
基于激光雷达的高效语义SLAM
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
推荐阅读

本文来源:智驾最前沿,编辑:智车科技
/ 导读 /
可靠、准确的定位和建图是大多数自动驾驶系统的关键组件.除了关于环境的几何信息之外,语义对于实现智能导航行为也起着重要的作用.在大多数现实环境中,由于移动对象引起的动态变化,这一任务特别复杂,这可能会破坏定位.我们提出一种新的基于语义信息的激光雷达SLAM系统来更好地解决真实环境中的定位与建图问题.通过集成语义信息来促进建图过程,从而利用三维激光距离扫描.语义信息由全卷积神经网络有效提取,并呈现在激光测距数据的球面投影上.这种计算的语义分割导致整个扫描的点状标记,允许我们用标记的表面构建语义丰富的地图.这种语义图使我们能够可靠地过滤移动对象,但也通过语义约束改善投影扫描匹配.我们对极少数静态结构和大量移动车辆的KITTI数据集进行的具有挑战性的公路序列的实验评估表明,与纯几何的、最先进的方法相比,我们的语义SLAM方法具有优势.
对大多数自动驾驶车辆来说,精确定位和对未知环境的可靠测绘是基础.此类系统通常在高度动态的环境中运行,这使得生成一致的地图更加困难.此外需要关于建图区域的语义信息来实现智能导航行为.例如自动驾驶汽车必须能够可靠地找到合法停车的位置,或者在乘客可能安全离开的地方靠边停车——即使是在从来没有看到过的地方,因此以前没有准确地图.
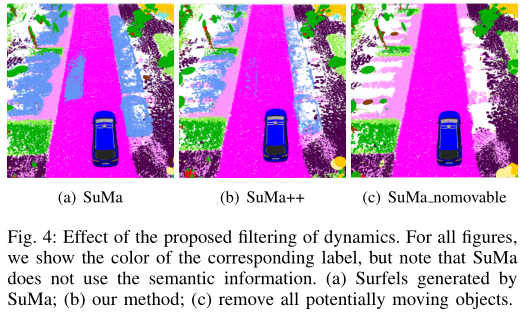
本文的主要贡献是将语义集成到基于表面的地图表示中的方法,以及利用这些语义标签过滤动态对象的方法。总之,我们声称我们能够准确地绘制环境地图,尤其是在有大量移动对象的情况下,并且我们能够实现比相同的建图系统更好的性能,简单地移除一般环境中可能移动的对象,包括城市、农村和高速公路场景.我们在KITTI的挑战序列上实验性地评估了我们的方法,并显示了与纯粹基于几何表面的建图和基于类标签移除所有潜在移动对象的建图相比,我们的语义表面建图方法SuMa++的优越性能.
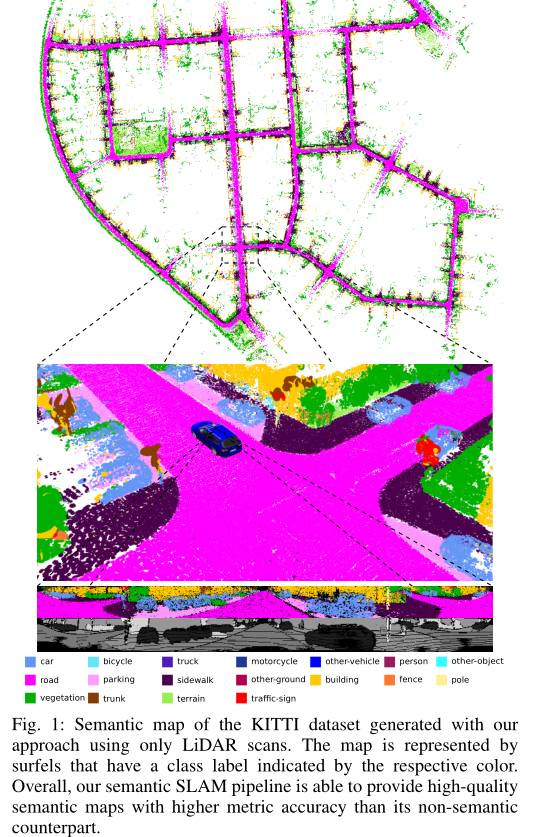

实验评估
我们使用来自KITTI的数据评估我们的方法,其中我们使用由Velodyne HDL-64E S2以10Hz的速率记录生成的提供的点云.为了评估里程计的性能,数据集建议计算在不同位姿之间的不同距离上平均的平移和旋转的相对误差,并对其进行平均.地面真实位姿是使用来自惯性导航系统的姿态信息生成的.
在下文中,我们将我们提出的方法(由SuMa++表示)与原始的基于surfel的建图(由SuMa表示)进行比较,并将SuMa与删除语义分割(由SuMa nomovable表示)给出的所有可移动类(汽车、公共汽车、卡车、自行车、摩托车、其他车辆、人、骑自行车的人、摩托车手)的简单方法进行比较.
语义分割的RangeNet++是使用逐点注释[1]使用KITTI里程计基准的所有训练序列进行训练的,这些标记可用于训练目的。这包括序列00至10,但序列08除外,该序列未进行验证。
RangeNet++平均需要75毫秒来为每次扫描生成逐点标签,surfer-mapping平均需要48毫秒,但在某些情况下,我们最多需要190毫秒来集成循环闭包(在具有多个闭环的训练集序列00上).
1、KITTI Road Sequences
第一个实验旨在展示我们的方法能够生成一致的地图,即使在有许多移动对象的情况下.我们显示了KITTI的原始数据道路类别的序列结果.请注意,这些序列不是里程计基准的一部分,因此没有提供标签对于语义分割,这意味着我们的网络学会了推断道路驾驶场景的语义类别,而不是简单的记忆.这些序列,尤其是高速公路序列,对SLAM方法来说是具有挑战性的,因为这里大多数物体都是移动的汽车.此外路边只有稀疏的明显特征,如交通标志或电线杆.建筑角或其他更有特色的特征不可用于指导注册过程.在这种情况下,在不断移动的异常值上的错误对应(如交通堵塞中的汽车)通常会导致错误估计的姿态变化,因此生成的地图不一致.
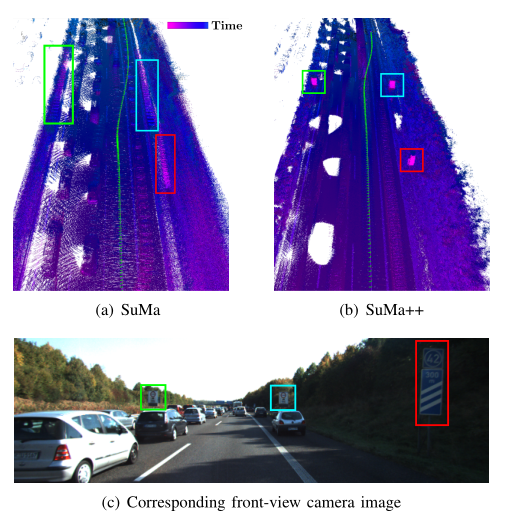
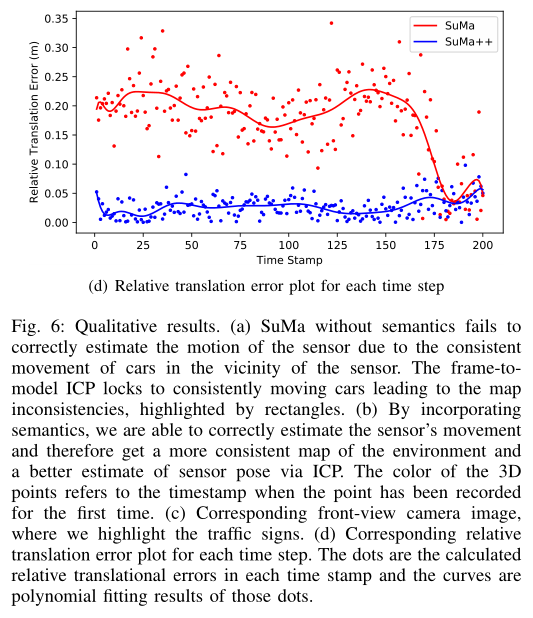
图6显示了用SuMa和提出的SuMa++生成的示例.在纯几何方法的情况下,我们清楚地看到姿态无法正确估计,因为突出显示的交通标志出现在不同的位置,导致很大的不一致.在我们提出的方法中,我们能够正确地过滤移动的汽车,相反,我们生成一致的地图,如突出显示的交通标志.在这个例子中,我们还绘制了SuMa和SuMa++的里程计结果的相对平移误差.圆点代表每个时间戳中的相对平移误差,曲线是给定圆点的多项式拟合结果.它表明SuMa++在这样一个具有挑战性的环境中实现了更准确的姿态估计,其中许多异常值是由移动对象引起的.
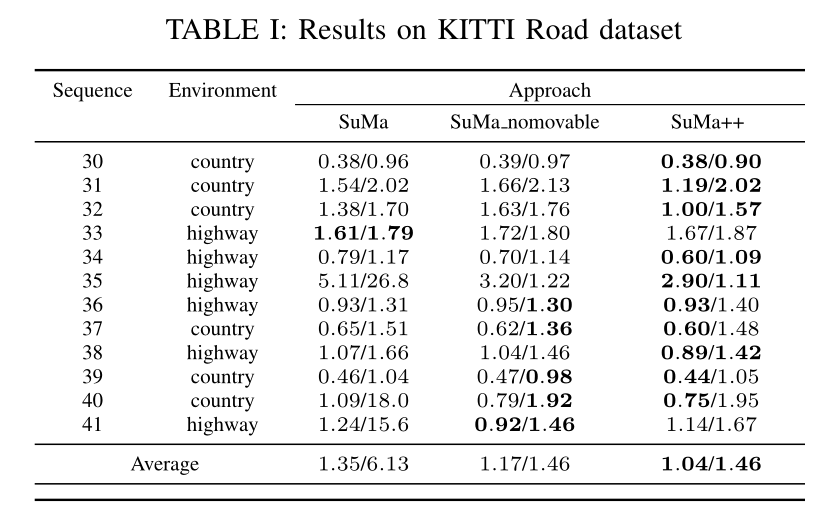
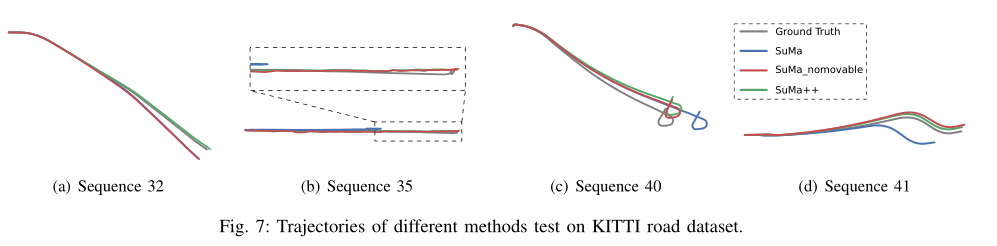
表1显示了相对平移和相对旋转误差,图7显示了在数据集的这一部分测试的不同方法的相应轨迹.一般来说,我们看到我们提出的方法SuMa++生成了更一致的轨迹,并且在大多数情况下实现了比SuMa更低的平移误差.与仅仅移除所有可能移动的对象的基线相比,SuMa是不可移动的,与SuMa++相比,我们看到非常相似的性能.这证实了SuMa在这种情况下性能更差的主要原因是由实际移动的对象引起的不一致.然而我们将在接下来的实验中表明,移除所有潜在的移动对象也会对城市环境中的姿态估计性能产生负面影响.
2、KITTI Odometry Benchmark
第二个实验旨在表明,与简单地从观察中移除某些语义类相比,我们的方法表现更好。该评估在KITTI里程计基准上进行
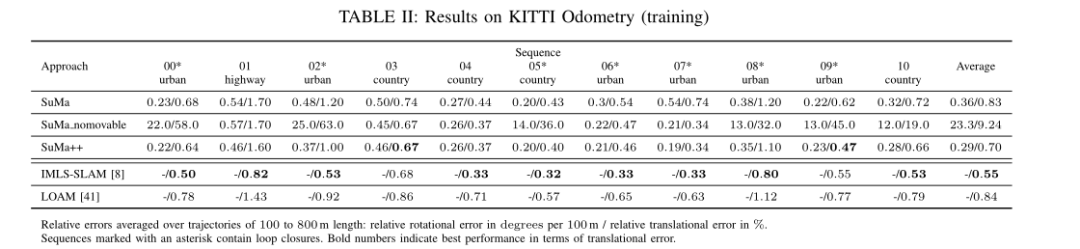
表2表示相对平移和相对旋转误差。IMLS-SLAM和Loam是基于激光雷达的最先进的SLAM方法。在大多数序列中,我们可以看到SuMa++的性能与最先进的。更有趣的是,基线方法有不可解决的分歧,尤其是在城市场景中.
这可能是反直觉的,因为这些环境包含大量的人造结构和其他更有特色的特征。但是,有两个原因导致了这种糟糕的性能,当人们查看结果和发生映射错误的场景的配置时,就会明白这一点。首先,即使我们试图改善语义分割的结果,也有错误的预测导致地图中实际上是静态的表面元素被移除。第二,移除停放的汽车是个问题,因为这些是对齐扫描的好的和独特的特征。这两种效果都有助于使表面贴图更稀疏。这一点更为关键,因为停放的汽车是唯一与众不同或可靠的特征。总之,简单地删除某些类至少在我们的情况下是次优的,并且会导致更差的性能.
为了评估我们的方法在未知轨迹上的性能,我们上传了未知KITTI测试序列的服务器端评估结果,因此测试集上的参数调整是不可能的。因此,这可以很好地代表我们方法的实际性能。在测试组中,我们获得了0.0032度/米的平均旋转误差和1.06%的平均平移误差,与原始SuMa的0.0032度/米和1.39%相比,这是平移误差方面的改进.


结论
在本文中,我们提出了一种新的方法来建立语义地图,使基于激光的语义分割点云不需要任何相机数据. 我们利用这一信息来提高姿态估计的准确性,特别是我们的方法利用扫描和地图之间的语义一致性来过滤掉动态对象,并在比较方案过程中提供更高级别的约束.这使得我们能够仅基于三维激光距离扫描成功地组合语义和几何信息,以实现比纯几何方法更好的姿态估计精度.我们在KITTI Vision基准数据集上评估了我们的方法,显示了我们的方法与纯几何方法相比的优势。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~