
全新Backbone | Pale Transformer完美超越Swin Transformer


最近,Transformer在各种视觉任务中表现出了良好的性能。为了降低全局自注意力引起的二次计算复杂度,各种方法都限制局部区域内的注意力范围,以提高全局自注意力的计算效率。因此,它们在单个注意力层中的感受野不够大,导致上下文建模不足。
为了解决这个问题,本文提出了一种Pale-Shaped self-Attention(PS-Attention),它在一个Pale-Shaped的区域内进行自注意力的计算。与全局自注意力相比,PS-Attention能显著减少计算量和内存开销。同时,利用已有的局部自注意力机制,可以在相似的计算复杂度下获取更丰富的上下文信息。
在PS-Attention的基础上,作者开发了一个具有层次结构的通用Vision Transformer Backbone,名为Pale Transformer,在224×224 ImageNet-1K分类中,模型尺寸分别为22M、48M和85M, Top-1准确率达到83.4%、84.3%和84.9%,优于之前的Vision Transformer Backbone。对于下游的任务,Pale Transformer Backbone在ADE20K语义分割和COCO目标检测和实例分割上比最近的最先进的CSWin Transformer表现得更好。
1简介
受Transformer在自然语言处理(NLP)的广泛任务上取得成功的启发,Vision Transformer(ViT)首次采用纯Transformer架构进行图像分类,这显示了Transformer架构在视觉任务方面的良好性能。
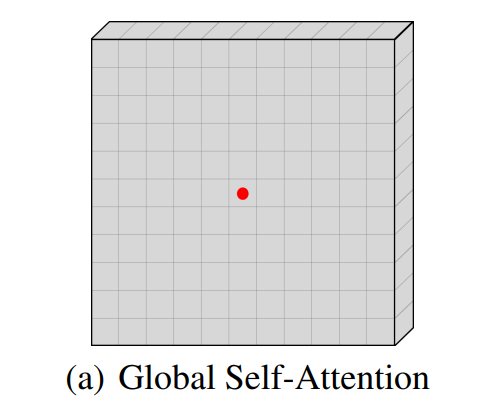
然而,全局自注意力的二次复杂度导致了昂贵的计算成本和内存占用,特别是在高分辨率场景下,使其无法用于下游各种视觉任务。
一种典型的提高效率的方法是用局部自注意力取代全局自注意力。如何增强局部环境下的建模能力是一个关键而又具有挑战性的问题。
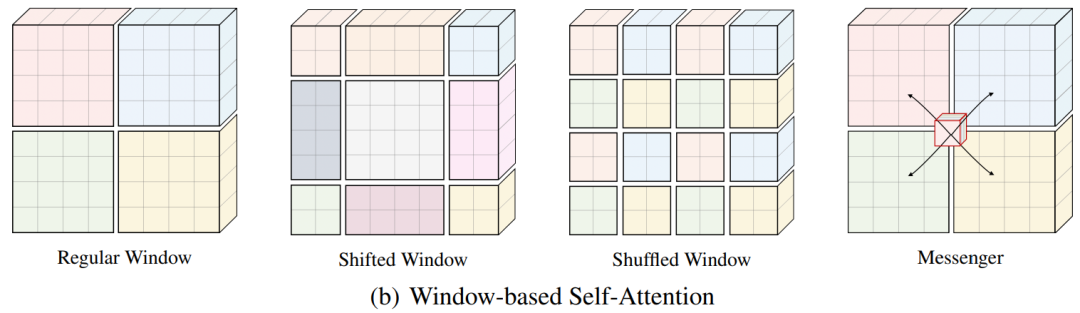
例如,Swin Transformer和Shuffle Transformer分别提出了Shift Window和Shuffle Window(图1(b)),并交替使用两种不同的Window分区(即Regular Window和Proposed Window)在连续块中构建Cross Window连接。

MSG Transformer操纵Messenger Token以实现Cross Window交换信息。Axial Self-Attention将局部注意力区域视为特征图的单行或单列(图1(c))。

CSWin提出了Cross-Shaped Window Attention(图1(d)),可以看作是Axial Self-Attention的多行、多列展开。虽然这些方法的性能很好,甚至优于CNN的同类方法,但每个自注意力层的依赖关系不够丰富,不足以捕捉足够的上下文信息。

在这项工作中提出了一种Pale-Shaped self-Attention(PS-Attention)来有效地捕获更丰富的上下文依赖。具体来说:
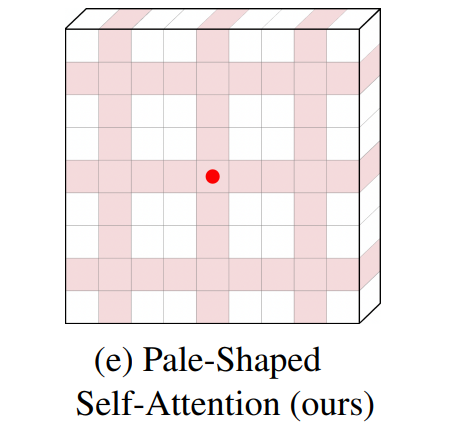
首先将输入特征图在空间上分割成多个Pale-Shaped的区域。每个Pale-Shaped区域(缩写为Pale)由特征图中相同数量的交错行和列组成。相邻行或列之间的间隔对于所有的Pale是相等的。例如,图1(e)中的粉色阴影表示其中一种淡色。
然后,在每个Pale区域内进行Self-Attention计算。对于任何Token,它都可以直接与同一Pale中的其他Token交互,这使得本文的方法能够在单个PS-Attention层中捕获更丰富的上下文信息。
为了进一步提高效率,作者开发了一个更高效的PS-Attention并行实现。得益于更大的感受野和更强的上下文建模能力,PS-Attention显示出了图1中所示的现有局部自注意力机制的优越性。
本文基于提出的PS-Attention设计了一个具有层次结构的通用Vision T燃烧former Backbone,命名为Pale Transformer。作者将本文的方法扩展到一系列模型,包括Pale-T(22M)、Pale-S(48M)和Pale-B(85M),达到了比以前方法更好的性能。
Pale-T在ImageNet-1k上的Top-1分类准确率为83.4%,在ADE20K上的单尺度mIoU(语义分割)准确率为50.4%,在COCO上的box mAP(目标检测)准确率为47.4,mask mAP(实例分割)准确率为42.7,分别比目前最先进的Backbone算法提高了+0.7%、+1.1%、+0.7和+0.5。
此外,最大的版本Pale-B在ImageNet-1K上的Top-1准确率为84.9%,在ADE20K上的单尺度mIoU准确率为52.2%,在COCO上的box mAP为49.3,mask mAP为44.2。
2相关工作
ViT将输入图像作为一系列的Patches,为多年来由CNN主导的视觉任务开辟了一条新的道路,并显示出了良好的性能。为了更好地适应视觉任务,之前的Vision Transformer Backbone工作主要集中在以下两个方面:
增强Vision Transformer的局部性;
在性能和效率之间寻求更好的平衡。
2.1 局部增强ViTs
与CNN不同的是,原始Transformer没有涉及到局部连接的感应偏置,这可能会导致对线、边缘、颜色结合点等局部结构的提取不足。
许多工作致力于增强ViT的局部特征提取。最早的方法是用分层结构取代单一尺度结构,以获得多尺度特征。这样的设计在以后的作品中也有很多。
另一种方法是把CNN和Transformer结合起来。Mobile-Former、Conformer和DSNet通过精心设计的双分支结构集成了CNN和Transformer功能。而Local ViT、CvT和Shuffle Transformer只在Transformer的某些组件中插入了几个卷积。此外,一些作品通过融合不同尺度的多分支或配合局部自注意力以获得更丰富的特征。
2.2 高效ViTs
目前主流的研究方向为提高效率Vision Transformer的主干有两层:
通过剪枝策略减少冗余计算 设计更高效的自注意力机制
1、ViT的剪枝
对于剪枝,现有的方法可以分为三类:
Token剪枝:DVT提出了一种级联Transformer结构,可以根据输入图像自适应调整Token数量。考虑到Token含有不相关甚至混淆的信息可能不利于图像分类,一些研究提出了通过可学习采样和强化学习策略来定位有区别的区域,逐步减少信息Token的丢弃。然而,这种非结构化的稀疏性导致了与密集预测任务的不兼容性。通过Token Pooling和Slow-Fast更新实现了一些结构保持的Token选择策略。
Channel剪枝:VTP为去除Reductant Channel提供了一个简单而有效的框架。
Attention Sharing:基于连续块间注意力映射高度相关的观测结果,提出了PSViT算法来重用相邻层间的注意力计算过程。
2、高效Self-Attention机制
考虑到二次计算的复杂度是由Self-Attention引起的,许多方法致力于在避免性能衰减的同时提高二次计算的效率。
一种方法是减少key和value的序列长度:
PVT提出了一种Spatial Reduction Attention,在计算注意力之前对key和value的尺度进行下样。
Deformable Attention使用一个线性层从全集合中选择几个关键字,可以看作是全局自注意力的稀疏版本。但是,过多的下采样会导致信息混淆,Deformable Attention严重依赖于CNN学习的High-Level特征图,可能不能直接用于原始输入图像。
另一种方法是将全局自注意力替换为局部自注意力,将每个自注意层的范围限制在一个局部区域内。如图1(b)所示,首先将特征映射划分为几个不重叠的方形规则窗口(用不同的颜色表示),在每个窗口内分别进行自注意力计算。
设计局部自注意力机制的关键挑战是如何弥合局部和全局感受野之间的差距?
一种典型的方式是在规则的方形窗口之间构建连接。例如,在连续块中交替使用常规窗口和另一种新设计的窗口分区方式(图1(b)中Shift Window或Shuffle Window),并操作Messenger Tokens来跨窗口交换信息。
此外,Axial Attention通过对特征图的每一行或每一列进行自注意力计算,分别在水平和垂直方向上获得较长的距离依赖。
CSWin提出了一个包含多行多列的Cross-Shaped Self-Attention区域。现有的这些局部注意力机制虽然在一定程度上提供了突破局部感受野的机会,但它们的依赖关系不够丰富,不足以在单个自注意力层中捕获足够的上下文信息,从而限制了整个网络的建模能力。
与本文的工作最相关的是CSWin,CSWin开发了一个Cross-Shaped Self-Attention用于计算水平和垂直条纹中的自注意力,而本文提出的PS-Attention计算Pale形状区域的自注意力。此外,本文的方法中每个Token的感受野比CSWin宽得多,这也赋予了本文的方法更强的上下文建模能力。
3本文方法
在本节中,首先介绍Pale-Shaped Self-Attention(PS-Attention)及其高效的并行实现。然后,给出了Pale Transformer block的组成。最后,将描述Pale Transformer Backbone的总体架构和变体配置。
3.1 Pale-Shaped Attention
为了捕获从短期到长期的依赖关系,提出了Pale-Shaped Attention(PS-Attention),它在一个Pale-Shaped区域(简称pale)中计算自注意力。如图1(e)的粉色阴影所示,一个pale包含个交错的行和个交错的列,它覆盖了包含个Token的区域。
定义为pale size。给定一个输入特征图,首先将其分割成多个相同大小的pale ,其中。Pale的个数等于,可以通过填充或插补操作来保证。对于所有pale,相邻行或列之间的间隔是相同的。然后在每个pale中分别进行自注意力计算。如图1所示,PS-Attention的感受野比之前所有的局部自注意力机制都要广泛和丰富得多,能够实现更强大的上下文建模能力。
3.2 高效的并行实现
为了进一步提高效率,将上面提到的普通PS-Attention分解为行注意和列注意,它们分别在行Token组和列Token组内执行自注意力。
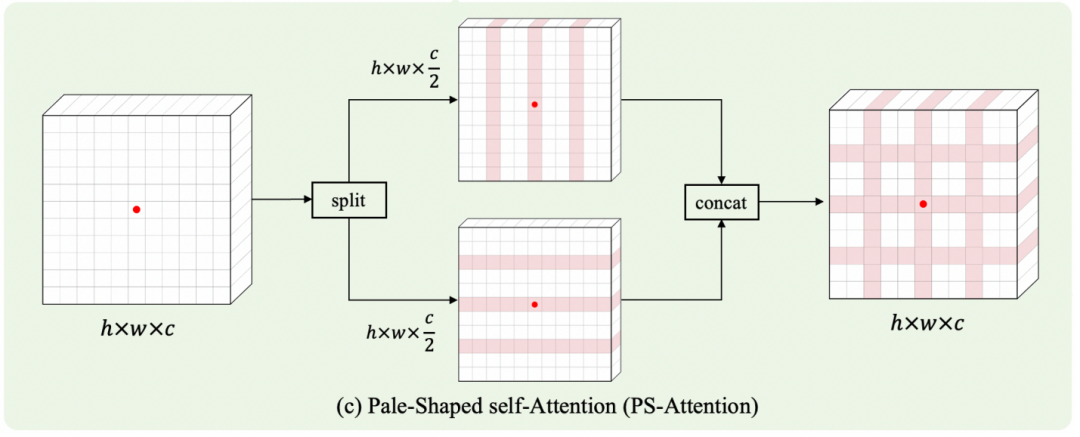
具体而言,如图2(c),首先将输入特征划分为两个独立的部分和,然后将其分为多个组,以便分别按行和列进行注意力计算。
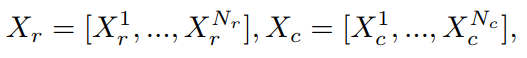
其中,包含个的交错行,包含个的交错列。
然后,分别在每个行Token组和列Token组中执行自注意力。使用3个可分离的卷积层、、生成Query、Key和Value。
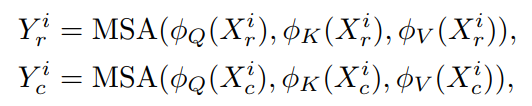
式中,、MSA表示多头自注意力。
最后,行方向和列方向的注意力输出沿着通道尺寸连接,得到最终的输出:

与PS-Attention在整个系统内的普通实现相比,这种并行机制具有较低的计算复杂度。此外,填充操作只需要确保能被整除,能被整除,而不是。因此,也有利于避免填充过多。
3.3 复杂度分析
给定尺寸为h×w×c的输入特征,Pale-size为,标准全局自注意力的计算复杂度为:
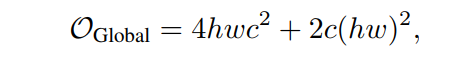
然而,本文提出的PS-Attention并行实现下的计算复杂度为:
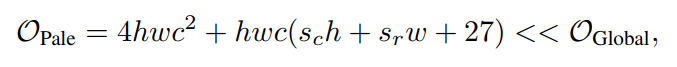
由于始终保持不变,因此与全局算法相比,可以明显减轻计算量和内存负担。
3.4 Pale Transformer Block
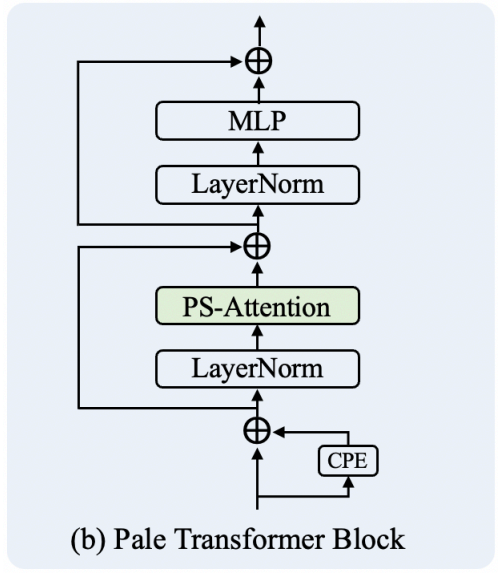
如图2(b)所示,Pale Transformer Block由3个顺序部分组成,用于动态生成位置嵌入的条件位置编码(CPE),用于捕获上下文信息的PS-Attention模块,以及用于特征投影的MLP模块。第l块的传播可以表示为:

其中,LN(·)为层归一化。CPE被实现为一个简单的深度卷积,它在以前的工作中广泛使用,因为它兼容任意大小的输入。Eq.(7)中定义的PS-Attention模块是通过将Eq.(1)对Eq.(3)依次执行来构造的。Eq.(8)中定义的MLP模块由2个线性投影层组成,依次展开和收缩嵌入维数。
3.5 整体框架
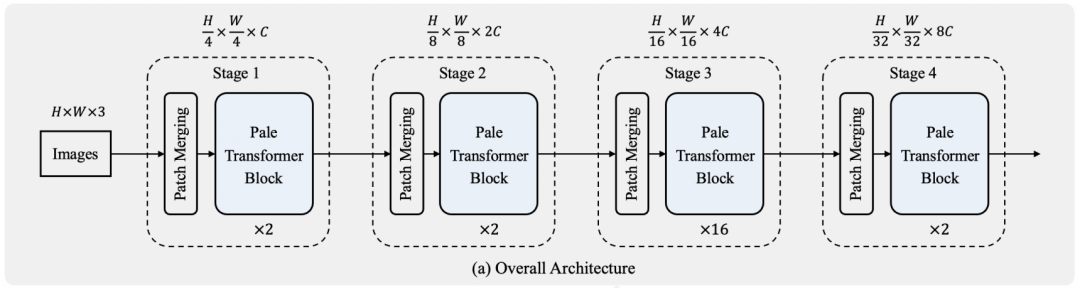
如图2(a)所示,Pale Transformer通过遵循CNN和Transformer的设计,由四个层次级阶段组成,用于捕获多尺度特征。每个阶段包含一个Patch合并层和多个Pale Transformer Block。patch merge层的目标是对输入特征进行一定比例的空间下采样,并将通道维数扩展2倍以获得更好的表示能力。
为了便于比较,使用重叠卷积来进行Patch合并。其中,第一阶段空间下采样比为4,后三个阶段空间下采样比为2,分别采用7×7与stride=4的卷积和3×3与stride=2的卷积实现。Patch合并层的输出被输入到后续的Pale Transformer Block中,Token的数量保持不变。只需在最后一个块的顶部应用平均池化操作,以获得最终分类头的代表Token,该分类头由单个线性投影层组成。
具体变体如下:


4实验
4.1 消融实验
1、Pale-size的影响
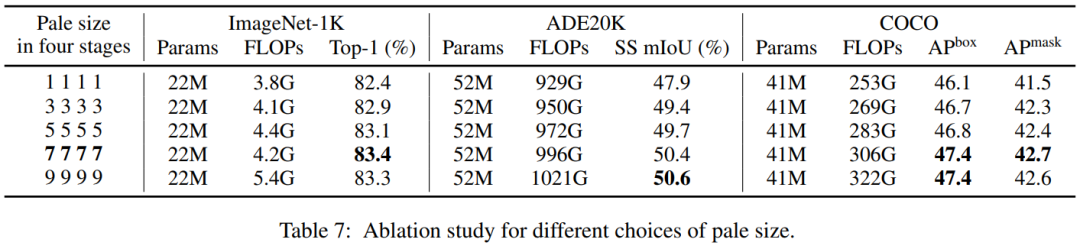
4个阶段的Pale-size控制了上下文信息丰富度与计算成本之间的权衡。如表7所示,增加Pale-size(从1到7)可以持续提高所有任务的性能,而进一步增加到9不会带来明显的、持续的改进,但会带来更多的FLOPs。因此,默认情况下,对所有任务使用。
2、不同注意力对比
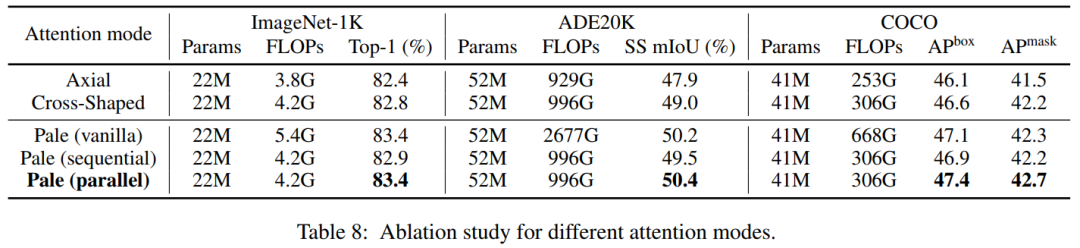
这里比较了3种PS-Attention的实现。普通的PS-Attention直接在整个Pale区域内进行自注意力计算,它可以近似为两种更有效的实现,顺序和并行。
顺序算法在连续块中交替计算行方向和列方向上的自注意力,而并行算法在每个块内并行执行行方向和列方向的注意力。如表8所示,并行PS-Attention在所有任务上都取得了最好的结果。作者将此归因于在普通的PS-Attention中,对于非方形输入大小的过多填充将导致轻微的性能下降。
为了直接比较PS-Attention与最相关的Axial-based Attention,分别用轴向自注意力和cross-shaped window self-attention替代了Pale-T的PS-Attention。如表8所示,PS-Attention明显优于这两种机制。
3、不同的位置嵌入

位置编码可以引入空间位置感知来实现自注意力的特征聚合,在Transformer中起着重要作用。本文比较了几种常用的位置编码方法,如无位置编码(no pos.)、绝对位置编码(APE)和条件位置编码(CPE)。如表9所示,CPE的性能最好。不使用任何位置编码将导致严重的性能下降,这证明了位置编码在Vision Transformer模型中的有效性。
4.2 ImageNet-1K分类
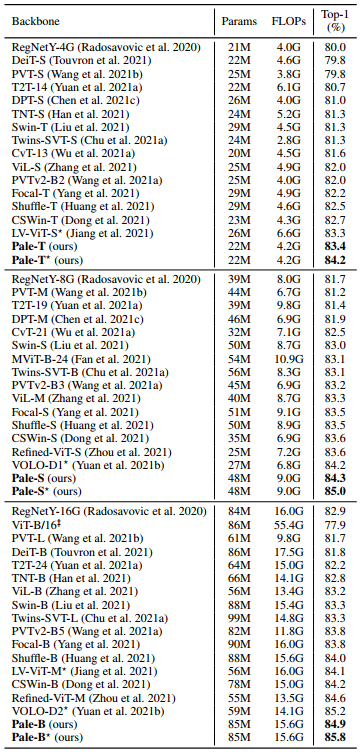
表2比较了Pale Transformer与最先进的CNN和Vision Transformer Backbone在ImageNet-1K验证集上的性能。在相同的计算复杂度下,与先进的CNN相比,Pale模型分别比RegNet模型好+3.4%、+2.6%和+2.0%。
与此同时,Pale Transformer的性能优于最先进的基于Transformer的Backbone,在类似型号尺寸和FLOPs下的所有变种中,其性能比最相关的CSWin Transformer高0.7%。
请注意,LV-ViT和VOLO,使用额外的MixToken增强和token丢失进行训练,似乎与本文方法相同。为了进行比较,在Pale模型上使用了这两种技巧,与lv-vi-s相比,Pale-T获得了+0.9%的增益,且计算成本更低。Pale-S和Pale-B分别达到85.0%和85.8%,比VOLO高出0.8%和0.6%。
4.1 COCO目标检测

如表3所示,对于目标检测Pale-T、Pale-S和Pale-B的目标检测box mAP分别为47.4、48.4和49.2,超过了之前的最佳水平CSWin Transformer +0.7,+0.5,+0.6。
此外,Pale Transformer变体在实例分割上也有一致的改进,分别比之前的最佳Backbone提高了+0.5、+0.5、+0.3 mask mAP。
5参考
[1].Pale Transformer:A General Vision Transformer Backbone with Pale-Shaped Attention
6推荐阅读

激活函数 | Squareplus性能比肩Softplus激活函数速度快6倍(附Pytorch实现)

YOLO-Z | 记录修改YOLOv5以适应小目标检测的实验过程

LVT | ViT轻量化的曙光,完美超越MobileNet和ResNet系列
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
