
即插即用 | 或许你的NMS该换了,Confluence更准、更稳的目标检测结果
共 3951字,需浏览 8分钟
·
2020-12-21 10:11
新智元报道
新智元报道
来源:AI人工智能初学者
作者:ChaucerG
【新智元导读】本文提出了一种优于NMS的非IoU替代方案,其在边界框保留和抑制方面不依赖IoU或最大置信度得分。在YOLOv3、RetinaNet和Mask R-CNN等检测器上实验证明,Confluence比NMS性能更强,更可靠!

简介
本文提出了一种在目标检测中的边界框选择和抑制任务中替代贪婪非极大值抑制(NMS)的新颖方法。它提出了Confluence,该方法不仅不依赖于置信度得分来选择最佳边界框,也不依赖于IoU来消除误检。其通过使用“曼哈顿距离”来选择最接近群集中其他所有边界框的边界框,并删除具有高度融合的相邻框。
因此,Confluence与基于Greedy NMS及其变体具有根本不同的理论原理,Confluence代表了边界框选择和抑制的范式转变。
使用MS COCO和PASCAL VOC 2007数据集在RetinaNet,YOLOv3和Mask-RCNN上对Confluence进行了实验验证。
使用具有挑战性的0.50:0.95 mAP评估指标,在每个检测器和数据集上,mAP改善了0.3-0.7%,而召回率则提高了1.4-2.5%。
此外,跨mAP阈值的灵敏度分析实验支持以下结论:Confluence比NMS更可靠。

2 致敬NMS-们
2.1、NMS诞生的必要性

NMS操作流程
NMS用于剔除图像中检出的冗余bbox,标准NMS的具体做法为:
step-1:将所有检出的output_bbox按cls score划分(如pascal voc分20个类,也即将output_bbox按照其对应的cls score划分为21个集合,1个bg类,只不过bg类就没必要做NMS而已);
step-2:在每个集合内根据各个bbox的cls score做降序排列,得到一个降序的list_k;
step-3:从list_k中top1 cls score开始,计算该bbox_x与list中其他bbox_y的IoU,若IoU大于阈值T,则剔除该bbox_y,最终保留bbox_x,从list_k中取出;
step-4:选择list_k中top2 cls score(步骤3取出top 1 bbox_x后,原list_k中的top 2就相当于现list_k中的top 1了,但如果step-3中剔除的bbox_y刚好是原list_k中的top 2,就依次找top 3即可,理解这么个意思就行),重复step-3中的迭代操作,直至list_k中所有bbox都完成筛选;
step-5:对每个集合的list_k,重复step-3、4中的迭代操作,直至所有list_k都完成筛选;
以上操作写的有点绕,不过如果理解NMS操作流程的话,再结合下图,应该还是非常好理解的;
def nms(boxes, scores, overlap=0.5, top_k=200):
keep = torch.Tensor(scores.size(0)).fill_(0).long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1) # IoU初步准备
v, idx = scores.sort(0) # sort in ascending order,对应step-2,不过是升序操作,非降序
# I = I[v >= 0.01]
idx = idx[-top_k:] # indices of the top-k largest vals,依然是升序的结果
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
# keep = torch.Tensor()
count = 0
while idx.numel() > 0: # 对应step-4,若所有pred bbox都处理完毕,就可以结束循环啦~
i = idx[-1] # index of current largest val,top-1 score box,因为是升序的,所有返回index = -1的最后一个元素即可
# keep.append(i)
keep[count] = i
count += 1 # 不仅记数NMS保留的bbox个数,也作为index存储bbox
if idx.size(0) == 1:
break
idx = idx[:-1] # remove kept element from view,top-1已保存,不需要了~~~
# load bboxes of next highest vals
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
# store element-wise max with next highest score
xx1 = torch.clamp(xx1, min=x1[i]) # 对应 np.maximum(x1[i], x1[order[1:]])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0) # clamp函数可以去查查,类似max、mini的操作
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
# 以下两步操作做了个优化,area已经计算好了,就可以直接根据idx读取结果了,area[i]同理,避免了不必要的冗余计算
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i] # 就是area(a) + area(b) - i
IoU = inter/union # store result in iou,# IoU来啦~~~
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)] # 这一轮NMS操作,IoU阈值小于overlap的idx,就是需要保留的bbox,其他的就直接忽略吧,并进行下一轮计算
return keep, count
2.2、Soft-NMS
不同于在NMS中采用单一阈值,对与最大得分检测结果M超过阈值的结果进行抑制,其主要考虑Soft-NMS,对所有目标的检测得分以相应overlap with M的连续函数进行衰减。
其伪代码如下:

2.3、ConvNMS
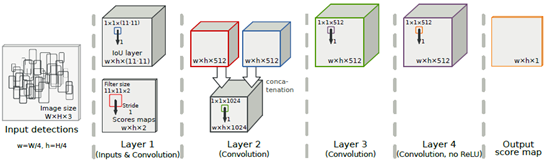
其主要考虑IoU阈值设定得高一些,则可能抑制得不够充分,而将IoU阈值设定得低一些,又可能多个ture positive被merge到一起。
其设计一个卷积网络组合具有不同overlap阈值的greedyNMS结果,通过学习的方法来获得最佳的输出。基础框架如下:
2.4、Pure NMS Network
考虑目标间具有高遮挡的密集场景,其提出一个新的网络架构来执行NMS。
经分析,检测器对于每个目标仅产生一个检测结果有两个关键点是必要的,一是一个loss惩罚double detections以告诉检测器我们对于每个目标仅需一个检测结果,二是相邻检测结果的joint processing以使得检测器具有必要的信息来分辨一个目标是否被多次检测。
论文提出Gnet,其为第一个“pure”NMS网络。Gnet图示如下:

2.5、Greedy NMS
IoU本质上是计算两个边界框的交集与并集的比率(交并比)。然后利用聚类中每个框的平均坐标选择一个最优的框。目前很多检测任务中采用了这种方法,以产生现在所称的Greedy NMS。
Greedy NMS首先根据候选边界框的置信度分数从最高到最低进行排序,从而提高了准确性。选择置信值最高的边界框,然后用所选框抑制所有IoU超过预定义阈值的边界框。
这一过程重复进行,直到候选集中没有边界框为止。实验结果表明,与其他NMS变体相比,该方法的平均精度更高,因此具有更强的优越性。
本文方法
所提出的方法称为Confluence。名称来源于一个目标检测器在检测到一个对象时返回的检测框的集合。
Confluence并没有将过多的建议视为一个问题,而是将其作为一种识别最优边界框的方法。这是通过识别与其他边界框最Confluence的边界框来实现的,也就是说,该边界框最能代表集群内其他框的相交集合。
Confluence是一个2阶段的算法,它保留了最优边界框,并消除了假阳性。第1阶段使用置信加权曼哈顿距离启发接近测量来评估边界框的一致性。第2阶段涉及移除所有与保留的边界框Confluence边界框。
3.1 曼哈顿距离
曼哈顿距离或范数,是两个点之间垂直和水平距离的总和。与之间的可以表示为:
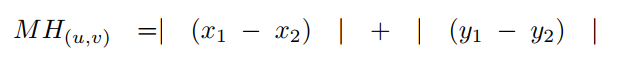
基于DCNN的传统和现在目标检测器都有一个明显的特点,就是返回大量的检测结果,在图像中感兴趣的位置周围形成边界框簇。
本文提出,任意两个边界框之间的接近程度可以用、、和坐标对之间的之和表示:

图2提供了接近测量的图示:

P值比较小表示高度Confluence的边界框,而P值比较高表示候选框不是由同一物体产生得到的,它们可能只是在某种程度上重叠,或者完全不相交。
因此,可以推断出,如果一个给定框的P与一组边界框中的其他所有框进行比较,它将提供它与其他所有框Confluence度量。当边界框密集汇聚时,这种计算将涉及大量的比较。
因此,被密集的一群边界框包围的边界框,其P值会非常低,而没有被相互竞争的边界框包围的边界框,可以被正确地归类为离群值。实际上,这提供了目标检测器在给定位置存在对象时的置信度的度量。在此基础上,本文提出,聚类内P值最低的边界框b表示对给定对象的最自信检测。
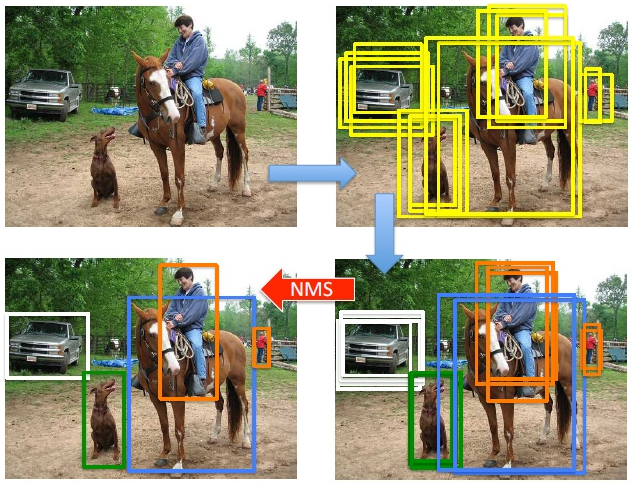
值得注意的是,这一理论方法克服了NMS及其替代方案所面临的一个问题——在最高得分边界框与另一个较低得分边界框相比不是最优的情况下,NMS返回次优边界框,如图1所示。相比之下,P度量允许边界框与指定一个给定对象的所有其他边界框最Confluence,使其更鲁棒。
3.2 标准化
前面讨论的方法在边界框大小相似的情况下有效地发挥作用。然而,在实践中,目标及其对应的边框将是不同大小的。
当使用基于置信度加权的p的超参数来管理边界框保留或删除时,这就产生了一个问题。这是因为需要在删除大量假阳性和保留少量真阳性之间进行权衡。
为了解决这个问题,作者使用归一化算法将边界框坐标缩放到0到1之间,同时保持它们之间的关系。归一化算法对各坐标进行如下变换:
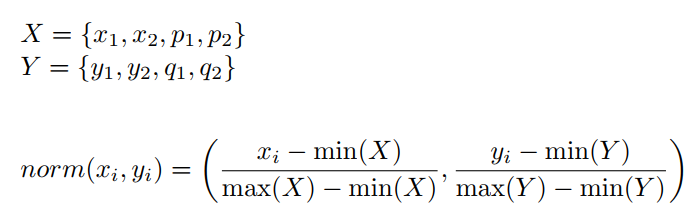
标准化允许通过使任意两个大的目标内边界框与任意两个小的目标间边界框的关系相比较来区分目标内边界框和目标间边界框,如图3所示。
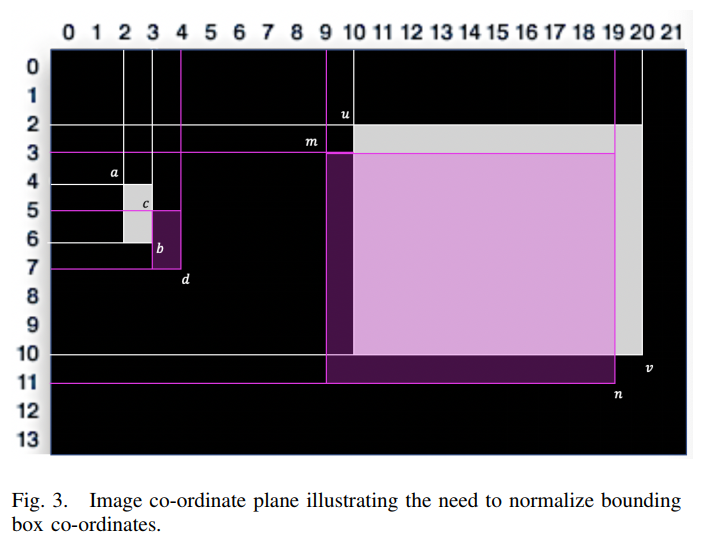
很明显,在图3中,右边的两个大边框表示同一个对象。相反,左边的两个小边框表示两个独立的对象。但当计算P时,得到相同的值,如下:
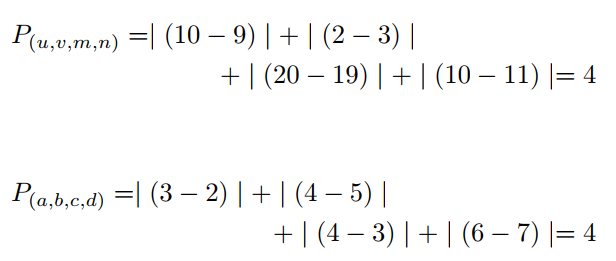
这就产生了区分属于相同或不同对象的边界框的问题。标准化通过保留边界框之间的重叠关系来解决这个问题,同时确保可以比较任意两个边界框关系。
3.3 类内保留和删除
由于所有坐标对都归一化在0到1之间,因此任何一对相交的边界框的接近值都小于2。因此,如果任意两个边界框的P值小于2,则假设它们属于同一簇,因此指的是同一对象,或者指一个或多个高密度对象。一旦识别出簇,通过对P值升序排序,找到簇内最优边界框。取第n个位置接近度最小的边界框为最Confluence的边界框保留。
然后分析P值的聚类内梯度,选择最Confluence的边界框。通过绘制P值的图,可以显示对象内和对象间边界框之间的差异,这是由于类blob集群的性质,如下图所示。每个水平斑点表示一个对象。Confluence选择最能代表给定blob内其他所有框的边界框。从本质上说,这意味着它在一个梯度趋近于零的数据范围内选择一个方框。
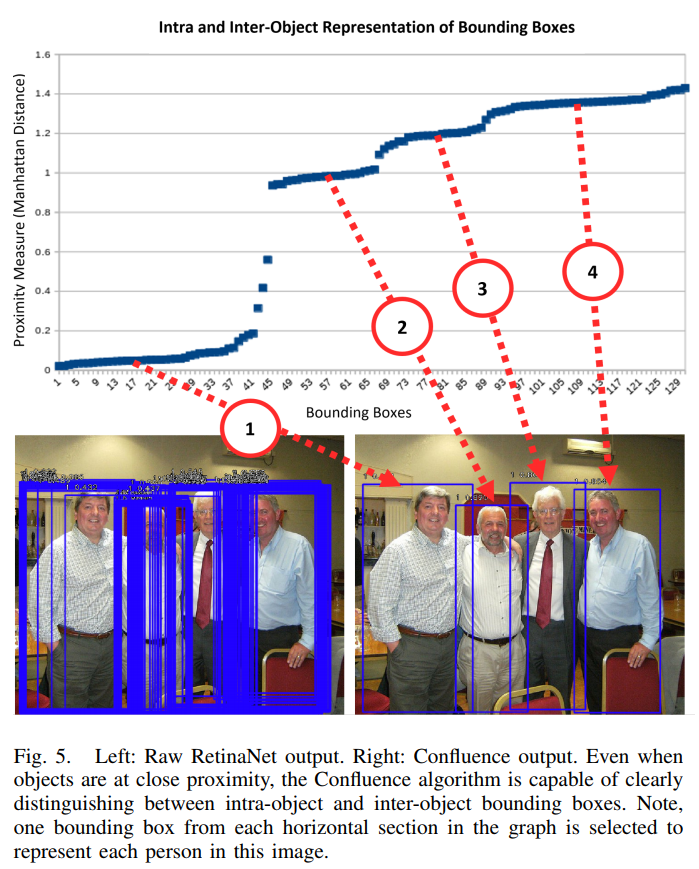
一旦选择了最Confluence的边界框,所有接近值低于预定义阈值的簇内边界框将被移除。递归地重复这个过程,直到处理完所有的边界框。
3.4 置信度得分加权
NMS使用由对象检测器返回的单个置信度分数作为唯一的方法,通过它选择一个“最佳的”边界框。相反,Confluence通过考虑置信分数c和与之竞争的边界框的P值来评估给定边界框b的最优性。通过用除以其置信度得分,可以得到加权接近性:

由于c是一个介于0.05和1之间的值,通过人为地降低的值,这实际上提供了对高置信框的偏爱(注意,置信分数低于0.05的所有边界框都不被考虑)。反之,低置信框的WP值会更大。这增加了选择高置信度框的可能性,因为边界框是基于小的WP值选择的。
算法实现的伪代码

第1步:变量, 和是用来存储边框以及相应的分数和类标签的集合,这些分数和标签将返回并绘制在图像上 第2步:算法分别遍历每个类,这使它能够处理多类对象检测。对于每个类,它选择n个边界框,每个边界框代表一个对象 第3步:定义变量、临时存储边界框和对应的分数,并选择待处理类的最优边界框 第4步:变量被初始化为图像的大小 第5步:循环遍历所有边界框,将每个边界框与集合中的每个边界框进行比较: 第5.1步:规范化坐标关系,然后进行邻近计算 第5.2步:如前所述,如果接近度计算值小于2,则边界框是不相交的,将被视为单独的对象。这个条件将的P值限制小于2 第5.3步:通过对最小置信加权汇合值的收敛,选择一个最优边界框 第6步:选择最优边界框后,将其添加到中,与其对应的类和置信值一起作为最终检测返回,并从集合B,S中去除。 第7步:随后,将B中所有与预定义的超参数以下的最优边界接近的边界框移除。 第8步:递归地执行步骤3-5,直到处理完所有的边界框。
实验
5.1 经典方法插入对比


5.2 可视化对比


 以上结果不难看出使用Confluence方法后检测结果更加精准。
以上结果不难看出使用Confluence方法后检测结果更加精准。
