
哪个瞬间让你突然觉得CV技术真有用?
共 6565字,需浏览 14分钟
·
2021-12-14 21:03
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
我的爸爸妈妈都是一个西南小城的大学老师。自从有记忆的时候开始,每次到他们期末考试的时候,他们就要花上好几天的时间改卷。最近几年,步入中年的他们开始老花了,改卷越来越费力,特别是我妈妈本身就高度近视,所以有时候得让学生帮忙。但是每张试卷四十到六十道选择题,我爸上的还是公共课,学生更多。
今年过年的时候,我刚毕业还没入职,赋闲在家,就请了两个研究生同学跑来家里玩,然后他们也“顺便”改了一下选择题。整个过程非常枯燥,得吃好几碗螺丝粉才能补回来。然后我忽然意识到,我们三个可能是家乡历史上出现过计算机水平最高的三颗大脑,还都是CMU毕业搞智能信息系统的,竟然还要做这种本应该交给计算机干的活儿,于是我自然而然想到了把它自动化。
答题卡读卡机是很早很早就有的东西了,但是主要有几点原因爸爸妈妈他们学校一直没有用上:
设备太贵
淘宝答题卡读卡器5000元起。加上反腐之后,审计收紧,这种价格的设备需要统一通过政府采购,价格更加高昂,如果要购买这种设备手续非常复杂。
需要专用答题卡
这进一步提升了使用成本,一般一张答题卡的采购价是一毛钱。
使用复杂
爸爸妈妈虽然电脑已经用得很溜了,但是现在已有的软件的操作界面还是让老一辈教师望而却步——所以有的院校得专门雇人来操作答题卡读卡器。
刚好我本科接触过图像和视频处理技术,在CMU的时候某个课程项目是识别手写公式转换成Latex,个人有一定的技术积累。刚好签证例行被行政审查,暂时没法入职,过年期间就开始设计这么一个系统。针对上面三点,这个系统需要有以下几个特性,我一并做了调研:
设备尽可能简单易用
之前,在我印象中扫描还是手动模式,需要扫完一张,再放下一张……
直到我到CMU才第一次见识了自动送纸(Auto Document Feeder)扫描仪。
同时我在网上看了一下价格,自动进纸扫描仪最便宜的新品是国产的 清华紫光-F20S,只要1150元包邮,这个价格就算我自己掏腰包也可以承受,而且50张的纸匣已经基本足够一般教学的使用了。
普通打印机就能打印的黑白答题卡
常见的答题卡的框线一般都做成红、绿、蓝三种颜色:

对应计算机中RGB的颜色表示方式,这样在做图像处理的时候,能够用阈值法轻松把框线等非答案的内容筛掉筛掉,只剩下学生填涂的结果。这样,再根据四周的定位块来确定学生的填涂内容。
如果变成黑白的,就需要把学生填涂的内容答案从背景中分离出来,这其实增加了一点难度,但是考虑到之前在CMU的课程设计里做过类似的事情,技术上是可以解决的。
操作步骤尽可能简单
所以我需要尽可能简化使用流程,让使用者少做选择,尽可能只需要三步:选择文件——处理——得到结果
除此之外,我还想整个东西看起来厉害一点。
前面说道我在CMU做过类似的事情,大概的项目效果是把手写公式转换成Latex公式:
看上去很酷,但实际上做了如下两个假设之后一点也不难:
字符之间没有粘连
同级的字母基本上都保持在一个水平线上
难点就在有的字符是被分成两部分的,需要合并,比如等号,阶乘号和i,j……可以“启发式”合并,或者实在太难可以假设他们不存在好了……(科学就是这么进步的嘛,基础性、积累性的工作靠大部分普通人解决,挑战性的工作由少部分天才解决)
识别这一块,机器学习的库现在封装得太好用了,基本上搜集到数据丢进去无脑训练就行,更何况这个只是机器学习入门必读教程——识别手写数字的升级版。只需要多采集一些手写数据就好了。
当时我搞了这么一个表格,让爸爸妈妈在上课的时候找学生去填:
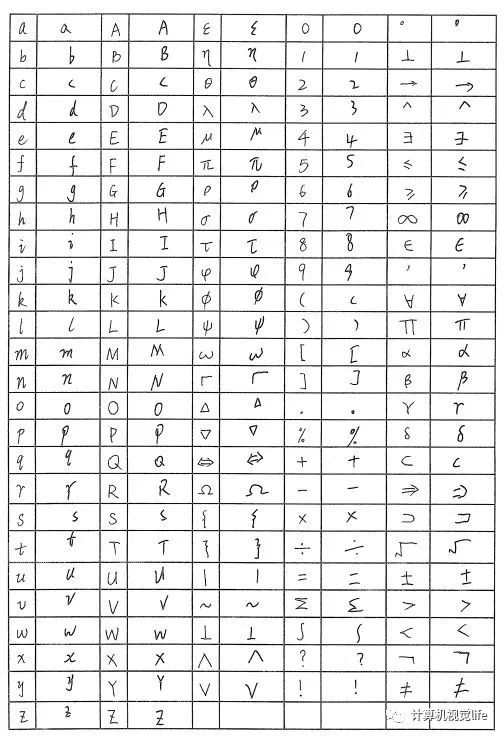
然后用了一些框线检测的算法和字符提取的算法搞出了个数据集,训练模型的测试效果也还行。
所以我刚开始做的时候野心比较大,想把填涂式改为手写式的答题卡,因为选项最多只有ABCDEFG和勾叉。
有了之前的想法,我就开始动手实现。
答题卡
第一步肯定是核心功能,识别。第一版的答题卡设计我已经找不到了,但是大致思想跟第二版差不多,学号部分也是手写的:
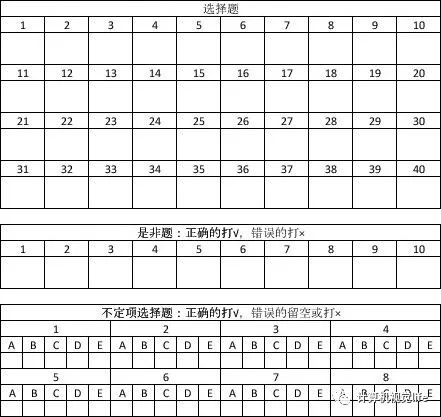
不定向选择题之所以设计成这样,是因为实际使用中让学生写多个选项的时候不连笔这个假设很难成立:一方面自然是学生书写习惯的问题;另一方面,即便学生书写没有问题,也可能会因为纸张、扫描仪的问题意外出现一些笔迹的断裂和符号的粘连。
一旦出现笔迹断裂、字母粘连的情况,就需要加入切割算法——这恰恰是验证码中一个比较难解决的问题——更何况,验证码识别器只需要30%的准确率就能凑合用,达到60%的准确率就基本满足需求了,而评卷时的准确率是以人的识别准确率(95%以上)作为标准的。
同时,就算能够成功切割,往往也会引入一些变形,对识别准确率造成负面影响。
所以,这个表格定下来后,大致处理方法是这样:提取出三块最大的矩形,然后利用框线检测方法去掉框线,提取出表格中的字母,标准化(居中、放大、填补边缘)之后利用上次收集的手写字符数据训练分类器并识别。
然而,这时候我才发现,训练出来的模型能够平均达到97%的准确率,但是具体测试总会出现一些匪夷所思的识别错误,有点类似One pixel attack for fooling deep neural networks(针对深度神经网络的单像素攻击)里面提到的问题。虽然97%的准确率也算可以接受了,因为要是我自己来改看走眼一两个很正常,但是我自己很不满意,毕竟如果有人刚好因为一个识别错误冤枉挂了那是很不好的(明明没过的过了那就不管了)。而且有一部分识别错误发生在学号部分,这会导致登记分数的时候需要额外的人工核对工作,尽管把学号改成填涂式能够解决这个问题。
主要原因我估计是数据集不够(总共加起来有效样本才一千来份),加上采集数据时示例字体是我手写的,可能很多人的写法会受到我的影响,然而真正测试的时候则会用自己的写法。再进行大规模采集的话,估计比较困难,所以我最后放弃了手写识别这个想法。
由于基于框线的定位在实际使用中并不是特别让人满意,我也没想出来什么简单可靠的算法,于是我打算另辟蹊径,寻找更好的定位的方法。普通识别卡是在角上放色块,但是色块本身也比较容易受干扰,调试起来也比较麻烦,还是不方便。
经过反复思考,第三版答题卡设计成了这样:

没错,就是这么简单粗暴。角上借鉴了二维码的定位块技术。二维码还有一个名称叫做Quick Response Code,原因就在于这三个定位块,它能够让程序很方便地定位二维码的区域。定位这三个方块的算法有很多,具体实现我参照的是这篇文章:OPENCV: QR CODE DETECTION AND EXTRACTION
大致的原理是对图像进行边沿检测,然后根据边沿的嵌套关系提取出候选块,最后抽出最可能的三个。
然后四周的黑块用于辅助答案的定位。其实,因为扫描仪扫描的图像基本没有形变,所以可以不需要的。但是当时考虑到我需要一次性设计多种满足不同需求的答题卡,所以采取了这种实现。后来想想其实如果在提交的时候已经知道答卷类型,其实完全可以去掉这些黑色辅助定位方块,以降低印刷难度(有的打印机在打印黑色色块的时候会有油墨不均匀的情况)和油墨消耗。
之后妈妈在年级搞英语能力竞赛,试用了一下,识别上没有什么大问题,但是这张答题卡的设计上却有些问题:由于空间不足的关系,我把学号拆成了两栏,内部横向填写,两栏却是纵向摆放,同时既有手写的框,又有填涂的框(主要想顺便采集手写数字的数据)。这样很多学生在填涂学号的时候就出现了如下情况:
写了学号没填涂
只填上面一栏学号,同时前五位学号手写,后五位学号填涂
漏填学号某一位
……
真是感叹,你永远不知道用户会以什么奇怪的姿势用你的产品。于是,最后我把答题卡设计成了这样:
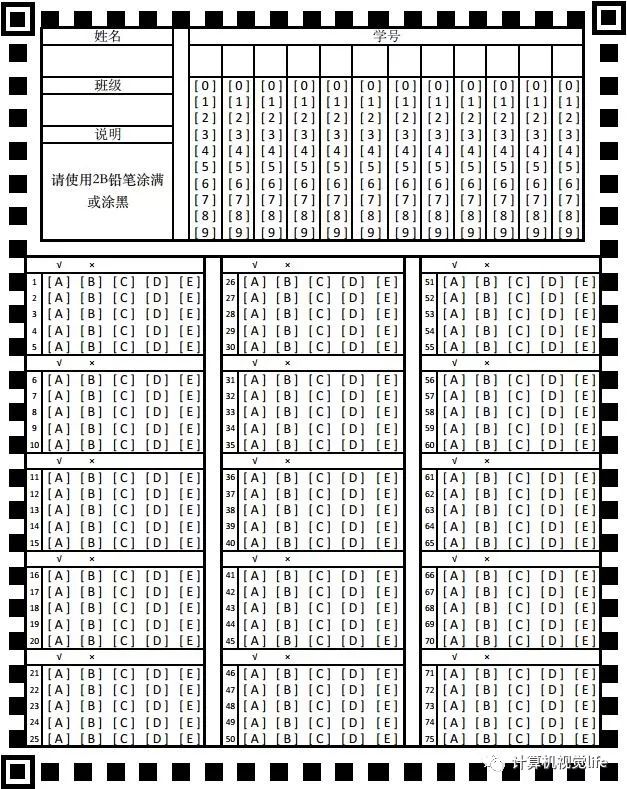
这样之后,学生犯错误的概率大大降低,也基本达到效果了,有时间的话,下一步就是把四周的黑色定位块给去掉。
评卷系统
答题卡设计好之后,识别算法基本上水到渠成,只不过实际情况中会有一些琐碎的细节和特殊情况需要仔细调较。
下一步就是评卷系统了,从提交答案、答题卡到汇总成绩,要尽可能简单。首先我不想让他们安装任何软件,因为这会引入额外的操作步骤,每多一步他们就会困惑一点;其次,我要使用他们尽可能熟悉的操作模式和软件来完成我的功能。
于是我最后采用的是:扫描成PDF文件——网页提交——网页预览——下载详表的模式。
我自己买回来测试的是富士通(Fujitsu) IX500的扫描仪,这个扫描仪实在是太给力了,一键扫描保存成PDF,这给我省了很大的事。
后面的网页处理看似简单,但是实际上琐碎的事情非常多:
首先说网页提交吧,一个班扫描出来的文件往往3~20M大小(有的扫描仪扫出来的灰度模式,没有压缩),考虑到国内网站需要备案,而且国内运营商的上传带宽都小得可怜,所以我得把服务器放在大陆之外,这样一来上传时间过长会导致他们忍不住刷新,所以必须至少有一个上传进度条,更好的实现是切片上传。
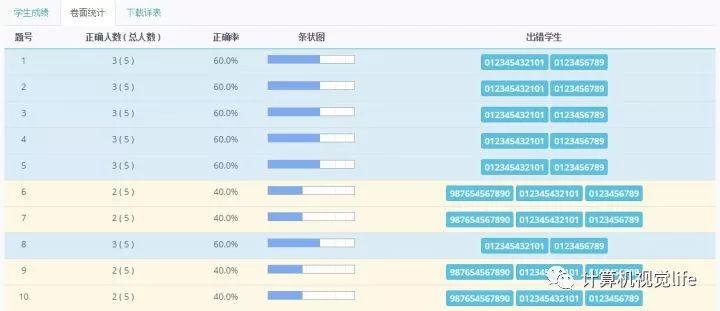
其次,尽管识别算法已经足够强壮,但是仍然免不了一些识别不了的情况,比如学生把识别块给整个涂黑了(真有这样的学生),印刷缺陷等等,这时候必须把识别出错的答题卡给列出来,悄无声息地出错然后把学生的答题卡吞了就不好了。
还有,因为大部分情况下最后的个人总分、单项总分、平均分、每一题的正确率等信息都是需要汇总给教务处的,我需要一个方便他们提取这些信息的方式。
说起来上一次写这种网站还是三年前在大摩实习的时候,当时前端Bootstrap+jQuery,后端Django还是主流,本着先让它跑起来的目的我沿用了当时的架构,虽然可能已经有一点老了,但是至少一切都在我的控制之内。
具体实现细节没太多可以说的,三个字概括的话就是:糙快猛,要是在公司写这种代码的话是会被拖出去打的,就给大家简单看看效果吧。
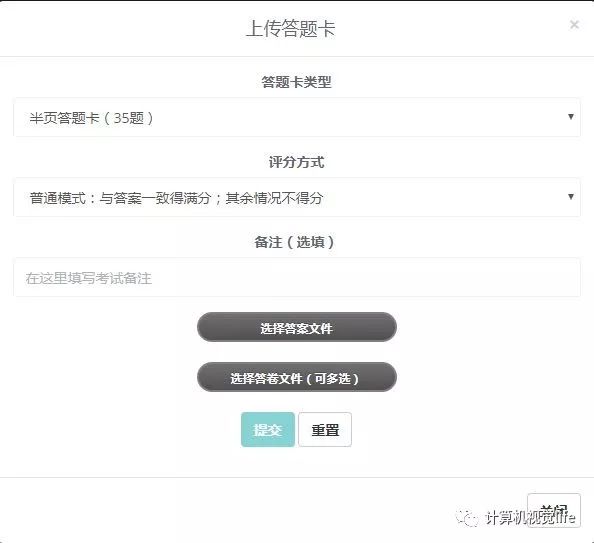

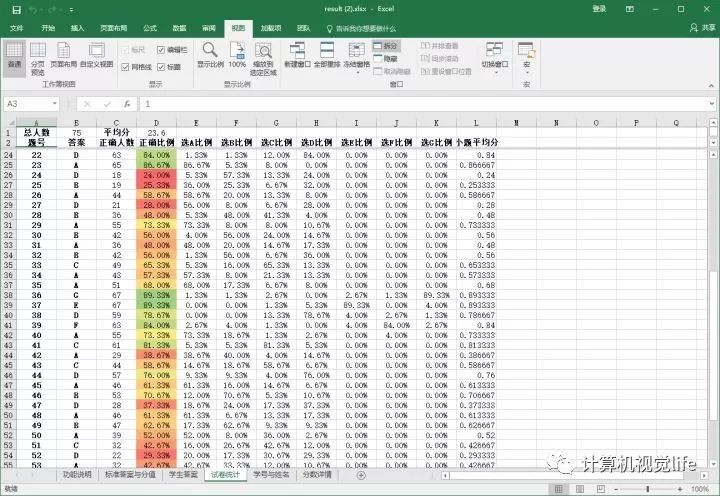
值得一提的是,我在做Excel输出的时候费了很大的力气,因为我想做到以下几点:
保证数据一致性,即老师改了答案和分值,后面学生的得分也要改
支持筛选,比如提交了全年级的答卷,如果筛选了某个班级的学生,对应的统计数据也得改
支持多选题少选给一半分,不选错选给0分的情况
尽可能使表格好看、通用、易用
为了保证一致性,我需要使用大量的公式,大部分公式还是比较简单,主要是公式多了工作比较琐碎,可谓牵一发而动全身。但是有少部分公式要写起来还是非常蛋疼的,主要原因是我想避免使用VBA,因为大部分老师的电脑安全设定是屏蔽VBA的,这大大增加了工作量,比如答案分值是一列,而学生的得分是一行,EXCEL里行列乘法是没有的。
还有第三点,大家可以想想怎么用EXCEL的公式实现这一点,我的实现方法非常的猥琐……
经过三个月的开发和不停地调较,现在整个系统的稳定性和识别率都非常不错,后来给我中学老师拿去试用反馈也非常好,这可能是我目前为止自己做的最有用的一个项目了。
只是爸爸妈妈最后想拿去期末考试使用的时候,遇到了学院里面的一些阻力,某些认识了十几年的人以种种奇怪的理由作梗,最后我妈妈三番五次打报告,一再声明不要钱,并请计算机系的老师写书面测试证明了之后才同意使用。爸爸那边则只在他自己教的班级使用,不过这也就够了。
好在我写的代码质量还是可以的,成功经受住了接近两千多份的试卷的考验,办公室的老师也纷纷表示好使,写试卷分析也爽多了。他们也进一步提供了一些意见,比如最后每个学生的选项需要打印存档确认,所以需要用下划线标识对的、错的、部分对的各种细节等等。
从工程上说,这其实算是我写的第一个比较大的实用型项目,给我最大的感受就是,你永远不知道客户以什么姿势用你的产品。在发布前进行内部封测还是很必要的,的的确确能够发现很多的问题和改进建议。
我最近在读《人月神话》,里面提到一点就是,如果说程序需要一倍的工作量,那么到程序系统产品组件需要九倍的工作量。我第一次切切实实感受到,此言不虚。写识别算法的时候尤其感受到回归测试的重要性——然而我一直没有写回归测试,因为工作量有点太大了。
回到题主的问题,什么时候觉得读书有用?我曾经回答过这样一个问题:知乎用户:为什么软件工程专业要学习大学物理?这个回答引起了很多人的讨论,包括我一些很厉害的同学也有表示反对的。这一次,我觉得又可以增加一条论据了:在答题卡识别的算法中我使用了仿射变换,如果不是学过线性代数、大学物理、机器视觉,我可能会卡在那儿很久甚至放弃。
可能因为爸爸妈妈是老师的缘故,我一直觉得读书、做题、工作是一件很有意思的事情,有时候理论的确枯燥,但是绝大部分理论都是出自生活中非常有意思的问题。所以,就知识而言,它一定是有用的,只是需要在合适的地方发挥作用。
本科有一个同学是学临床医学的,但是他课余在心理学上花费了很多的时间。我们当时就问,心理学毕业的话,除了能做心理医生还能干嘛呢?他跟我说,很多啊,心理学有一个分支叫工程心理学,专门研究人、机器与环境的关系。很多毕业生都跑去飞机制造业,研究飞行员的心理,以设计出尽可能让飞行员操纵简单、不犯错的飞行控制系统。很多产品功能上完全一样,但是就是交互上有天壤之别,比如前面我提到的答题卡中学号的排布,以及飞机上操纵杆的位置,等等。
所以说,保持眼界开阔,多接触新知识,往往在意想不到的时候会对自身有所帮助。
另一方面,说实话,这个项目拉给任何一个合格的一流计算机专业毕业生来做应该都不是问题,现实中这样不需要太多技术就可以改进和提高的东西还有很多。哈哈,“改变世界”的门槛似乎并没有那么高嘛。很多人不太喜欢李开复老师的“鸡汤”,但是我很欣赏他自传《世界因你不同》中的信念,并且努力践行。女朋友一直说我是情怀党,做这个项目我慢慢感觉到,可能还真是。我很享受这种利用自己所学来产生正面影响的事情,哪怕只是一丁点。这一次,当满头华发的爸妈不再费劲地批阅选择题,远在他乡的我感到了一点点慰藉,我的所学似乎赚回了一点点学费。
最后,罗哩罗嗦写了这么多,非常感谢你能够听我分享这个故事。:)
其实,我现在最想做的功能是手机拍照了之后就能识别,就像全能扫描王那样的,不需要专门扫描仪。这样会大大方便一些没法购买ADF扫描仪的老师。
但是手机拍照最大的问题是成像质量不稳定。可能会由于光照的原因导致现有的二值化算法不适用,同时在不同情况下会有形变和畸变,形变尚好解决,只需要一个坐标变换,但是畸变就难了。我有一些初步的想法,基于网格变换搞一个估价函数然后做梯度下降来寻找最优变换,但是这个工作量比较大也不知道效果如何,感觉这应该是一个很有趣的问题。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~