# 进行two pointers缩放j = i + 1k = n - 1target = -array[i]if target < 0:breakwhile j < k:cur_sum = array[j] + array[k]# 判断当前区间的结果和目标的大小if cur_sum < target:j += 1continueelif cur_sum > target:k -= 1continue# 记录ret.append(answer)# 继续缩放区间,寻找其他可能的答案j += 1while j < k and array[j] == array[j-1]:j += 1k -= 1while j < k-1 and array[k] == array[k+1]:k -= 1return ret
写出代码之后,我们来分析一下算法的复杂度。一开始的时候,我们对数组进行排序,众所周知,排序的复杂度是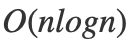 。之后,我们枚举了第一个数,开销是,我们进行区间缩放的复杂度也是,所以整个主体程序的复杂度是
。之后,我们枚举了第一个数,开销是,我们进行区间缩放的复杂度也是,所以整个主体程序的复杂度是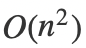 。看似和上面一种方法区别不大,但是我们节省了set重复的判断,由于hashset读取会有时间开销,所以虽然算法的量级上没什么差别,但是常数更小,真正运行起来这种算法要快很多。
。看似和上面一种方法区别不大,但是我们节省了set重复的判断,由于hashset读取会有时间开销,所以虽然算法的量级上没什么差别,但是常数更小,真正运行起来这种算法要快很多。
这题官方给的难度是Medium,但实际上我觉得比一般的Medium要难上一些,代码量也要大上一些。今天文章当中列举的并不是全部的解法,其他的做法还有很多,比如对所有数进行分类,分成负数、零和正数,然后再进行组装等等。感兴趣的同学可以自己思考,看看还有没有其他比较有趣的方法。
今天的文章就到这里,如果觉得有所收获,请顺手点个在看或者转发吧,你们的支持是我最大的动力。
上期推文: