
干货|多起点的局部搜索算法(multi-start local search)解决TSP问题(...
共 2053字,需浏览 5分钟
· 2020-03-28
❝文案代码 向柯玮
❞
审核校对 邓发珩
前言
各位看客老爷们,大家好~

今天要为大家带来的干货是multi-start local search算法解决TSP问题(Java的实现)。
大家可不要因为这个算法的名字比较长,就觉得这个这个算法很难,其实没有哦-

这个算法还是非常简单的,希望大家能够通过这个简单的算法来了解面对NP-hard问题,我们可以采取的策略是什么。
算法简介
这个算法,其实大家通过名字就可以知道,一定和Iterated local search(迭代局部搜索算法)存在一定的联系。
(这是当然呀,名字都差不多,还需要你说吗?)

迭代局部搜索算法公众号在之前已经介绍过了,有兴趣的小伙伴可以再看看~
干货|迭代局部搜索算法(Iterated local search)探幽(附C++代码及注释)
这两个算法相似的地方我们就不多说了。我们主要介绍这个算法优势之处。
优势
这种算法,他是多起点的,初始解的生成和遗传算法挺类似的。
通过随机打乱,生成多个随机新解,以此来增大达到最优解的目的。

可能大家光这么看,没啥感觉,我们可以通过数学公式来让大家直观的感受一下。
我们认为有N个城市,令传统的LS搜索的次数为A,传统的MLS搜索次数为A',改进过的MLS搜索次数为A'',可以容易得出下面的公式。
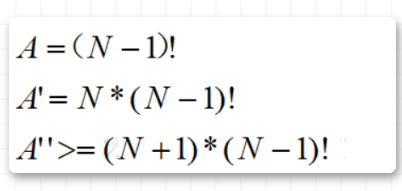
现在让我们再来看看实际的程序跑出来的结果。
这是传统的LS。

这是传统的MLS。

这是咱们优化过的MLS。

从以上两个例子我们可以看出,MLS确实能够提高单次程序运行获得优质解的概率。
那么,下面就让我们简单地总结一下MLS的一些优点。
- 如果是在多线程情况下进行探索,那么速度和LS是差不多的
- 探寻到最优解的概率更大了
- 对于新手来说,也可以更好的学习这种多个初始解的思想,便于以后GA等算法的学习
虽然本次代码的展示仍然是采用单线程,但是只要单线程的明白了,多线程其实很容易就变过去了。
算法流程分析
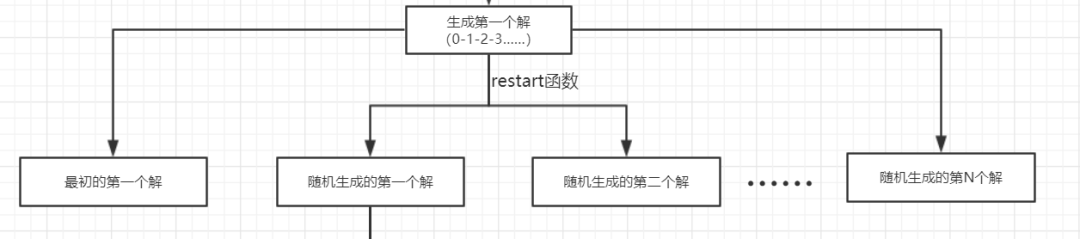
现在我们先来介绍介绍最普遍的一种multi-start local search(多起点的局部搜索算法)。
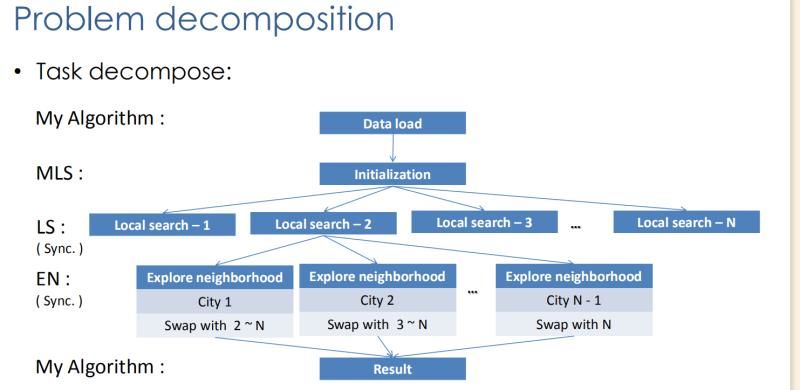
大致的流程就是上面这副图一样,在读取数据之后生成第一个解,即按照0-1-2-3……排序的解。
然后将这个解进行打乱,生成N组解,然后分别对这N组解利用2-opt算子进行邻域搜索。
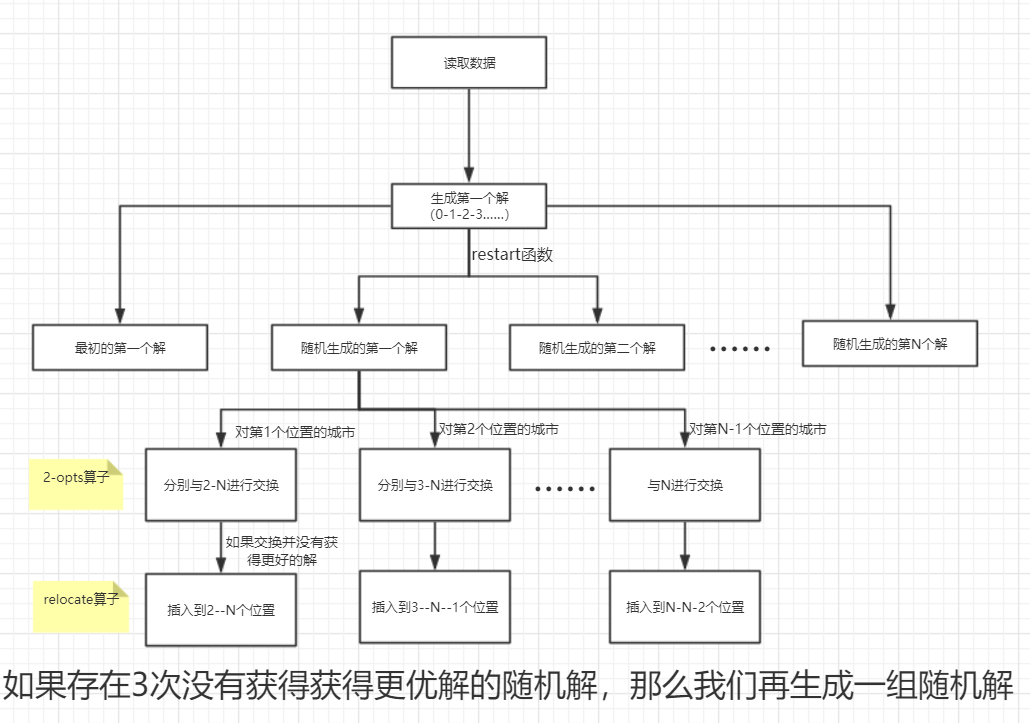
我个人感觉这一种multi-start local search算法并不是很好。
- 都是采用的多线程操作,对于新手都不是很友好,代码不大看得明白
- 算子太少,单一的2-opts算子很难找到较好的解
- 对一些比较差的初始解(通过邻域搜索都无法找到更好的解),没有进行一些处理
鉴于上面的不足,我对这个算法进行了一定程度的改进。如下图。

代码解析
在上面,我们大致的介绍了本次算法的大致实现过程。
接下来,我们对部分代码进行解读

启动函数
这个函数是我们的main函数,我们在这里完成我们所有的操作。
我们在iter函数中完成我们的搜索过程。
public class launch {
public static void main(String[] args) {
mls my_solution=new mls(); //生成mls对象
readfile my_file=new readfile(); //读取文件
my_file.buildInstance("F:\\mls\\data\\uy734.tsp.txt"); //读取文件
my_solution.setiLSInstance(my_file.getInstance()); //设置好距离矩阵
my_solution.setsolution(); //设置好初始解
my_solution.iter(); //开始迭代
my_solution.print_best(); //输出最优解
System.out.println("最佳适应度为:"+my_solution.print_of()); //输出最佳适应度
}
}
iter函数
这个函数就是最主要的函数,相当于整个搜索的过程的启动器。
我们在这个函数中,每次生成一个新的随机解,然后进行邻域搜索。这个就是区别于LS的根本之处。
并用'tihuan'作为改随机解是否为一个较好解的标志。
public void iter() {
for(int c=0;c
Solution localsolution2 = this.currBest.clone();
for (int j = c; j < this.iLSInstance.getN(); j++) {
Solution now = ls(localsolution2.clone(), j);
if (now.getOF() < this.dLSGlobalBest.getOF())
this.dLSGlobalBest = now.clone();
}
}
for (int i = 0; i < this.iLSInstance.getN(); i++) {
tihuan=false;
Solution localsolution = this.currBest.clone();
localsolution=restart(localsolution);
for (int j = 0; j < this.iLSInstance.getN(); j++) {
Solution now = ls(localsolution.clone(), j);
if (now.getOF() < this.dLSGlobalBest.getOF())
this.dLSGlobalBest = now.clone();
}
for(int m=0;m
System.out.println(localsolution.getsolution().get(this.iLSInstance.getN()-1));
if(!tihuan)
step++;
if(step==50)
{
i--;
step=0;
}
}
}
LS函数
LS函数,即local search函数,我们通过这个函数,完成我们对每组解的每个位置的城市的邻域搜索操作。
并用‘tihuan’作为是否生成更好的解(这里是指生成比当前随机解好的解)的标志。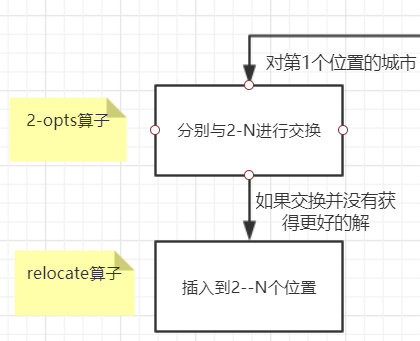
public Solution ls(Solution ssolution,int i) {
Solution best = ssolution.clone();
for (int j = i + 1; j < this.iLSInstance.getN() +i; j++) {
Solution now=ssolution.clone();
if(j
now.setOF(this.cLSCalculator.calc(this.iLSInstance, now));
if (now.getOF() < best.getOF()) {
best = now.clone();
tihuan=true;
}
if(!tihuan){
now.swap(i,j);
now.relocate(i,j);
now.setOF(this.cLSCalculator.calc(this.iLSInstance, now));
if (now.getOF() < best.getOF()) {
best = now.clone();
tihuan=true;
}
}
}
else if(j-this.iLSInstance.getN()
now.setOF(this.cLSCalculator.calc(this.iLSInstance, now));
if (now.getOF() < best.getOF()) {
best = now.clone();
tihuan=true;
}
}
}
return best;
}
restart函数
这个是我们用来生成随机新解的函数。
public Solution restart(Solution solution){
int[]haveset=new int[iLSInstance.getN()];
haveset[0]=0;
for(int i=0;i
while (haveset[n]!=0)
n=rLSRandom.nextInt(iLSInstance.getN());
solution.getsolution().set(i,n);
haveset[n]=1;
}
solution.setOF(this.cLSCalculator.calc(this.iLSInstance, solution));
return solution;
}
小结
好了,我们现在把算法的大致流程,主要的代码都展示了一下,大家可以把自己的data输进去,看看结果怎么样,T^T,小玮得到的结果都不是很理想--
该算法的随机性很大,获得优质解的难度还是蛮大的。
但是我觉得这个算法从传统LS变过来给了我们很多启发,比如说,在寻求最优解的时候,我们可以采用多线程来提高寻求最优解的效率等等。
我希望大家通过本次推文,能够了解到邻域解是如何产生的,以及算法不够好时的我们可以采用哪些改进。
那么在下一次的推文中,会介绍一种船新的组合优化解决VRPTW的算法~让我们一起期待吧!

本篇推文代码请在公众号后台回复【MLS代码】获取(不用输入【】)
赞 赏
长按下方二维码打赏
感谢您,
支持学生们的原创热情!
郑重承诺
打赏是对工作的认可
所有打赏所得
都将作为酬劳支付给辛勤工作的学生
指导老师不取一文
文案 && 编辑:向柯玮(华中科技大学管理学院)
审稿&&修正:邓发珩(华中科技大学管理学院)
指导老师:秦虎(华中科技大学管理学院)
如对文中内容有疑问,欢迎交流。PS:部分资料来自网络。
如有需求,可以联系:
秦虎老师(professor.qin@qq.com)
向柯玮(华中科技大学管理学院本科一年级:2562599523@qq.com)
扫一扫,获取数据和模型还有更多算法学习课件分享哟