
Transformer再下一城!low-level多个任务榜首被占领,北大华为等联合提出预训练模型IPT

极市导读
来自Transformer的降维打击!北京大学等最新发布论文,联合提出图像处理Transformer。通过对low-level计算机视觉任务,如降噪、超分、去雨等进行研究,提出了一种新的预训练模型IPT,占领low-level多个任务的榜首。>>加入极市CV技术交流群,走在计算机视觉的最前沿

本文是北京大学&华为诺亚等联合提出的一种图像处理Transformer。Transformer自提出之日起即引起极大的轰动,BERT、GPT-3等模型迅速占用NLP各大榜单;后来Transformer被用于图像分类中同样引起了轰动;再后来,Transformer在目标检测任务中同样引起了轰动。现在Transformer再出手,占领了low-level多个任务的榜首,甚至它在去雨任务上以1.6dB超越了已有最佳方案。
论文链接: https://arxiv.org/abs/2012.00364
Abstract
随机硬件水平的提升,在大数据集上预训练的深度学习模型(比如BERT,GPT-3)表现出了优于传统方法的有效性。transformer的巨大进展主要源自其强大的特征表达能力与各式各样的架构。
在这篇论文中,作者对low-level计算机视觉任务(比如降噪、超分、去雨)进行了研究并提出了一种新的预训练模型:IPT(image processing transformer)。为最大挖掘transformer的能力,作者采用知名的ImageNet制作了大量的退化图像数据对,然后采用这些训练数据对对所提IPT(它具有多头、多尾以适配多种退化降质模型)模型进行训练。此外,作者还引入了对比学习以更好的适配不同的图像处理任务。经过微调后,预训练模型可以有效的应用不到的任务中。仅仅需要一个预训练模型,IPT即可在多个low-level基准上取得优于SOTA方案的性能。
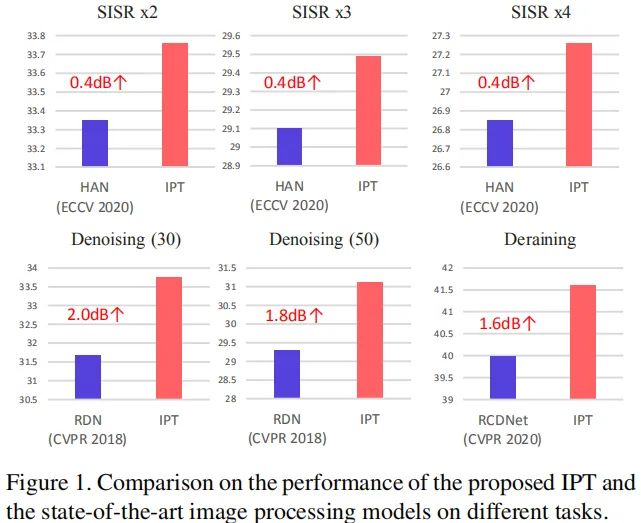
上图给出了所提方案IPT与HAN、RDN、RCDNet在超分、降噪、去雨任务上的性能对比,IPT均取得了0.4-2.0dB不等的性能提升。
Method
为更好的挖掘Transformer的潜力以获取在图像处理任务上的更好结果,作者提出了一种ImageNet数据集上预训练的图像处理Transformer,即IPT。
IPT architecture
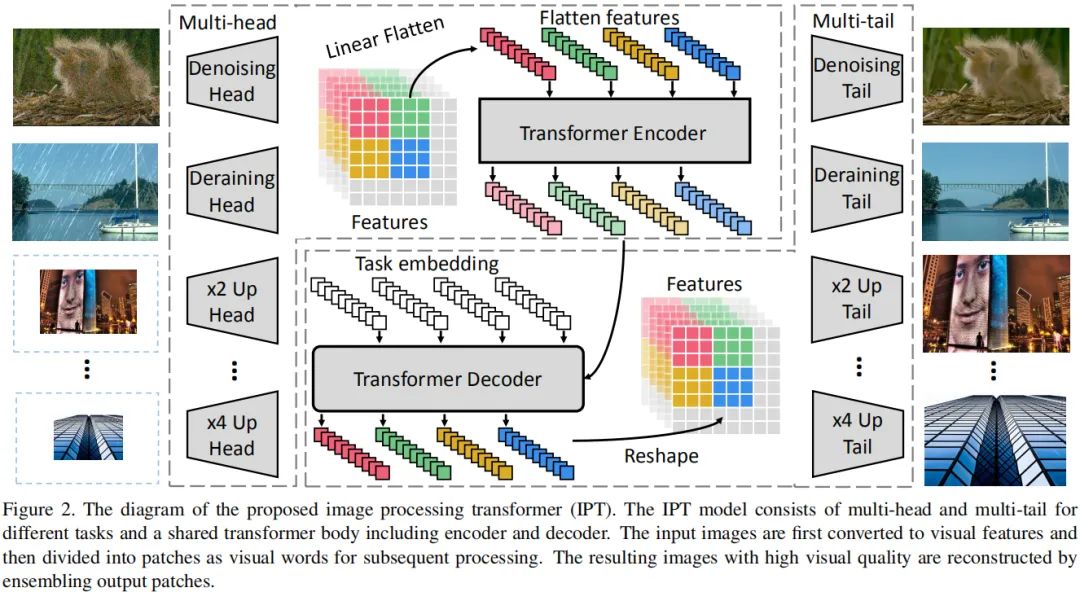
上图给出了IPT的整体架构示意图,可以看到它包含四个成分:
用于从输入退化图像提取特征的Heads; encoder与decoder模块用于重建输入数据中的丢失信息; 用于输出图像重建的Tails。
Heads
为适配不同的图像处理任务,作者提出采用多头(multi-head每个头包含三个卷积层)架构以分别处理不同的任务。假设输入图像表示为,每个头可以生成特征(注:C默认64)。故多头架构的计算过程可以描述为:
其中表示图像处理任务个数。
Transformer encoder
在将前述特征送入到Transformer之前,需要将输入特征拆分成块,每个块称之为“word”。具体来讲,输入特征将被拆分为一系列块,其中表示特征块的数量,P表示特征块尺寸。
为编码每个块的位置信息,作者还在encoder里面添加了可学习的位置编码信息。这里的encoder延续了原始Transformer,采用了多头自注意力模块和前向网络。
encoder的输出表示为,它与输入块尺寸相同,encoder的计算过程描述如下:
其中表示encoder的层数,MSA表示多头自注意力模块,FFN表示前馈前向网络(它仅包含两个全连接层)。
Transformer decoder
decoder采用了与encoder类似的架构并以encoder的输出作为输入,它包含两个MSA与1个FFN。它与原始Transformer的不同之处在于:采用任务相关的embedding作为额外的输入,这些任务相关的embedding用于对不同任务进行特征编码。decoder的计算过程描述如下:
其中表示decoder的输出。decoder输出的N个尺寸为的块特征将组成特征。
Tails
这里的Tails属性与Head相同,作者同样采用多尾以适配不同的人物,其计算过程可以描述如下:
最终的输出即为重建图像,其尺寸为。输出图像的尺寸受任务决定,比如x2超分而言,。
Pre-training on ImageNet
除了transformer的自身架构外,成功训练一个优化transformer模型的关键因素为:大数据集。而图像处理任务中常用数据集均比较小,比如图像超分常用数据DIV2K仅仅有800张。针对该问题,作者提出对知名的ImageNet进行退化处理并用于训练所提IPT模型。
这里的退化数据制作采用了与图像处理任务中相同的方案,比如超分任务中的bicubic下采样,降噪任务中的高斯噪声。图像的退化过程可以描述如下:
其中f表示退化变换函数,它与任务相关。对于超分任务而言,表示bicubic下采样;对于降噪任务而言,。IPT训练过程中的监督损失采用了常规的损失,描述如下:
上式同样表明:所提方案IPT同时对多个图像处理任务进行训练。也就说,对于每个batch,随机从多个任务中选择一个进行训练,每个特定任务对应特定的head和tail。在完成IPT预训练后,我们就可以将其用于特定任务的微调,此时可以移除掉任务无关的head和tail以节省计算量和参数量。
除了上述监督学习方式外,作者还引入了对比学习以学习更通用特征以使预训练IPT可以应用到未知任务。对于给定输入(随机从每个batch中挑选),其decoder输出块特征描述为。作者期望通过对比学习最小化同一图像内的块特征距离,最大化不同图像的块特征距离,这里采用的对比学习损失函数定义如下:
其中表示cosine相似性。为更充分的利用监督与自监督信息,作者定义了如下整体损失:
Experiments
Datasets
作者采用ImageNet数据制作训练数据,输入图像块大小为,大约得到了10M图像数据。采用了6中退化类型:x2、x3、x4、noise-30、noise-50以及去雨。
Training&Fine-tuning
作者采用32个NVIDIA Tesla V100显卡进行IPT训练,优化器为Adam,训练了300epoch,初始学习率为,经200epoch后衰减为,batch=256。在完成IPT预训练后,对特定任务上再进行30epoch微调,此时学习率为。
Super-resolution
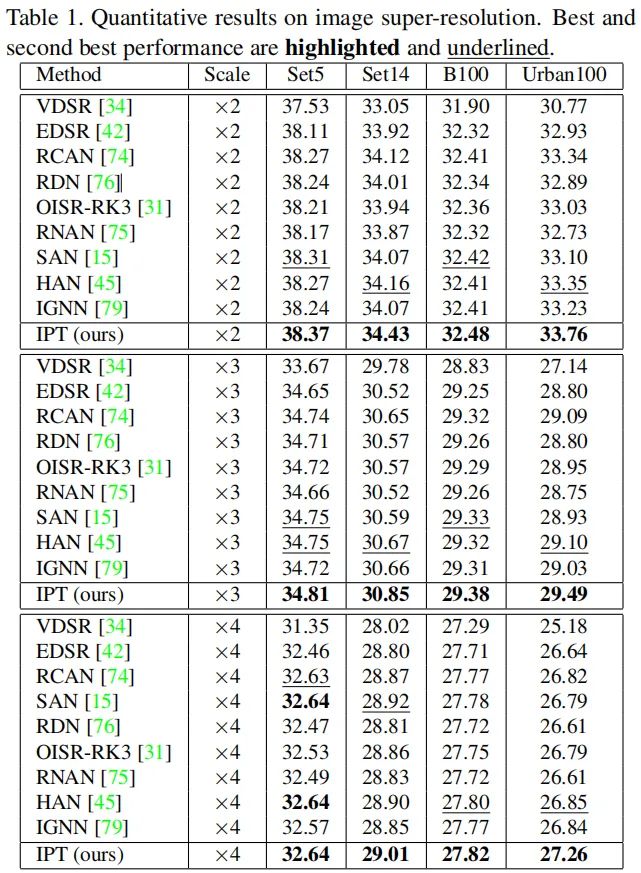
下表&下图给出了超分方案在图像超分任务上的性能与视觉效果对比。可以看到:
IPT取得了优于其他SOTA超分方案的效果,甚至在Urban100数据集上以0.4dB优于其他超分方案; IPT可以更好重建图像的纹理和结构信息,而其他方法则会导致模糊现象。

Denoising
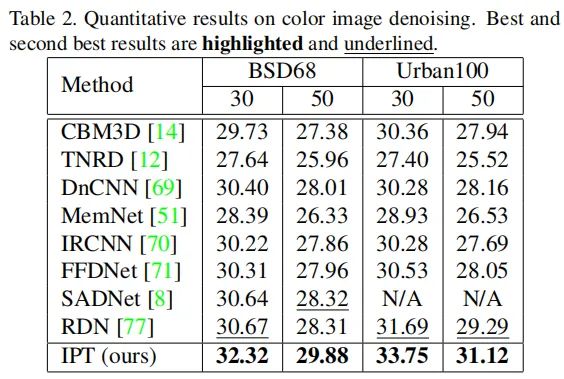
下表&下图给出了所提方法在降噪任务上的性能与视觉效果对比,可以看到:
在不同的噪声水平下,IPT均取得了最佳的降噪指标,甚至在Urban100数据上提升高达2dB。 IPT可以很好的重建图像的纹理&结构信息,而其他降噪方法则难以重建细节信息。

Deraining
下表&下图给出了所提方法在图像去雨任务上的性能与视觉效果对比。可以看到:
所提方法取得了最好的指标,甚至取得了1.62dB的性能提升; IPT生成的图像具有与GT最详尽,且具有更好的视觉效果。


Generalization Ability
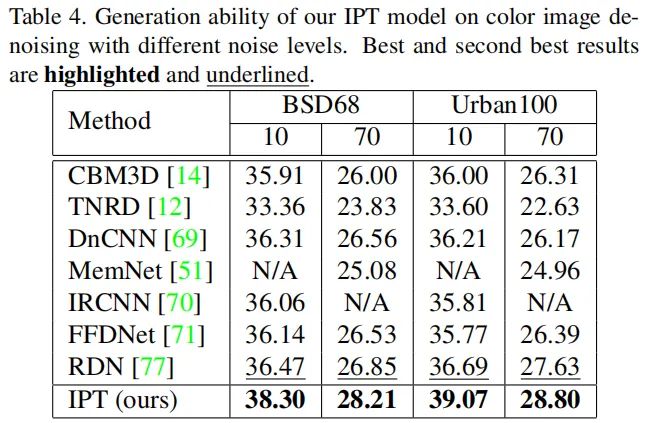
为说明所提方法的泛化性能,作者采用了未经训练的噪声水平进行验证,结果见下表。可以看到:尽管未在该其噪声水平数据上进行训练,所提IPT仍取得了最佳的指标。
Ablation Study
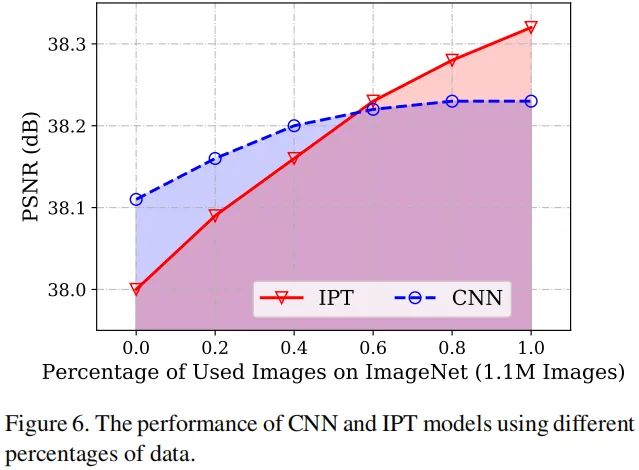
下图对比了IPT与EDSR在不同数量训练集上的性能对比,可以看到:当训练集数量较少时,EDSR具有更好的指标;而当数据集持续增大后,EDSR很快达到饱和,而IPT仍可持续提升并大幅超过了EDSR。
下表给出了对比损失对于模型性能影响性分析(x2超分任务)。当仅仅采用监督方式进行训练时,IPT的指标为38.27;而当引入对比学习机制后,其性能可以进一步提升0.1dB。这侧面印证了对比学习对于IPT预训练的有效性。

全文到此结束,对此感兴趣的同学建议阅读原文。在极市平台公众号回复“IPT”,即可获取此文。
推荐阅读
