
拿下Xilinx后,AMD推零暗硅AI新品,叫板英伟达

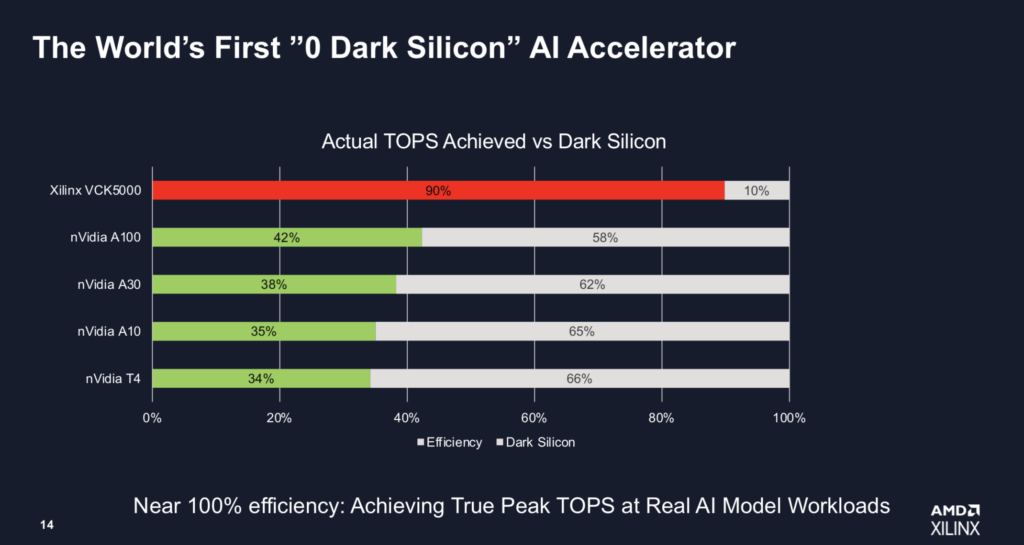
AMD/Xilinx 发布了其 VCK5000 AI 推理卡的改进版本以及一系列直接针对 Nvidia 的 GPU 产品线的竞争性基准测试。AMD 表示,新的 VCK5000 的性能是早期版本的 3 倍,并且 TCO 是 NvidiaT4 的 2 倍。AMD 还展示了针对几款 Nvidia GPU 的良好基准,声称其 VCK5000 在“真正的 AI 模型工作负载”上实现了 90% 的真实峰值 TOPS,作为对比,Nvidia 的 A100、A30、A10 和 T4 的表现介乎 34% 到 42%之间。
下载链接:
AMD Zen3处理器架构详解
采取如此强硬的立场,强调对 Nvidia 产品的 TCO ,这有点让人想起 AMD 在2017 年对英特尔的战略,当时 AMD在数据中心长期缺席后推出了 Epyc CPU 产品线。当然,AMD刚刚完成了对 Xilinx的收购,早在 2020 年他们就宣布了这笔交易。VCK5000 现在的售价为 2745 美元,AMD 称这是一个非常有竞争力的价格,尤其是考虑到“当前的供应链问题”。

“VCK5000 是第一款采用我们 7nm Versal ACAP 芯片的 PCIe 卡。它针对 AI 推理进行了优化,这是我们第一次将 AI 引擎内核中的一些东西放入 FPGA,”AMD 新的自适应和嵌入式计算事业部的 AI 和软件解决方案产品营销总监 Nick Ni 说。“这张卡实际上并不新,但改变的是我们在 AI 推理上的性能提高了近 3 倍。我们还声称我们是世界上第一个用于人工智能推理的零暗硅——我们是唯一实现接近 100% 数据表峰值的公司,这是其他人无法接近的。”
VCK5000 AI 推理卡包括 FPGA 和Arm CPU 元件(见上图),于去年 5 月推出。它是AMD Versal 自适应计算加速平台 (ACAP) 的一部分。AMD 表示,整体设计解决了它所谓的“暗硅”问题——基本上是空闲的处理元件等待来自内存的数据。
HyperionResearch的分析师史蒂夫·康威(Steve Conway)提出了谨慎的看法。“英伟达几乎单枪匹马地创造了 GPGPU 市场并在今天占据主导地位,但任何大市场都会吸引竞争对手,竞争是好事。现在知道新的 AMD/Xilinx 推理卡的竞争力还为时过早,但对推理给予更多关注是件好事。更有能力的推理为人工智能增加了智能,并应减少给定任务的训练负担,”康威说。
HPC 社区可能更熟悉 Xilinx-Alveo U55C,这是该公司在 SC21推出并宣传为其最强大的基于 FGPA 的加速器卡。当被要求区分这两张卡时,AMD 提供了以下内容:
“Alveo U55C 属于 AMD-Xilinx 生产加速卡产品组合,专门针对 HPC 和大数据工作负载。它基于 Virtex UltraScale+ FPGA,与 VCK5000 相比具有不同的外形尺寸。借助基于 Xilinx RoCE v2 的集群解决方案,我们使具有大规模计算工作负载的广泛客户能够使用他们现有的数据中心基础设施和网络实施基于 FPGA 的强大 HPC 集群。
“VCK5000 是一款基于公司 7nm Versal 产品组合的开发卡,针对需要高吞吐量 AI 推理和信号处理计算性能的设计进行了优化。VCK5000 是第一款实现接近零暗硅的 AI 芯片,使用标准基准模型,其性能功耗比比 Nvidia 的 A100 和 T4 GPU 等竞争设备高出 2 倍。”
广泛使用 FPGA 的一个长期绊脚石是其冗长而复杂的开发过程,需要在RTL级别进行编程。Alveo U55C 和 VCK5000 卡都试图通过利用 AMD/Xilinx Vitis 统一软件平台来应对这一挑战。
Ni 描述了对最新 VCK5000 进行编程以运行基准测试的努力:“因此,如果您进行自下而上的设计,即使用 RTL 的传统设计,与使用 GPU 相比,[开发] 肯定会花费更长的时间。但是我们[通过 Vitis] 使用软件抽象。我们在这里展示的所有结果都没有涉及任何 RTL 开发。一切都只是基于 TensorFlow、Pytorch。我们基本上将MLPerf提供的 TensorFlow 和 ResNet 50 模型带入了我们的编译器。你运行它,你会得到结果。这实际上与 GPU 的设计周期相同。”
Ni 表示 AMD/Xilinx 将在未来的MLPerf 推理练习中提交 VCK5000 的结果。
值得一提的是,基于 FPGA 的解决方案最近受到了关注。就在昨天,英特尔推出了基于Intel 7 工艺的 Agilex M 系列FPGA 。英特尔报告称,新的 FPGA 具有:“业界最高的 FPGA 内存带宽;在支持 HBM 的FPGA 中实现业界最高的 DSP 计算密度;与竞争的 7nmFPGA 相比,每瓦的结构性能超过 2 倍。” 英特尔于 2015 年通过收购 Altera 进入了 FPGA 市场。
对 FPGA 的兴趣重新抬头有很多原因,包括:AI 模型的规模快速增长;需要加速进出这些模型的数据移动;软件定义架构的持续发展以及对分散智能控制器的相关需求;并改进 FPGA 编程工具。倡导者认为,基于 FPGA 的解决方案提供了专业化、灵活性和性能的高性价比组合。这一直是承诺,但兑现承诺往往具有挑战性。
现在,FPGA——无论是单独使用还是与其他处理和内存组件配对并封装为 SoC——都引起了人们的关注。供应商越来越多地将它们描述为从数据中心到边缘的 AI 解决方案组合的一部分。
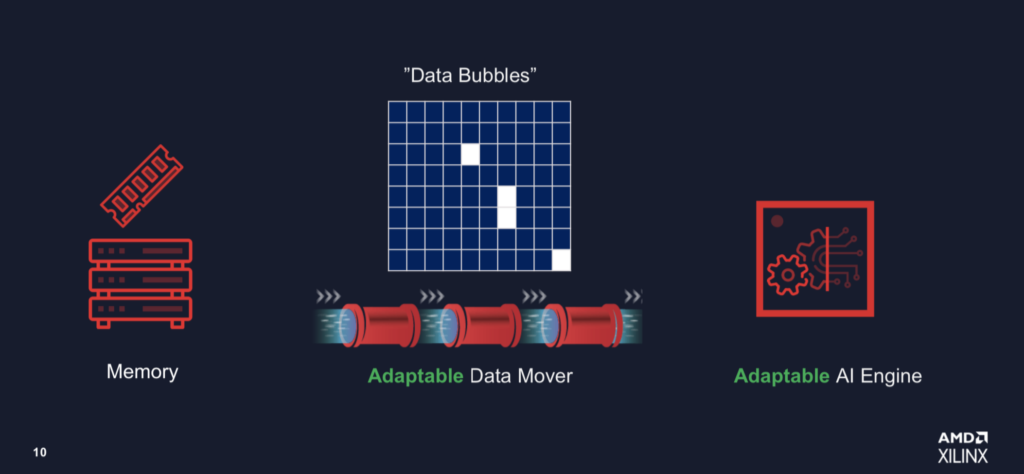
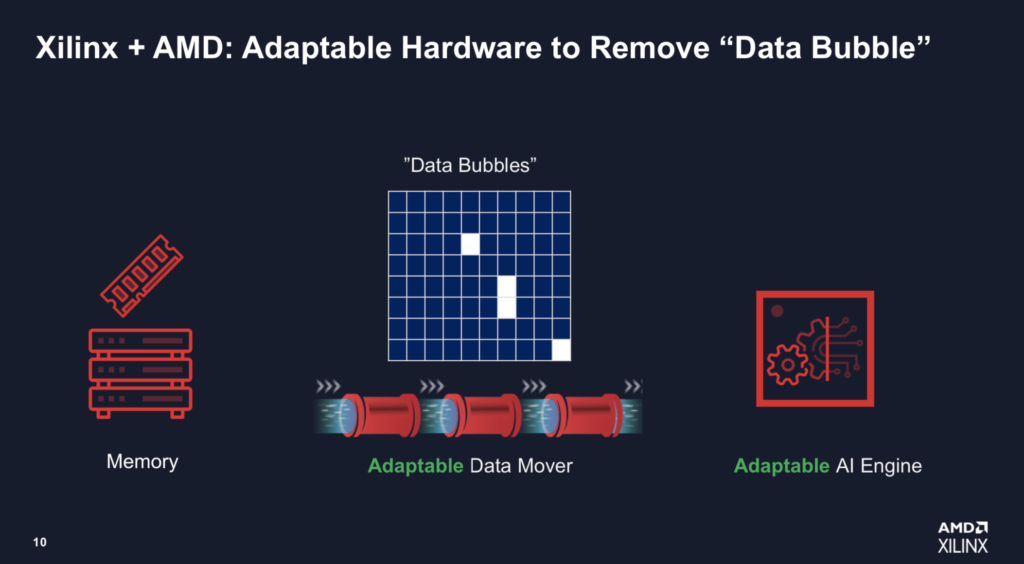
AMD 认为,与固定架构 GPU 不同,可以针对 AI 模型的特定需求,特别是数据流要求,设计更灵活的基于 FPGA 的系统。这一论点是 AMD“解决暗硅”问题的核心,它表示在某些工作流程中,英伟达 GPU 的峰值 TOPS 远低于50%。
“因为你有一个固定核心的 AI 处理器,而Nvidia 是用于 Tensor 核心 GPU 的,它是为某些模型设计的,它是固定的,而且必须将数据泵入引擎以获得 100% 的效率。[当]您运行当今较大的模型时,会发生什么情况是您创建了巨大的数据气泡(下面的幻灯片),因为您必须在共享缓存中有很多缓存未命中。例如,即使 Nvidia A30 引擎能够执行 330 TOPS,但他们说只有 40% 的时间是在 [获取] 数据。这就是我们需要获得自适应硅 [设备] 的地方,例如 FPGA。

“[Xilinx 方法] 的不同之处在于两点。一个是我们的引擎。它和 ASIC 一样好,但我们还内置了一点可编程性。在我们的VLIW内核中,您还可以执行不同类型的数据传递,[例如]您可以进行广播。但最重要的是我们正在将 FPGA 架构连接到该基本内核。我们是无缓存的,我们甚至在系统中都没有缓存,所以没有缓存未命中之类的东西。您可以创建一个完美的内部存储器 [流],以便您可以将每个时钟周期的数据泵入引擎。这就是你如何获得 100% 或接近 100% 的效率,[通过] 显着减少数据泡沫。”
Ni 在简报中强调了视频分析应用,AMD/Xilinx 确实有视频分析 SDK 和插件。但平台更灵活。
“我们称之为特定领域的架构。想想看,我们仔细设计了非常具体的领域,在这种情况下,人工智能推理是具体的,可以运行所有这些模型的 FPGA 编程。我们不想制造一招一式的小马,对吧?我们不想制作只能是 Resnet50的 IP,”Ni 说。他说,推理处理引擎可以有一个辅助“内部小型处理器”,可以根据编译指令针对不同的模型进行调整。
AMD 当然对其基于 FPGA 的平台产品组合寄予厚望。

在Xilinx交易完成时,AMD首席执行官 Lisa Su 表示:“对 Xilinx 的收购汇集了一系列高度互补的产品、客户和市场,并结合了差异化的 IP 和世界一流的人才,打造了业界高性能和自适应计算的领导者。Xilinx 提供行业领先的 FPGA、自适应 SOC、AI 引擎和软件专业知识,使AMD 能够提供业内最强大的高性能和自适应计算解决方案组合,并在我们看到的约 1350 亿美元的云市场机会中占据更大份额、边缘和智能设备。”
原文链接:
https://www.hpcwire.com/2022/03/08/amd-xilinx-takes-aim-at-nvidia-with-improved-vck5000-inferencing-card/
下载链接:
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
