
【论文解读】当前最强长时序预测模型--Autoformer详解
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting

AutoFormer旨在研究长时间序列的预测问题。先前的基于Transformer的模型采用各种self-attention来挖掘长期依赖。长期复杂的时间模式阻碍了模型找到可靠的依赖关系。此外,Transformer必须采用稀疏版的point-wise self-attentions来捕捉较长时间的关联,这也造成了信息利用的瓶颈。AutoFormer基于Auto-Correlation机制的新型分解架构。
我们将series的分解更新为模型的一个内部模块。这种设计使Autoformer具有复杂时间序列的渐进分解能力。另外,受随机过程理论的启发,我们设计了基于序列周期性的自相关机制,在子序列级进行依赖项发现和表示聚合。
Auto-Correlation在效率和准确性上都优于self-attention。在长期预测中,Autoformer具有最好的精度,在六个基准上相对提高了38%。
时间序列预测问题是根据过去的长度序列预测未来最可能的长度的序列,表示为。长期预测设置是预测长期未来,即更大的。
长期序列预测的困难:处理复杂的时间模式,打破计算效率和信息利用的瓶颈。
为了解决这两个难题,我们将分解作为一个内置模块引入深度预测模型,并提出Autoformer作为一种分解架构。此外,我们还设计了自相关机制来发现基于周期的依赖关系,并聚合来自底层周期的相似子序列。
Series decomposition block
我们将序列分解为trend-cyslical和周期的模块,这两个模块可以反映序列的长期的progression和周期性。于是我们提出下面的框架:
对于长度为的序列,处理方式为:
其中,表示周期的和抽取的trend-cyclical部分。我们用表示moving average,使用。
Model inputs
encoder部分是过去个时间段, ,输入到Autoformer decoder的部分包含周期性部分以及trend-cyclical部分,
其中:
表示周期的和trend-cyclical部分; 表示填充了0的placeholders和的均值;
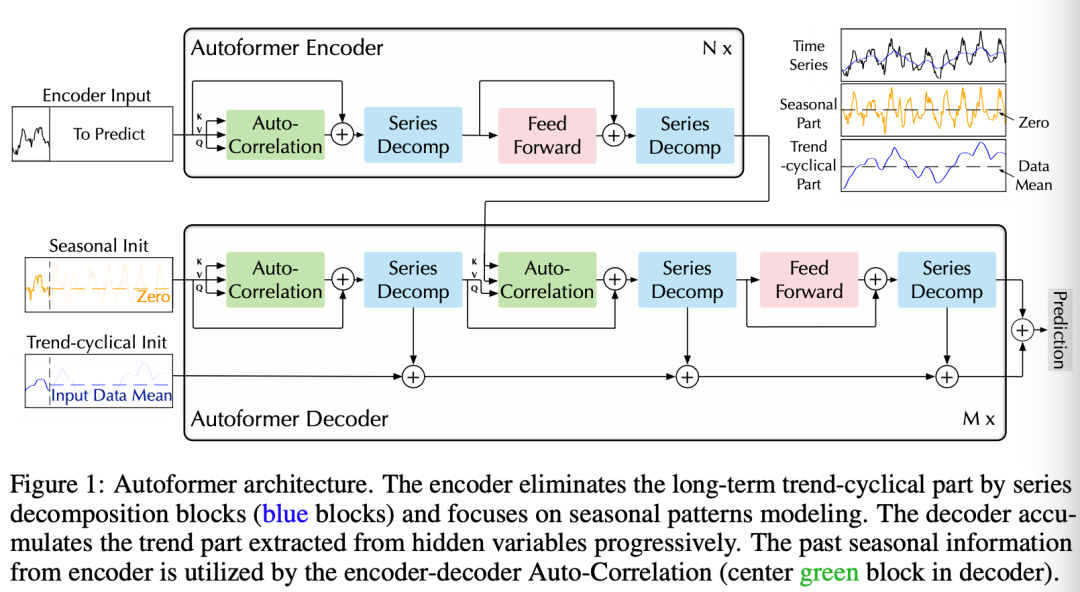
Encoder
Encoder侧重于季节性建模。Encoder的输出包含过去的季节性信息,并将用作交叉信息,以帮助Decoder优化预测结果。
假设我们有N个编码器层。第l个编码器层的总体方程如下:
具体地:
其中,
”_“表示删除的trend部分;
Decoder
decoder包含两部分,trend-cyclical成份的累积结构和周期性分量的叠加自相关机制。每个decoder层包含内在的Auto-Correlation和encoder-decoder Auto-Correlation部分。这样就可以微调预测并且利用过去的周期性信息。
其中,表示第层的decoder。
是从编码过来的用于深度转化,并且用于累积。表示周期性的成份以及trend-cyclical部分。
表示第个抽取的trend 的映射。
Auto-Correlation Mechanism
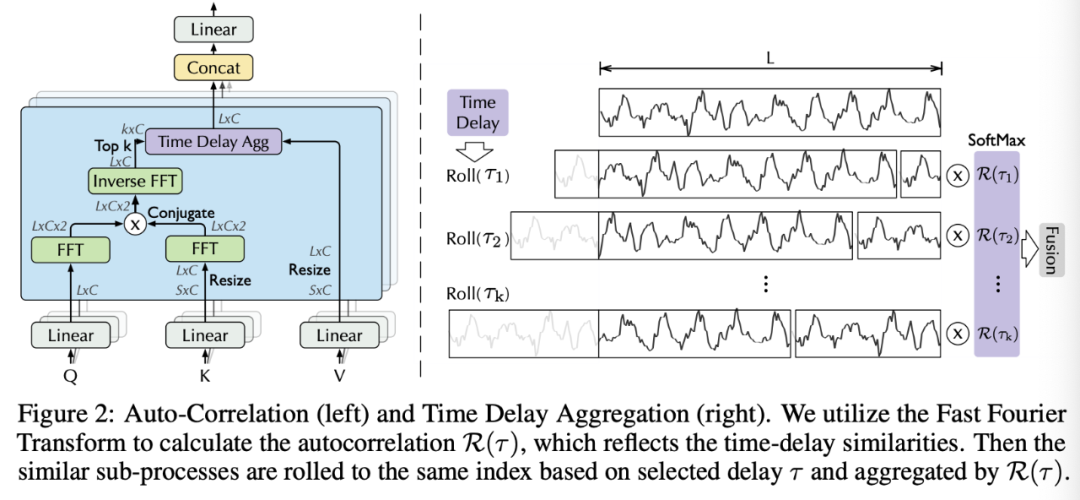
Period-based dependencies
可以观察到:
周期之间相同的相位位置会提供类似的sub-process.
受到随机过程理论的影响,对于一个真实的离散时间过程,我们可以得到自相关性,
表示以及它的延迟序列 的时延相似性,此处我们使用自相关表示估计周期长度的unnormalized的置信度。我们选择最有可能的个周期长度,,
Time delay aggregation
基于周期的依赖关系将子序列连接到估计的周期中。因此,我们提出了时延聚合块,
其中,用来获取TopK相关性的论据,我们令, 其中c是超参,是两个序列和的自相关,表示带有时间延迟的操作,在此期间,移动到第一个位置之外的元素将在最后一个位置重新引入。
对于encoder-decoder的Auto-Correlation, 来自于encoder。
对于在Autoformer中的multi-head版本, channel的隐藏变量,有个头,对于Q,K,V, ,
Efficient computation
对于基于周期的依赖关系,这些依赖关系指向处于基础周期相同阶段位置的子流程,并且本质上是稀疏的。在这里,我们选择最可能的延迟,以避免选择相反的阶段。
其中:
, 表示FFT, 是它的inverse, 表示conjugate操作, 表示频域,所有在{1,2,...,L}的延迟序列的自相关性可以通过FFT一次计算得到,因此, Auto-Correlation可以获得的复杂度。
Auto-Correlation and self-attention
与point-wise的self-attention家族不同, Auto-Correlation呈现出一系列的联系。具体地,
对于时间依赖,我们基于周期性找到子序列之间的依赖关系。相比之下,自我关注家庭只计算分散点之间的关系。
尽管一些自我关注考虑了local的信息,但它们只利用这些信息来帮助发现点相关性。对于信息聚合,我们采用time delay块来聚合来自底层周期的相似子序列。
由于固有的稀疏性和子序列级表示聚合,Auto-Correlation可以同时提高计算效率和信息利用率。
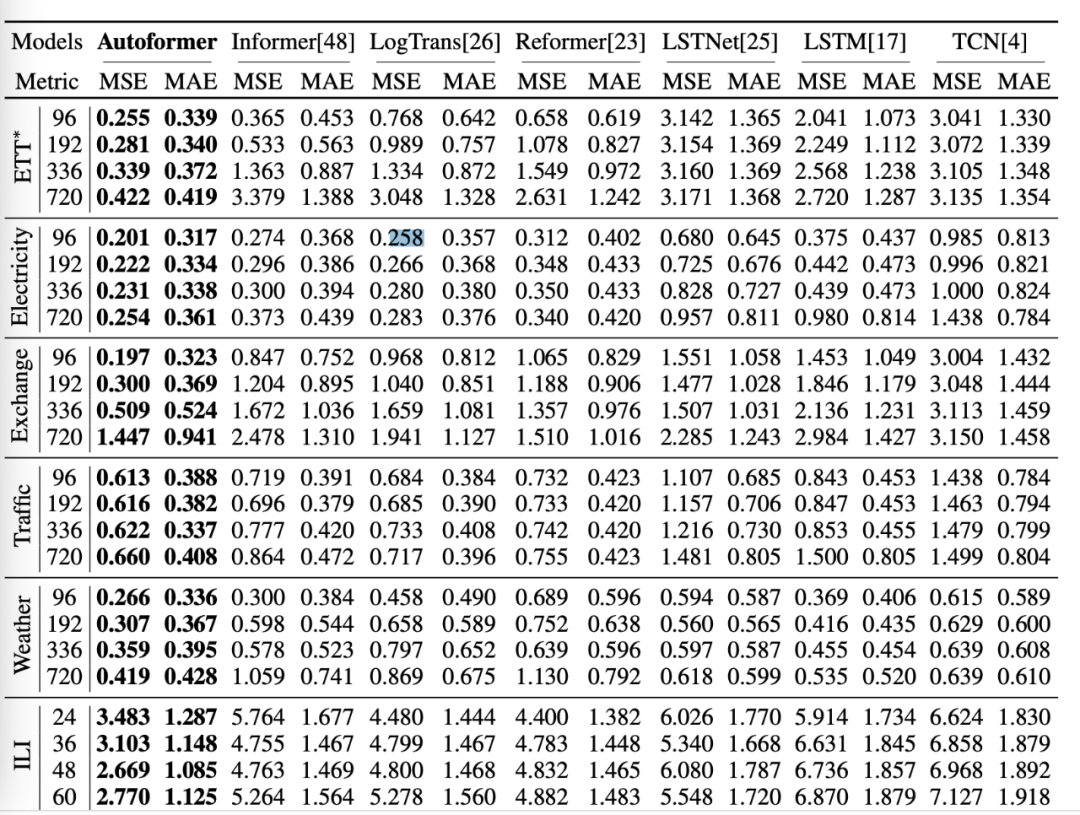
AutoFormer可以说是当前非常强的长时间序列模型,无论是效果还是速度上都存在较大的优势,建议大家自己实践一下。
https://arxiv.org/pdf/2106.13008.pdf
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: