
一文读懂 | coredump文件是如何生成的
共 8223字,需浏览 17分钟
·
2021-08-10 14:19
人都会犯错,所以在编写程序时难免会出现 BUG。
有些 BUG 是业务逻辑上的错误导致的,一般不会导致程序崩溃,例如:原本要将两个数相加,但不小心把这两个数相减,而导致结果出错。这时我们可以通过在程序中,使用 printf 这类输出函数来进行打点调试。
但有些 BUG 是由于某些致命的操作而导致的,一般会导致程序崩溃,例如:访问未经申请的内存地址。由于程序会异常退出,所以一般不能通过 printf 这类输出函数进行打点调试。
另外,对于必现的 BUG (就是不管什么条件都会发生),一般可以通过 GDB 设置断点进行调试。但对于偶现的 BUG,由于在某些特定的条件下才会发生,所以比较难直接通过 GDB 进行调试。
那么,这时可以通过 Linux 提供的 coredump 文件进行调试。
一、coredump 文件生成过程
在程序发生某些错误而导致进程异常退出时,Linux 内核会根据进程当时的内存信息,生成一个 coredump 文件。而 GDB 可以通过这个 coredump 文件重现当时导致进程异常退出的场景,并且可以通过 GDB 来找到导致进程异常退出的原因。
当进程接收到某些 信号 而导致异常退出时,就会生成 coredump 文件。那么,哪些信号会导致生成 coredump 文件呢?
会导致生成 coredump 文件的信号,如下表所示:
| Signal | Action | Comment |
|---|---|---|
| SIGQUIT | Core | Quit from keyboard |
| SIGILL | Core | Illegal Instruction |
| SIGABRT | Core | Abort signal from abort |
| SIGSEGV | Core | Invalid memory reference |
| SIGTRAP | Core | Trace/breakpoint trap |
下面我们通过一个例子来说明怎么生成 coredump 文件。
从上面的表格可知,当进程接收到 SIGSEGV 信号时会生成 coredump 文件。SIGSEGV 信号是当进程访问错误(未经申请)内存地址时触发的,所以下面我们编写一个访问错误内存地址的程序:
int main(int argc, char *argv[])
{
char *addr = (char *)0; // 设置 addr 变量为内存地址 "0"
*addr = '\0'; // 向内存地址 "0" 写入数据
return 0;
}
在上面的例子中,由于内存地址 ”0“ 并没有通过调用 malloc 函数申请,所以当向地址 ”0“ 写入数据时将会导致 段错误,进程将会接收到 SIGSEGV 信号。
当进程接收到 SIGSEGV 信号后,内核将会根据进程当时的内存信息生成 coredump 文件,并且把进程杀死。
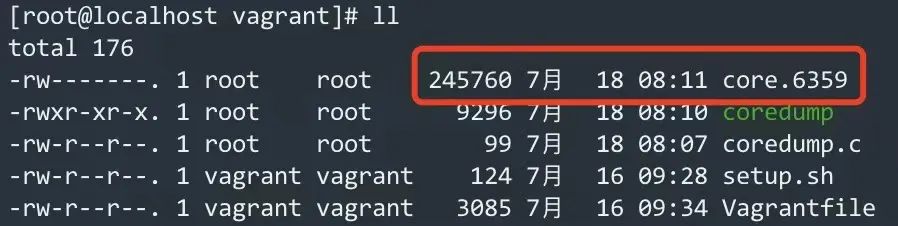
我们将上面的程序编译并且运行后,会发现程序异常退出,并且生成一个名为 core.xxx 的文件,这个文件就是 coredump 文件。如下图所示:
注意:
编译的时候记得加上 -g参数表示保留调试信息,否则使用 GDB 调试时会找不到函数名或者变量名。如果没有生成 coredump文件的话,一般是受到资源限制,先使用命令ulimit -c unlimited设置资源不受限制。
coredump 文件点后面的数字是进程的 PID。
现在我们只需要输入如下命令,即可使用 GDB 配合 coredump 文件来调试程序了:
$ gdb ./coredump ./core.6359
GDB 运行后会停止在发生异常的代码处,并且将发生异常的代码打印出来,如下图:
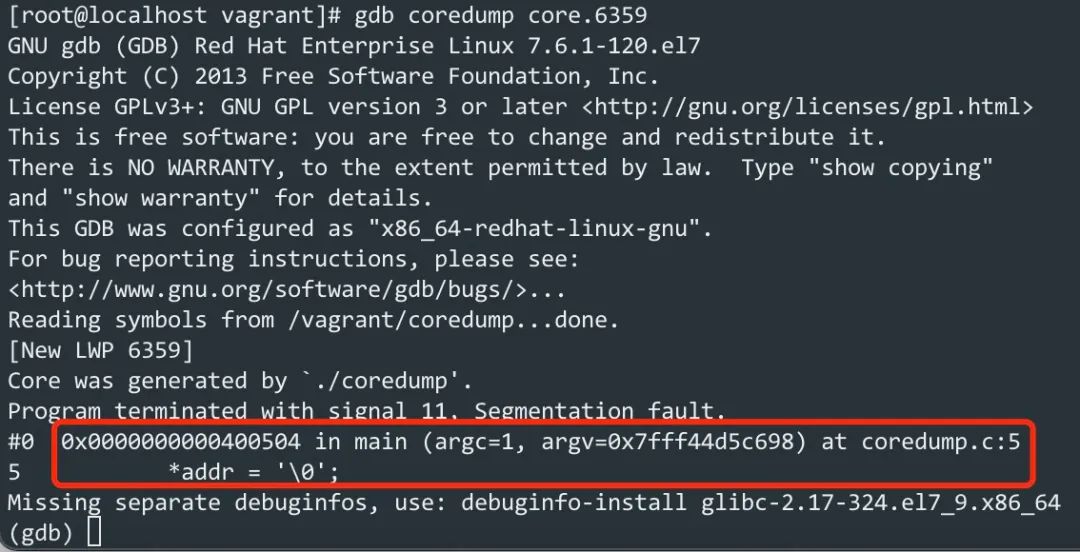
从上面的输出可以看到,GDB 除了会将发生异常的代码打印到终端外,还会将其所在的函数、文件名和所在文件的行数也打印出来,这样我们就很快能定位到哪行代码导致异常的。
二、coredump文件生成原理
前面介绍过,当进程接收到某些 信号 而导致异常退出时,就会生成 coredump 文件。
当进程从 内核态 返回到 用户态 前,内核会查看进程的信号队列中是否有信号没有处理,如果有就调用 do_signal 内核函数处理信号。我们可以通过下图来展示内核是怎么生成 coredump 文件的:
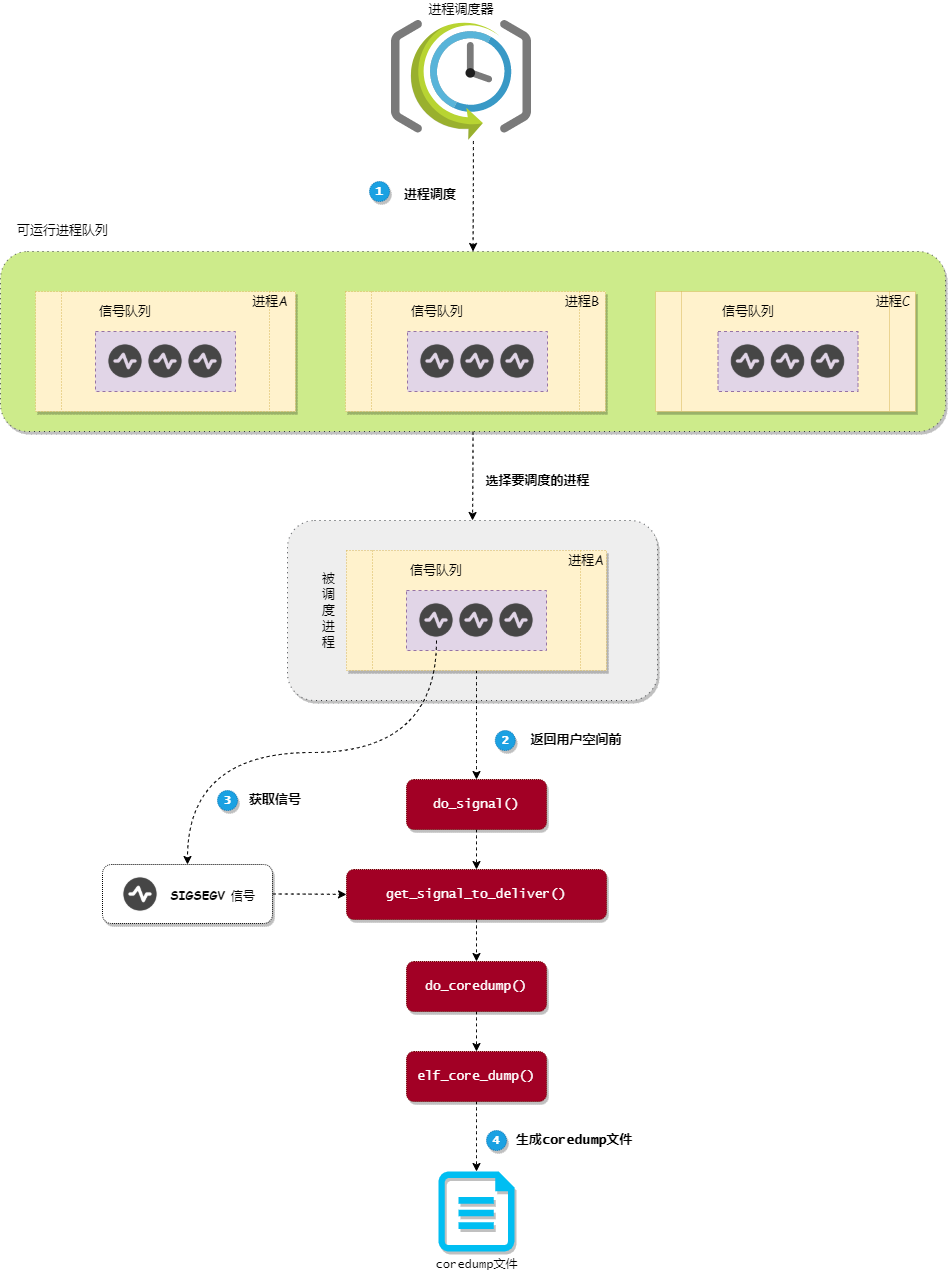
进程从内核态返回到用户态的地方有很多,如 从系统调用返回、从硬中断处理程序返回 和 从进程调度程序返回 等。上图主要通过 从进程调度程序返回 作为示例,来展示内核是怎么生成 coredump 文件的。
下面我们来分析一下 coredump 文件生成过程的步骤:
1. 信号处理 do_signal()
当进程从内核态返回到用户态前,内核会查看进程的信号队列中是否有信号没有被处理,如果有就调用 do_signal 内核函数处理信号。我们来看看 do_signal 函数的实现:
static void fastcall do_signal(struct pt_regs *regs)
{
siginfo_t info;
int signr;
struct k_sigaction ka;
sigset_t *oldset;
...
signr = get_signal_to_deliver(&info, &ka, regs, NULL);
...
}
上面代码去掉了很多与生成 coredump 文件无关的逻辑,最终我们可以看到,do_signal 函数主要调用 get_signal_to_deliver 内核函数来进行进一步的处理。
get_signal_to_deliver 内核函数的主要工作是从进程的信号队列中获取一个信号,然后根据信号的类型来进行不同的操作。我们主要关注生成 coredump 文件相关的逻辑,如下代码:
int get_signal_to_deliver(siginfo_t *info, struct k_sigaction *return_ka,
struct pt_regs *regs, void *cookie)
{
sigset_t *mask = ¤t->blocked;
int signr = 0;
...
for (;;) {
...
// 1. 从进程信号队列中获取一个信号
signr = dequeue_signal(current, mask, info);
...
// 2. 判断是否会生成 coredump 文件的信号
if (sig_kernel_coredump(signr)) {
// 3. 调用 do_coredump() 函数生成 coredump 文件
do_coredump((long)signr, signr, regs);
}
...
}
...
}
上面代码去掉了与生成 coredump 文件无关的逻辑,最后我们可以看到 get_signal_to_deliver 函数主要完成三个工作:
调用 dequeue_signal函数从进程的信号队列中获取一个信号。调用 sig_kernel_coredump函数判断信号是否会生成coredump文件。如果信号会生成 coredump文件,那么就调用do_coredump函数生成coredump文件。
2. 生成 coredump 文件
如果要处理的信号会触发生成 coredump 文件,那么内核就会调用 do_coredump 函数来生成 coredump 文件。do_coredump 函数的实现如下:
int do_coredump(long signr, int exit_code, struct pt_regs *regs)
{
char corename[CORENAME_MAX_SIZE + 1];
struct mm_struct *mm = current->mm;
struct linux_binfmt *binfmt;
struct inode *inode;
struct file *file;
int retval = 0;
int fsuid = current->fsuid;
int flag = 0;
int ispipe = 0;
binfmt = current->binfmt; // 当前进程所使用的可执行文件格式(如ELF格式)
...
// 1. 判断当前进程可生成的 coredump 文件大小是否受到资源限制
if (current->signal->rlim[RLIMIT_CORE].rlim_cur < binfmt->min_coredump)
goto fail_unlock;
...
// 2. 生成 coredump 文件名
ispipe = format_corename(corename, core_pattern, signr);
...
// 3. 创建 coredump 文件
file = filp_open(corename, O_CREAT|2|O_NOFOLLOW|O_LARGEFILE|flag, 0600);
...
// 4. 把进程的内存信息写入到 coredump 文件中
retval = binfmt->core_dump(signr, regs, file);
fail_unlock:
...
return retval;
}
经过代码精简后,最终可以看到 do_coredump 函数完成四个工作:
判断当前进程可生成的 coredump文件大小是否受到资源限制。如果不受限制,那么调用 format_corename函数生成coredump文件的文件名。接着调用 filp_open函数创建coredump文件。最后根据当前进程所使用的可执行文件格式来选择相应的填充方法来填充 coredump文件的内容,对于ELF文件格式使用的是elf_core_dump方法。
elf_core_dump 方法的主要工作是:把进程的内存信息和内容写入到 coredump 文件中,并且以 ELF文件格式 作为 coredump 文件的存储格式。有兴趣的可以自行阅读 elf_core_dump 方法的代码,这里就不作进一步的解说了。
三、生产环境应该打开 coredump 功能吗?
最后,我们来讨论一下在生产环境应不应该打开 coredump 功能。
笔者遇过在生产环境打开 coredump 功能而导致的事故,故事如下:
我们上线了一个有 BUG 的 WEB 服务,这个程序是以
master-worker模式运行的。master进程的主要工作是监控worker进程的运行情况,如果worker进程挂掉,master进程会创建新的worker进程来继续工作。由于
worker进程的代码存在漏洞,会导致worker进程访问非法的内存地址而产生SIGSEGV信号(段错误),而SIGSEGV信号会触发生成coredump文件。由于每次
worker进程异常退出后,master进程都会创建新的worker进程来补充,所以最终导致worker进程不断的异常退出和被创建。这样就不断的生成coredump文件,最终导致磁盘被打满。
所以,经过上面的事故,我建议大家不要在生成环境打开 coredump 功能。那么,如果程序有问题怎么排查呢?
我的建议是摘掉线上的某一台机器,打开 coredump 功能,然后模拟发生异常的情况来进行排查。如果人工比较难模拟,那么可以通过使用 tcpcopy 这些工具来把线上的流量导入到调试机器进行调试。生成 coredump 文件后,可以使用 GDB 来进行调试。