北大华为鹏城联合首次提出视觉 Transformer 后量化算法!
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

1
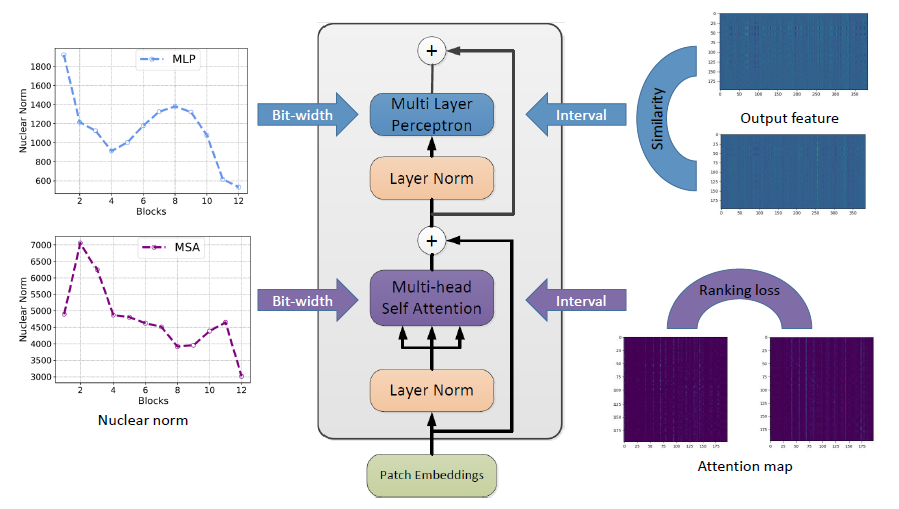
引言
2
方法
2
方法
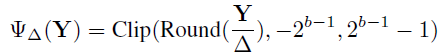 ,
,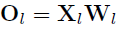 。那对于权重和输入进行均匀量化所对应的反量化函数可以描述为:
。那对于权重和输入进行均匀量化所对应的反量化函数可以描述为: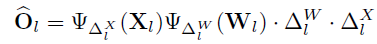 ,
,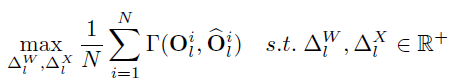
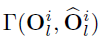 代表原始和量化输出特征之间的相似度,输入数据是由一个远小于训练数据集
代表原始和量化输出特征之间的相似度,输入数据是由一个远小于训练数据集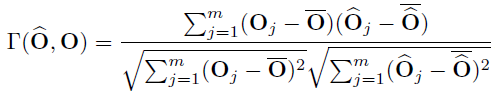
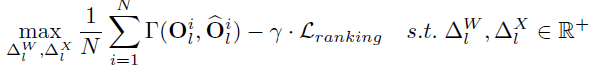
 表示成对的排序损失函数,表示权衡系数。损失函数的公式为:
表示成对的排序损失函数,表示权衡系数。损失函数的公式为: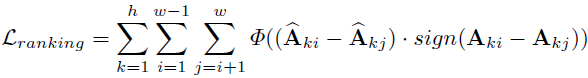
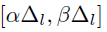 均匀分为了C个选择。
均匀分为了C个选择。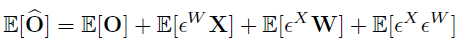

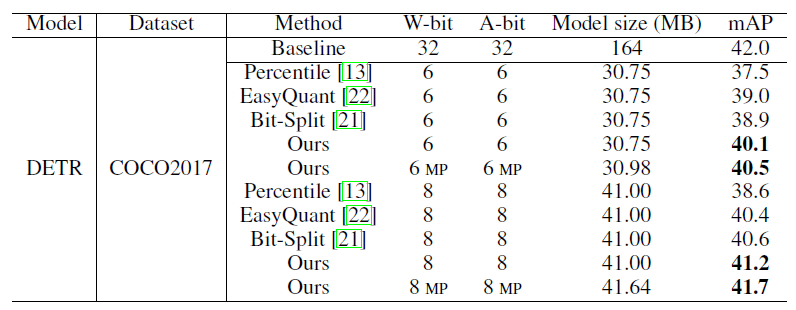
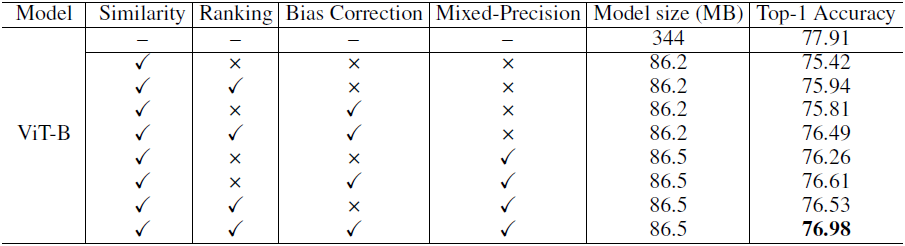
3 实验
实验
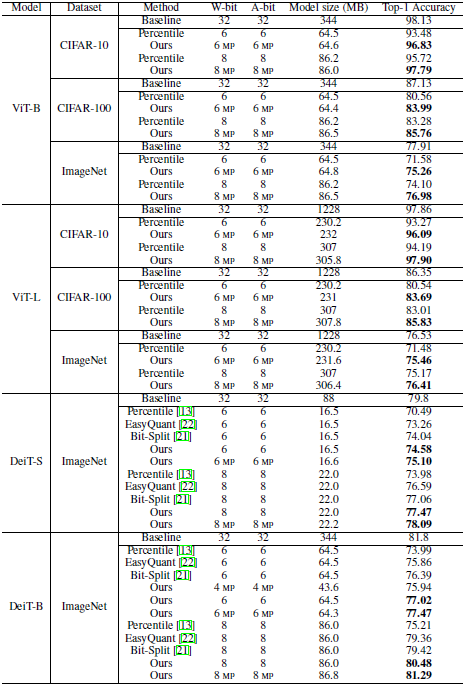
4 总结
总结

点个在看 paper不断!
评论

点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
引言
方法
,。那对于权重和输入进行均匀量化所对应的反量化函数可以描述为:,代表原始和量化输出特征之间的相似度,输入数据是由一个远小于训练数据集表示成对的排序损失函数,表示权衡系数。损失函数的公式为:均匀分为了C个选择。实验
总结
点个在看 paper不断!