
论文翻译 | Mask-SLAM:基于语义分割掩模的鲁棒特征单目SLAM
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文提出了一种将单目视觉SLAM与基于深度学习的语义分割相结合的新方法.为了稳定运行,vSLAM需要静态对象上的特征点.在传统的vSLAM中,随机样本一致性(RANSAC) 用于选择那些特征点.然而,如果视图的主要部分被移动的对象占据,许多特征点变得不合适,并且RANSAC不能很好地执行.根据我们的经验研究,天空和汽车上的特征点通常会导致vSLAM中的错误.我们提出了一个新的框架,使用语义分割产生的掩码来排除特征点.排除掩蔽区域中的特征点使vSLAM能够稳定地估计摄像机运动.我们在框架中应用ORBSLAM ,这是单目vSLAM的最新实现.在我们的实验中,我们使用CARLA simulator [3],在各种条件下创建了vSLAM评估数据集.与最先进的方法相比,我们的方法可以获得明显更高的精度.
为了使机器能够识别真实世界,摄像机姿态估计是一项关键的任务,它可以准确地估计机器在真实世界中的位置.视觉同时定位和建图(vSLAM)是最有前途的定位方法之一.它很简单,只需要一台摄像机来捕捉图像序列.利用一系列图像,VSLAM不仅能够估计摄像机的位置和姿态,还能重建三维场景.与激光雷达等其他传感器相比,成本要低得多,并且可以获得更多关于周围环境的数据.然而,vSLAM并不是特别鲁棒.
在本文中,我们将重点放在基于特征的vSLAM上,使用ORB-SLAM在单目vSLAM实现运行相对稳定.基于特征的vSLAM首先从图像中提取许多特征点,然后比较序列中图像之间每个点的描述符以搜索对应关系,最后根据这些对应关系估计摄像机姿态.基于特征的方法可以抵抗图像失真,并且可以为多种设备执行高精度的姿态估计.然而,这些方法仅利用作为特征点提取的局部信息,并且不能区分世界坐标系中静止区域的特征点.如果特征点位于移动区域,vSLAM会产生估计误差.为了从静态区域中选择特征点,随机样本一致性(RANSAC) [5]通常用于基于特征的vSLAM.
RANSAC用于从许多假设中选择最可靠的值.假设是从大量对应对的随机样本中计算出来的.vSLAM应排除移动区域中的特征点,这些特征点可能不正确,并可能导致错误.然而考虑一个大多数对应对不正确的情况.RANSAC无法专门选择正确的点对,vSLAM无法正确解决问题.为了处理这些不适合RANSAC的情况,我们使用了通过基于深度神经网络的语义分割获得的掩码语义分割考虑了图像中的全局信息,是对基于特征的vSLAM的补充,后者仅利用图像中的局部信息.
该方法不仅考虑了图像的局部特征,还考虑了图像的全局特征,有利于灵活且高精度的图像识别.仅使用图像中的基于特征的vSLAM的环境局部信息的,这强烈依赖于环境.然而,使用语义分割这一深度学习中最活跃的研究课题之一,可以弥补基于特征的vSLAM中的不足.这是通过使用语义分割产生的掩码来移除不适当区域中的特征点来实现的.mask确保假设不会集中在不适当的区域,例如移动的对象.
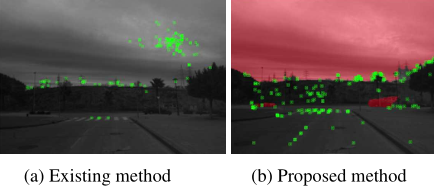
图1:现有方法和建议方法在特征点提取方面的差异.通过掩蔽特征点的区域,特征点在图像中变得均匀分布,而不集中在不适合vSLAM的区域.
在我们的实验中,我们主要关注从移动的车辆上拍摄的视频.在我们的初步实验中,特征点不正确的区域通常包括行人、车辆和天空.在最著名的基准数据集KITTI中,条件过于优化,不合适的区域非常少.在现实世界中,天气、移动物体(汽车)、行人等都有极端的多样性.因此,我们决定使用CARLA simulator[3]生成的模拟环境来评估我们.有了CARLA模拟器,人们可以自由移动汽车和改变天气,并且可以根据需要创建尽可能多的数据.我们使用在尽可能接近真实世界的模拟环境中获得的大量数据集来评估所提出的方法的有效性.
本文的主要贡献如下:
我们提出了一种通过引入基于深度学习的语义分割来提高单目vSLAM性能的方法.vSLAM局部信息的不足可以通过引入语义分割的全局信息来解决 所提出的方法获得的性能几乎与传统vSLAM理想运行时获得的性能相同 我们利用驾驶模拟器来产生许多现有数据集中没有的环境.基于模拟视频的实验表明,该方法的性能明显优于现有方法
已经有一些尝试来解决将深度学习与虚拟空间学习相结合的问题,或者利用深度学习来实现传统空间学习的功能.最著名的方法之一是CNN-SLAM,它使用深度学习推断的深度值作为SLAM估计的初始解.最近,已经提出了无监督的方法来估计深度[6]和自我运动[19],并执行3D重建[18].这些方法只能从无标签(原始)movie中学习,与现有的vSLAM方法相比,它们的准确性很差.我们认为这些方法的一部分可以帮助改进现有的vSLAM方法.特别是[19]的作者介绍了一种“可解释mask”,这是一种不适合主流运动估计技术的图像区域mask.然而,他们的方法无法排除占据视图的移动对象区域,因为他们的训练数据不包含这样的图像.有必要初步了解图像中的哪些部分倾向于移动,哪些部分是静止的.
在我们的系统中,我们使用语义分割来改进vSLAM.语义分割是一种将图像分成语义类别区域的方法,如人、车、天空等.将vSLAM和语义分割相结合是合理的,因为前者依赖于局部信息,而后者产生局部信息队形.这两种类型的信息是互补的,它们的适当组合可以提高vSLAM的准确性.
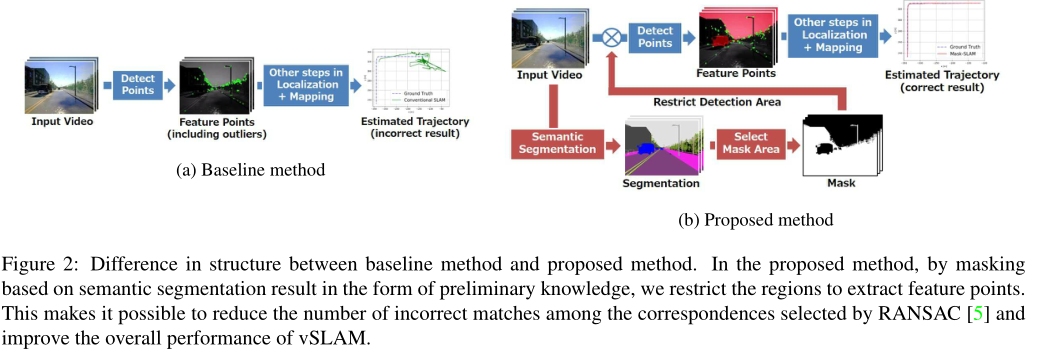
Mask-SLAM本节描述了Mask-SLAM方法.我们的模型包括使用语义分割从图像中构建一个掩码,并将该信息合并到现有的vSLAM系统中.如图2所示.
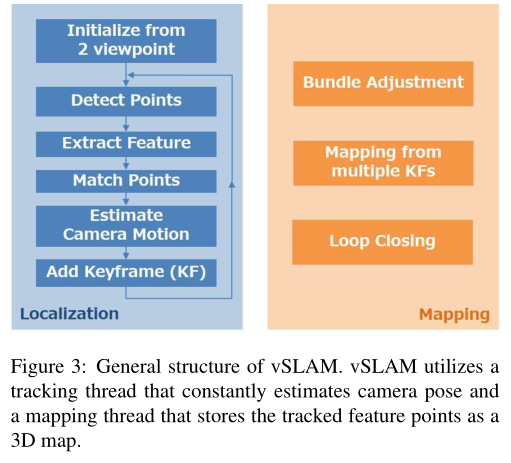
基于特征的vSLAM通常包括“定位,即跟踪相机姿态估计”和“建图以重建周围的3D环境”,这两个过程同时执行.图3给出了详细的算法.vSLAM从图像中提取特征点,通过比较每个点的描述符获得对应的对,并根据对应关系估计摄像机运动.ORB-SLAM是vSLAM的最先进的实现,它使用可以高速提取的ORB特征点,并比较这些ORB特征以获得对应点.ORB-SLAM利用获取大量对应对并从中选择可靠对的策略.RANSAC 是用于选择最可靠对应关系的算法.
RANSAC算法的操作如下:
从数据中随机抽取足够数量的样本 估计一组参数来拟合这些样本,这组参数称为假设. 将获得的假设应用于除提取样本之外的所有数据,并计算每个数据样本的估计参数之间的距离 将距离较小的样本视为内联样本,让内联样本的数量代表一个假设的正确性 以上操作执行多次,采用内联数最大的假设,剔除离群数据
通过实现上述方法,可以获得不受异常值影响的正确估计结果.一般来说,在vSLAM中,RANSAC可以从大量对应关系中找到最正确的一对,并可以推导出准确的相机姿态.然而,这种方法的用处是有限的.vSLAM需要静止物体的特征,以便RANSAC能够选择可靠的对应关系.当整个视图被移动的物体占据时,RANSAC不能选择可靠的对应关系.在vSLAM中,对输入视频的每一帧执行RANSAC,以估计摄像机姿态.如果一个不适合估计相机姿态的区域出现了很长一段时间,那么连续检测不适合的对应点作为内联点的概率就会大大增加.这种情况经常发生在使用SLAM out-doors时.
因此,我们提出使用语义分割来弥补RANSAC的不足.语义分割用于产生一个掩码,以排除不可能找到正确对应的区域.具体而言,在一般的vSLAM系统中,在检测特征点的阶段,添加了“不检测掩蔽区域中的特征点”的操作.通过简单地增加这个操作,可以排除大部分获得的不准确的对应关系,这显著地减少了RANSAC误差.
语义分割是给每个像素分配一个对象类的问题.VOC2012和MSCOCO是语义分割的代表性数据集.我们定义要屏蔽的对象如下:
汽车:不适合特征点的运动物体 天空:这个物体离相机视图太远.这意味着很难估计这个物体的精确3D位置
掩模中排除了应该从图像中检测特征点的区域.在这项研究中,我们使用了DeepLab v2 ,它可以执行高精度的语义分割. DeepLab v2利用具有以下结构的网络:
对于输入图像,深度卷积神经网络输出对象存在概率heat map.
对概率heat map.进行双线性插值
最终的区域分割结果基于使用条件随机场的边界细化而输出[11].
DeepLab v2实现了一个atrous卷积,可以降低计算成本,在不降低分辨率的情况下进行卷积运算.通过在卷积滤波器像素之间的间隙中插入零并放大它,输出结果保持高分辨率.此外为了获得关于图像中各种大小的对象的信息,可以通过组合空间金字塔汇集来提高性能,该空间金字塔汇集在多个尺度上并行执行卷积,具有atrous卷积(atrous空间金字塔汇集(ASPP)).在Deeplab v2中,通过将ASPP合并到现有网络(VGGNet或ResNet)中,创建者能够导出高度准确的概率heat map
在我们的实验中,我们使用CARLA驾驶模拟器CARLA [3]创建的30000幅图像(800 × 600像素)从头开始训练了一个基于ResNet-101的DeepLab v2.我们使用了一个特斯拉K80 GPU来训练网络.我们基于前文的实验设置构建了训练数据.
数据集由从移动的汽车捕获的图像和语义分割基本事实结果(13种标签).语义分段GT数据最初有12种类型的标签(无、建筑物、栅栏、其他、行人、电线杆、道路、人行道、车辆、墙壁和交通灯),但我们添加了“天空”标签.
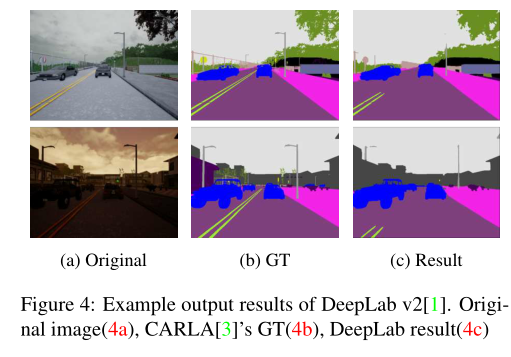
我们创建了“天空”标签,如下所示.对于深度值最深(1000[m])的语义分割GT中标记为“无”的像素,我们将“无”的标签更改为“天空”.图4显示了DeepLab v2的结果
“汽车”(移动物体)和“天空”(远处区域)是我们凭经验发现会干扰vSLAM运行的物体.我们输出这两个标签区域作为mask,并实现了一个过程,在这个过程中,不会从这些被遮罩的区域检测到特征点.
为了证明所提出方法的有效性,我们使用了CARLA驾驶模拟器[3],它可以模拟各种环境.现有的基准,如KITTI,只考虑RANSAC不太可能失败的有限情况.然而由于现实世界中出现了各种各样的环境,仅使用KITTI基准来评估模型是不够的.在本实验中,我们使用CARLA模拟了各种天气条件和移动物体环境,以确定所提出的方法在各种条件下是否有效.CARLA可以灵活地改变天气条件,并可以自动移动汽车.
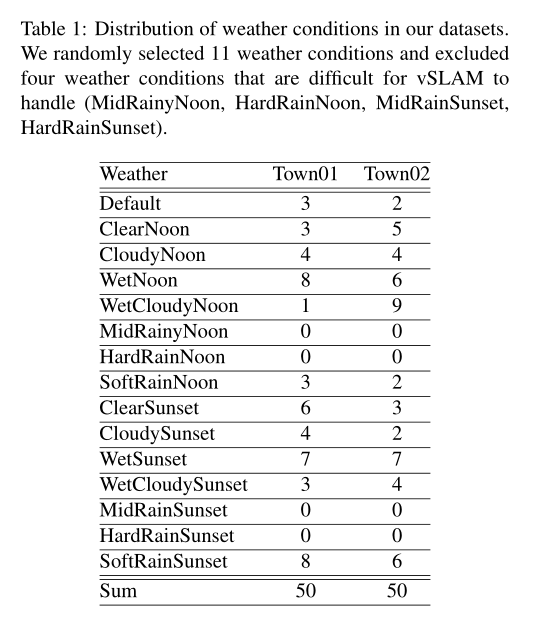
CARLA是由Desovitskiy等人开发的用于自动操作的驾驶模拟器.我们从两个城镇(Town01,Town02)在15种天气条件下移动的汽车上获取图像(CloudySunset、SoftRain、Clearnoon等).
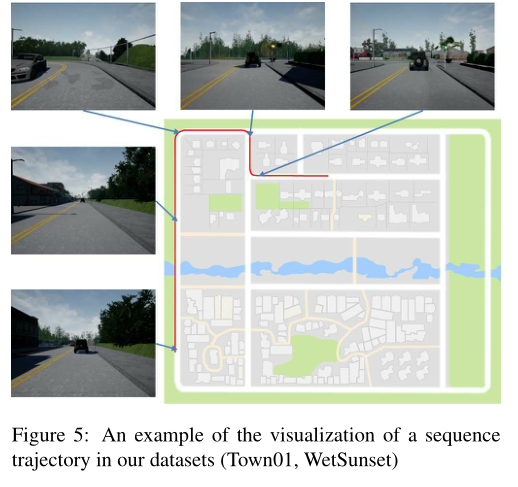
此外我们获取了全球定位系统、激光雷达、语义和分割等传感器数据,这些数据在现实世界中是不可用的.在这个实验中,我们从两个城镇的50次运行中创建了数据集(总共100次运行)。每次运行包含1000幅图像(800 × 600像素),以15帧/秒的速度拍摄.我们将运行中获得的图像(视频)称为序列.汽车使用自动驾驶模式自动驾驶,每次行驶距离为100-500米.我们还从11个选项中随机选择了天气条件.我们排除了ORBSLAM 无法运行的四种天气条件.表1列出了数据分布.此外,序列轨迹可视化的例子在图5中给出.
在这一部分,我们描述我们的评估指标.我们对每种基线方法[15]和我们的每种序列方法估计了50次轨迹.我们定义了两个评估指标来计算每个指标的平均值数据类型.
“序列”的评估值被定义为“通过重复推导一个序列的50个轨迹的估计值而获得的平均值” “整个序列”的评估值定义为“每个序列的评估值的平均值”
在这个实验中,我们关注的是vSLAM的整体改进.我们将改进定义为当原始vSLAM失去位置并停止运行时,我们的vSLAM运行没有问题.我们观察了几个案例,在这些案例中,由于汽车或天空造成的错误,原始的vSLAM在完成之前就停止了.
考虑到这些想法,我们使用了以下两种评估指标:
平均跟踪速率(MTR):该指标指示vSLAM是否在每个序列的基础上跟踪而不丢失其位置或停止操作.如果跟踪成功,vSLAM输出估计值每帧中摄像机运动的结果.我们将“失败跟踪”定义为在一个序列的1000个帧中,超过80 [%]的帧未能获得估计结果.我们将单个序列超过50次试验的成功率输出为“跟踪率[%]”相反,我们将“成功跟踪”定义为在1000帧中成功跟踪超过80 [%]的帧.如果观察到评估值有所改善,则表明vSLAM的性能有所改善.具体来说,我们为所有试验制定了“平均跟踪率[%]”

平均轨迹误差(MTE):一般变速直线加速器的目标是“估计接近GT的摄像机的轨迹”作为接近度的评估,我们将每个时间步长的距离误差和序列的平均值输出为“轨迹误差[m]”.因为我们在实现中使用了单目vSLAM,所以我们根据Horn的方法计算了将比例调整到GT后的误差[9].但是需要注意的是,我们计算的误差只针对“成功追踪”(“追踪率”超过80 [%]).这是因为如果“跟踪率”低,可以在根据霍恩的方法调整比例时将误差设置为零.但是这不是一个恰当的评价.我们为所有试验制定了“平均轨迹误差(MTE) [m]”,顺序如下:

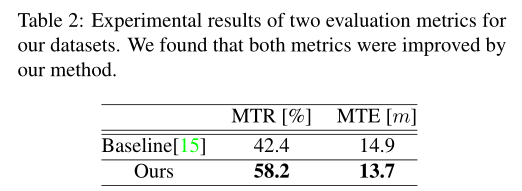
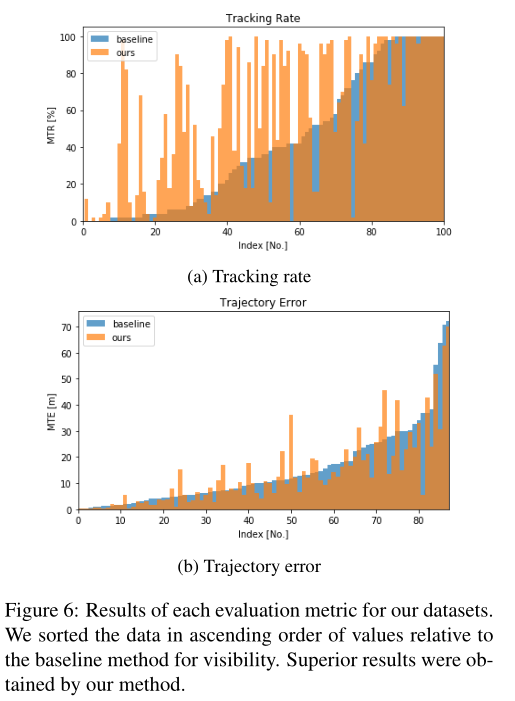
表2列出了所有数据集的评估结果(“平均跟踪率”和“平均轨迹误差”).可以看到,当使用我们的方法时,在这两个指标上都观察到了改进.
此外,为了详细显示结果,我们在图6中说明了每个序列的结果.我们确定,当“跟踪速率”值增加或“轨迹误差”值减少时,vSLAM的性能有所提高.从图6中可以看出,当使用所提出的方法时,我们发现对于所有序列,两种评估度量都有所改进.“平均轨迹误差(MTE)”的改善程度在表2中可能显得很小.然而如前文所述,我们仅使用来自“成功跟踪”试验(其“跟踪率”为80[%]或更高)的数据来计算“平均轨迹误差(MTE)”由于基线“跟踪率”较低,我们使用少量数据样本(试验)计算了“轨迹误差”.相比之下,因为我们的方法的“跟踪率”很高,所以我们使用大量的试验来计算我们的方法的“轨迹误差”.基线和我们的方法之间的误差差异很小,因为试验是阈值化的,并且只考虑成功的试验.
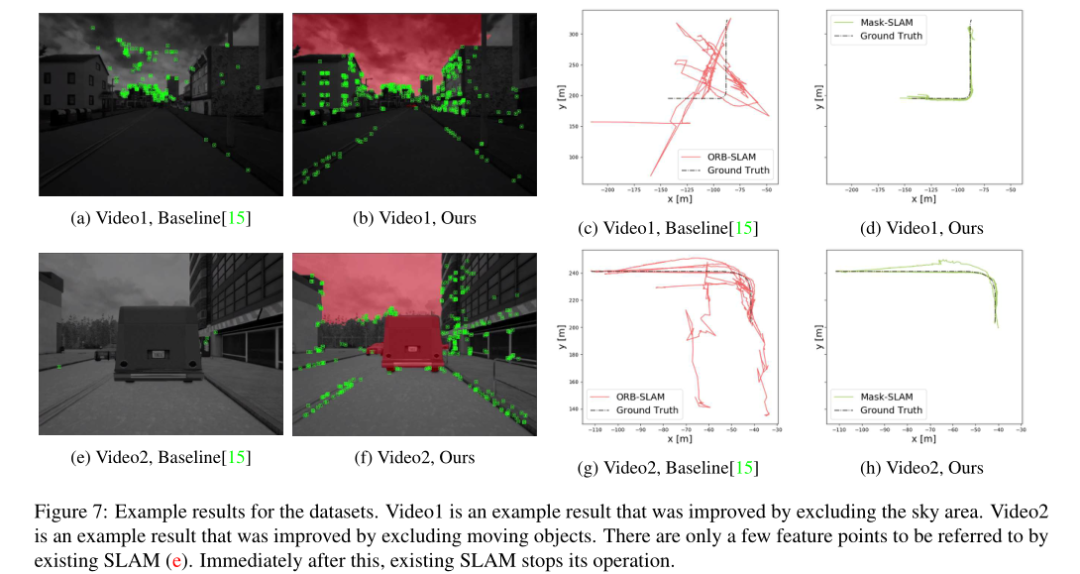
另外我们关注100个序列中的两个结果,包括-ing数据集.结果如图7和表3所示.图7展示出了通过每种方法对一帧的特征提取以及每个序列的估计轨迹
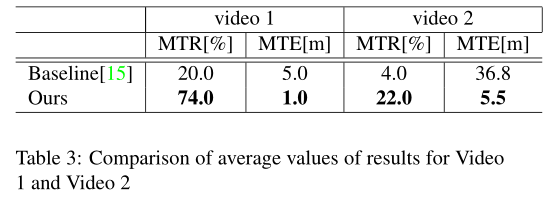
结果表明,与基线方法相比,我们的方法提高了结果.关于视频1,通过使用掩模限制特征点检测区域来抑制天空区域上的集中.结果,从整个视图中提取特征点,并且估计结果变得稳定.关于视频2,基线vSLAM停止并失去了它的位置,因为汽车覆盖了整个视图.然而在所提出的方法中,通过使用掩模成功地排除了在汽车区域中特征点的检测,在不停止我们的方法的操作的情况下,特征点的跟踪成功.当比较每个视频中轨迹的结果时,基线方法输出偏离GT的轨迹,但是所提出的方法输出与GT重叠的相对精确的轨迹.结果,“跟踪率”和“轨迹误差”都得到了改善.
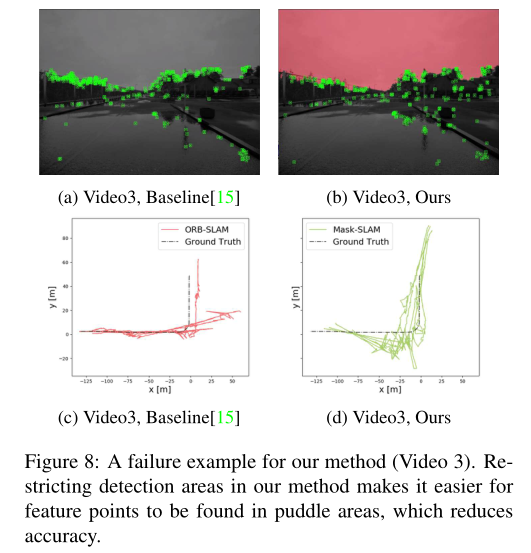


当使用所有数据时,所提出的方法并不总是产生好的结果.视频3就是一个失败的例子.这在图8和表4中清楚地显示出来.视频3中的天气是潮湿的多云的日落,路上有水坑.跟踪反映在水坑表面上的建筑物轮廓的特征点导致vSLAM的估计精度下降.在我们的方法中,通过使用遮罩排除汽车和天空,与基线方法相比,特征点更有可能在水坑区域被检测到.结果是“跟踪速率”和“轨迹误差”都降低了.
提出了一种新的基于特征的向量空间模型和语义分割相结合的方法.语义分割输出了将对象分类到图像中的语义区域的结果,我们从不适合vSLAM的语义区域生成了一个掩码.我们的vSLAM方法只从掩模排除的区域提取特征点,并且只能选择可靠的特征点.这使得vSLAM能够准确稳定地工作,而不会丢失其位置。