
扩散模型再下一城! YYDS!
转自:机器之心 ;以后,故事配图这个活可以交给 AI 了。
通知:专注深度学习面试,前沿论文分享,入门深度学习指导的【DASOU的学习圈-戳这里了解详情】成立了!
你有没有发现,最近大火的扩散模型如 DALL·E 2、Imagen 和 Stable Diffusion,虽然在文本到图像生成方面可圈可点,但它们只是侧重于单幅图像生成,假如要求它们生成一系列连贯的图像如漫画,可能表现就差点意思了。
生成具有故事性的漫画可不是那么简单,不光要保证图像质量,画面的连贯性也占有非常重要的地位,如果生成的图像前后连贯性较差,故事中的人物像素成渣,给人一种看都不想看的感觉,就像下图展示的,生成的故事图就像加了马赛克,完全看不出图像里有啥。

本文中,来自滑铁卢大学、阿里巴巴集团等机构的研究者向这一领域发起了挑战:他们提出了自回归潜在扩散模型(auto-regressive latent diffusion model, AR-LDM),从故事可视化和故事延续入手。故事的可视化旨在合成一系列图像,用来描述用句子组成的故事;故事延续是故事可视化的一种变体,与故事可视化的目标相同,但基于源框架(即第一帧)完成。这一设置解决了故事可视化中的一些问题(泛化问题和信息限制问题),允许模型生成更有意义和连贯的图像。

论文地址:https://arxiv.org/pdf/2211.10950.pdf
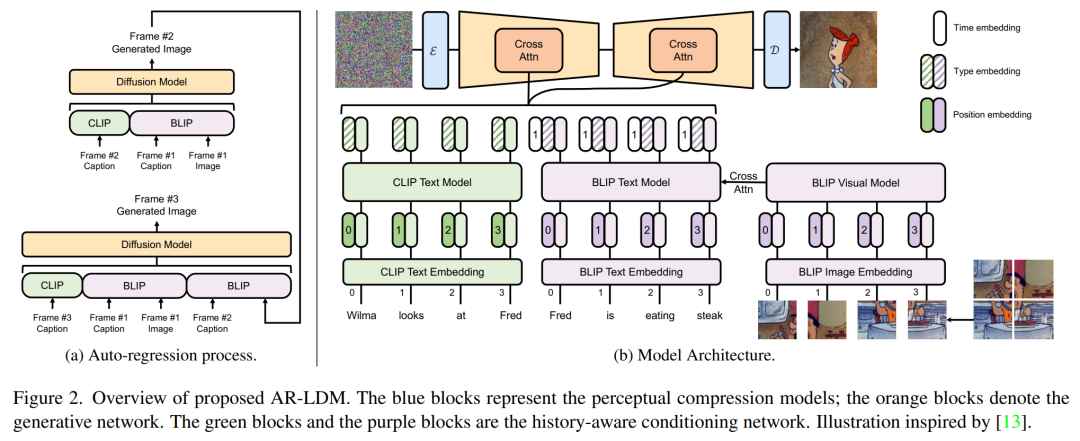
具体来说, AR-LDM 采用了历史感知编码模块,其包含一个 CLIP 文本编码器和 BLIP 多模态编码器。对于每一帧,AR-LDM 不仅受当前字幕的指导,而且还以先前生成的图像字幕历史为条件。这允许 AR-LDM 生成相关且连贯的图像。
据了解,这是第一项成功利用扩散模型进行连贯视觉故事合成的工作。
该研究的效果如何呢?例如,下图是本文方法和 StoryDALL·E 的比较,其中 #1、2、3、4、5 分别代表第几帧,在第 3 和第 4 帧的字幕中没有描述汽车或背景的细节,只是两句话「#3:Fred 、 Wilma 正在开车 」、「#4:Fred 一边开车,一边听乘客 Wilma 说话。Wilma 抱着双臂和 Fred 说话时看起来很生气。」相比较而言,AR-LDM 生成的图像质量明显更高,人物脸部表情等细节清晰可见,且生成的系列图像更具连贯性,例如 StoryDALL·E 生成的图像,很明显的看到背景都不一样,人物细节也很模糊,其生成只根据上下文文本条件,而没有利用之前生成的图像。相反,AR-LDM 前后给人的感觉就是一个完整的漫画故事。
总结来说就是,AR-LDM 表现出很强的多模态理解和图像生成能力。它能够精确地生成字幕描述的高质量场景,并在帧间保持很强的一致性。此外,该研究还探索了采用 AR-LDM 来保持故事中未见过的角色(即代词所指的角色,例如图 1 最后一帧中的男人)的一致性。这种适配可以在很大程度上缓解由于对未见角色的不确定描述而导致的生成结果不一致。

最后,该研究在两个数据集 FlintstonesSV 和 PororoSV 上进行了实验,虽然使用的数据集都是卡通图像,但该研究还引入了一个新的数据集 VIST,来更好地评估 AR-LDM 对真实世界的故事合成能力。
定量评估结果表明 AR-LDM 在故事可视化和连续任务中都实现了 SOTA 性能。特别是,AR-LDM 在 PororoSV 上取得了 16.59 的 FID 分数,相对于之前的故事可视化方法提高了 70%。AR-LDM 还提高了故事连续性能,在所有评估数据集上相对提高了大约 20%。此外,该研究还进行了大规模的人类评估,以测试 AR-LDM 在视觉质量、相关性和一致性的表现,这表明人类更喜欢本文合成的故事而不是以前的方法。
方法概述
与单字幕文本到图像任务不同,合成连贯的故事需要模型了解历史描述和场景。例如下面这个故事「红色金属圆柱立方体位于中心,然后在右侧添加一个绿色橡胶立方体」,仅第二句话无法为模型提供足够的指导来生成连贯的图像。因此对于模型来说,了解第一张生成图像中「红色金属圆柱立方体」的历史字幕、场景和外观至关重要。
设计强大的故事合成模型的关键是使其能够将当前图像生成与历史字幕和场景结合起来。在这项工作中,研究者提出了 AR-LDM,以实现更好的跨帧一致性。如下图 2a 所示,AR-LDM 利用历史字幕和图像来生成未来帧。图 2b 显示了 AR-LDM 的详细架构。
现有工作假设每一帧之间的条件独立,并根据字幕生成整个视觉故事。而 AR-LDM 额外地以历史图像 为条件来摆脱这个假设,并根据链式法则直接估计后验,其形式如下
为条件来摆脱这个假设,并根据链式法则直接估计后验,其形式如下
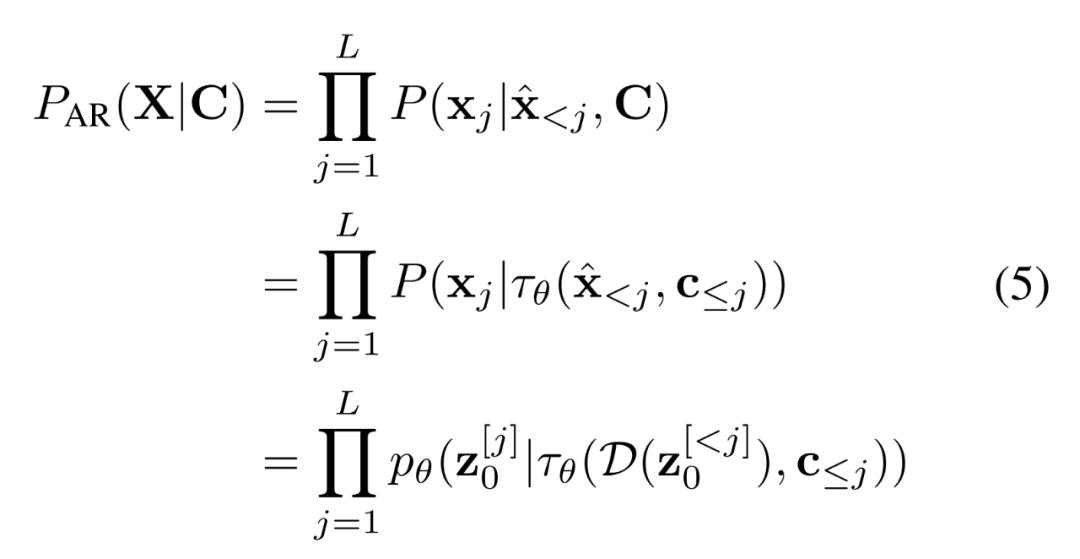
AR-LDM 还能在高效、低维潜在空间中执行正向和反向扩散过程。潜在空间在感知上近似等同于高维 RGB 空间,而像素中冗余的语义无意义信息被消除。具体地,AR-LDM 在扩散过程中使用潜在表示 代替像素,最终输出可以用 D(z) 解码回像素空间。单独的轻度感知压缩阶段仅消除难以察觉的细节,使模型能够以更低的训练和推理成本获得具有竞争力的生成结果。
代替像素,最终输出可以用 D(z) 解码回像素空间。单独的轻度感知压缩阶段仅消除难以察觉的细节,使模型能够以更低的训练和推理成本获得具有竞争力的生成结果。
研究者使用历史感知条件网络将历史字幕 - 图像对编码为多模态条件 ,以指导去噪过程
,以指导去噪过程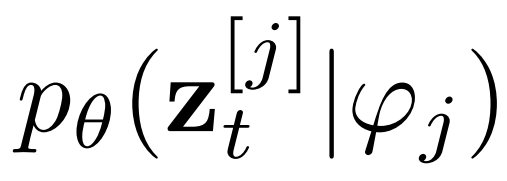 。条件网络由 CLIP 和 BLIP 组成,分别负责当前字幕编码和先前字幕图像编码。BLIP 使用视觉语言理解和生成任务与大规模过滤干净的 Web 数据进行预训练。总之,AR-LDM可以通过以下公式生成图像
。条件网络由 CLIP 和 BLIP 组成,分别负责当前字幕编码和先前字幕图像编码。BLIP 使用视觉语言理解和生成任务与大规模过滤干净的 Web 数据进行预训练。总之,AR-LDM可以通过以下公式生成图像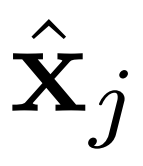 。
。
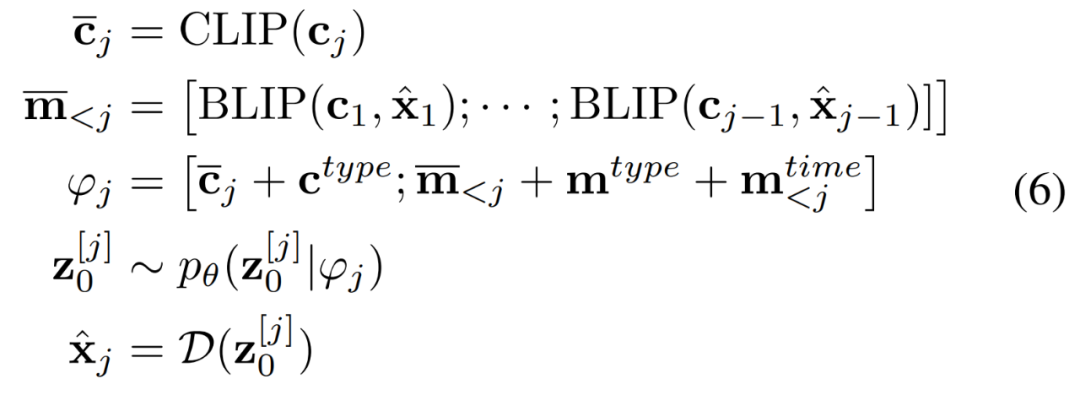
自适应 AR-LDM
对于漫画等现实世界的应用,有必要为新的(未见过的)角色保持一致性。受 Textual Inversion 和 DreamBooth 的启发,研究者添加了一个新的 token 来表示未见过的角色,并调整经过训练的 AR-LDM 以泛化到特定的未见过的角色。
具体来说,新 token 的嵌入由类似的现有单词初始化,如「man」或「woman」。研究者只需要角色的 4-5 张图像组成一个故事作为训练数据集,并使用 1e-5 的相同学习率对经过 100 个 epoch 的 AR-LDM 进行微调。他们发现微调 AR-LDM 的整个参数(仅编码器 和解码器 D 除外)获得了更好的性能。
和解码器 D 除外)获得了更好的性能。
实验结果
研究者使用三个数据集作为测试平台,分别是 PororoSV、FlintstonesSV 和 VIST。这三个数据集中的每个故事都包含 5 个连续的帧。对于故事可视化,研究者从字幕中预测全部的 5 帧。对于故事连贯性,第一帧被指定为源帧,并参考源帧生成其余 4 帧。他们在 8 块 NVIDIA A100-80GB GPU 上对 AR-LDM 训练了 50 个 epoch,用时两天。
研究者使用两种设置评估 AR-LDM,其一是使用自动度量 FID 分数进行定量评估,其二是关于视觉质量、相关性和一致性的大规模人工评估。
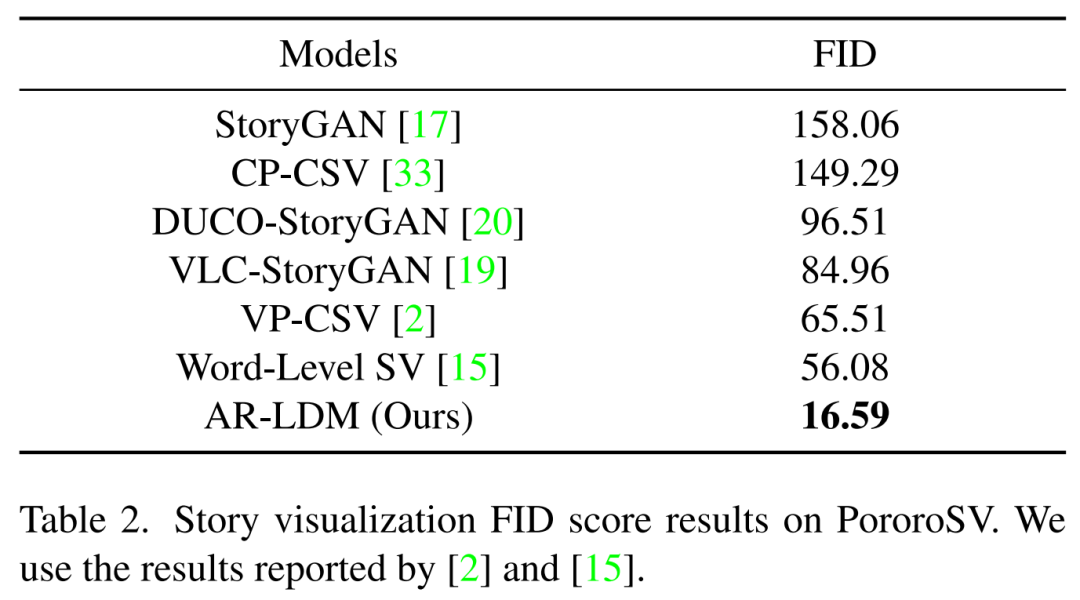
下表 2 展示了在 PororoSV 上的故事可视化结果,其中 AR-LDM 取得了重大进步,SOTA FID 分数得分为 16.59,大大低于以前的方法。
下图 4a 中,AR-LDM 能够生成高质量、连贯的视觉故事,同时忠实地再现角色细节和背景。图 4b 中,AR-LDM 可以通过自回归生成保留场景,例如左侧示例中最后两帧的背景,以及右侧示例中第三和第四帧中的块。

研究者测试了 AR-LDM 的故事连贯性,结果如下表 1 所示。AR-LDM 在所有四个数据集上都获得新的 SOTA FID 分数。值得一提的是,AR-LDM 凭借大约一半的参数优于 MEGA-StoryDALL·E。

下图 5 显示了 FlintstonesSV 和 VIST-SIS 数据集上的更多示例,可以观察到跨帧的场景一致性,例如左上角示例中第三帧和第四帧的窗户,左下角示例中的海岸场景。

下图 6 中,与其他方法相比,具有自回归生成方式的 AR-LDM 可以更好地跨帧保留背景和场景视图。

下图 7 中,所有带下划线的文本都指的是同一个角色(即源帧中戴粉色帽子的男人),而描述不一致。因此,AR-LDM 根据每一个描述生成三个不同的角色。在对 3-5 幅图像进行微调后,自适应 AR-LDM 可以生成一致的角色,并如字幕所描述的那样忠实地合成场景和角色。

更多实验细节请参阅原论文。
感兴趣的可以戳这里了解一下,或者直接扫描下方二维码加入。