一文读懂微服务编排利器—Zeebe

一、工作流与微服务编排
1. 工作流
(1)没有工作流时的任务协作


(2)应用工作流模型的任务协作

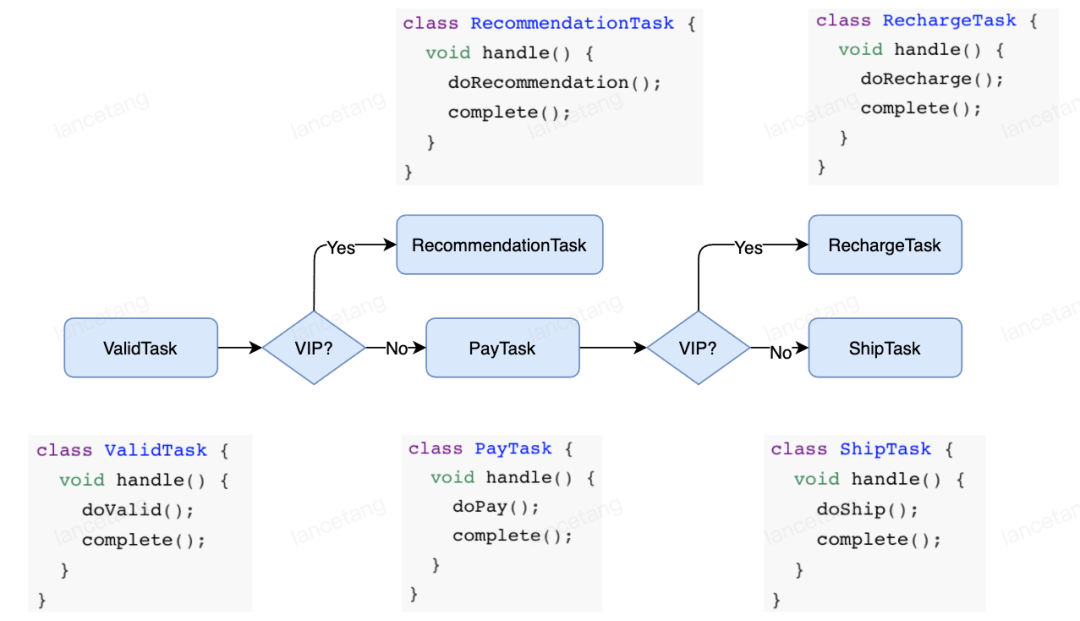
2. 工作流引擎
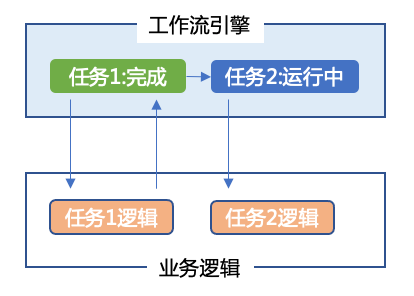
3. 微服务编排
可见性:多少端到端业务流正在运行中,它们的状态是什么样子。过去24小时,有多少业务流实例没有成功结束?为什么这些业务流实例没有成功结束?一个业务流或者某个任务完成的平均时间是多少?
异常处理:如果业务流里有一个微服务失败,谁负责处理这个异常?业务流的重试逻辑是怎么样的?如果需要人工介入,问题的升级处理规则是怎么样的?
按照业务逻辑的蓝图,编排各个微服务的调用关系;
监控整个业务流的状态;
提供自动化的机制处理单个服务的失败,保证整个业务流的成功。

传统的工作流引擎,编排的大部分是人工审批任务,意味着任务流转效率低,系统吞吐低。而当下微服务大部分是程序化的自动任务,意味着任务高效流转,系统吞吐高。单点架构、同步响应、高度依赖DB的Activiti,显然支撑不了这样的场景。
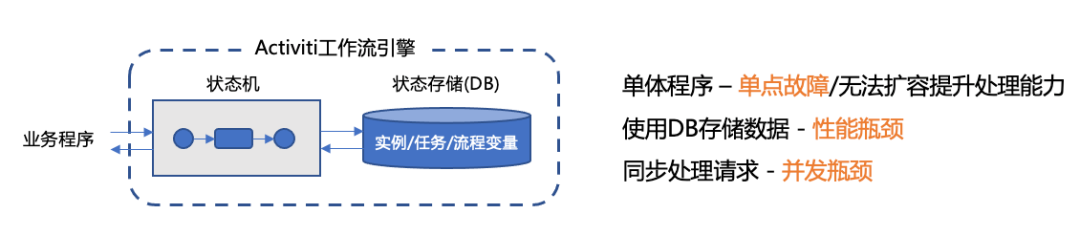
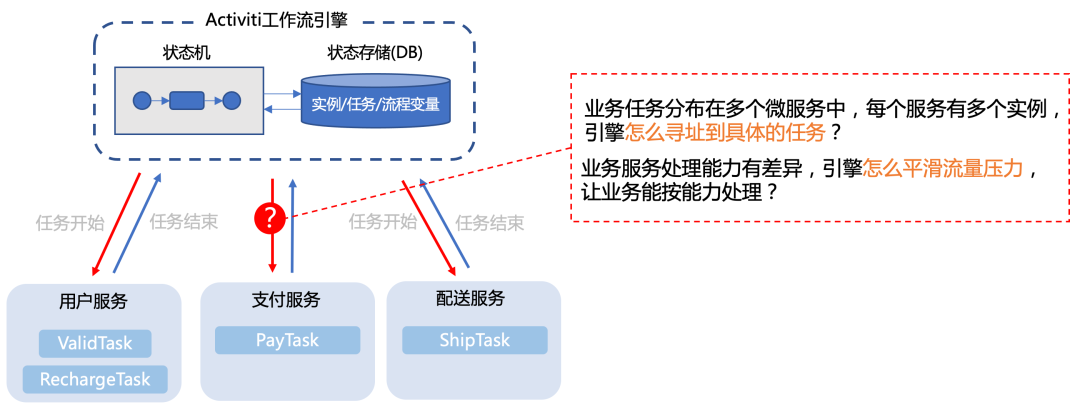
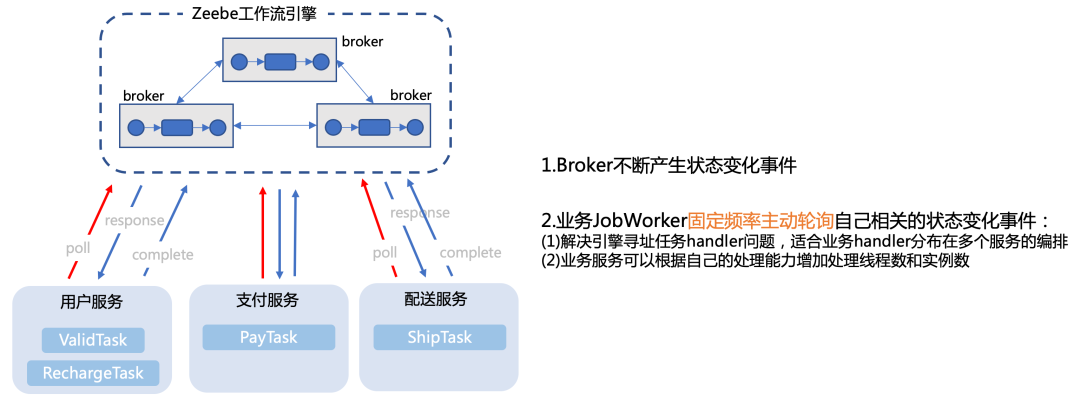
Activiti等工作流引擎,通常都以jar包的形式,嵌入到业务程序中,直接通过调用本地方法的方式调度起业务TaskHandler。在单体架构下,这种集成方式简单易用。但是在微服务架构下,工作流的任务往往是分布在多个服务的,而且同一个服务往往还会根据负载情况部署不同数量的实例。如果还是采用引擎主动调用的方式,怎么寻址到具体的TaskHandler?当后端业务服务处理能力本身是瓶颈的时候,如果引擎还是不断的调用,只会进一步压垮服务。
二、Zeebe特性与顶层架构
1. Zeebe核心特性
可见性(visibility):Zeebe提供能力展示出企业工作流运行状态,包括当前运行中的工作流数量、平均耗时、工作流当前的故障和错误等;
工作流编排(workflow orchestration):基于工作流的当前状态,Zeebe以事件的形式发布指令(command),这些指令可以被一个或多个微服务消费,确保工作流任务可以按预先的定义流转;
监控超时(monitoring for timeouts)或其他流程错误:同时提供能力配置错误处理方式,比如有状态的重试或者升级给运维团队手动处理,确保工作流总是能按计划完成。
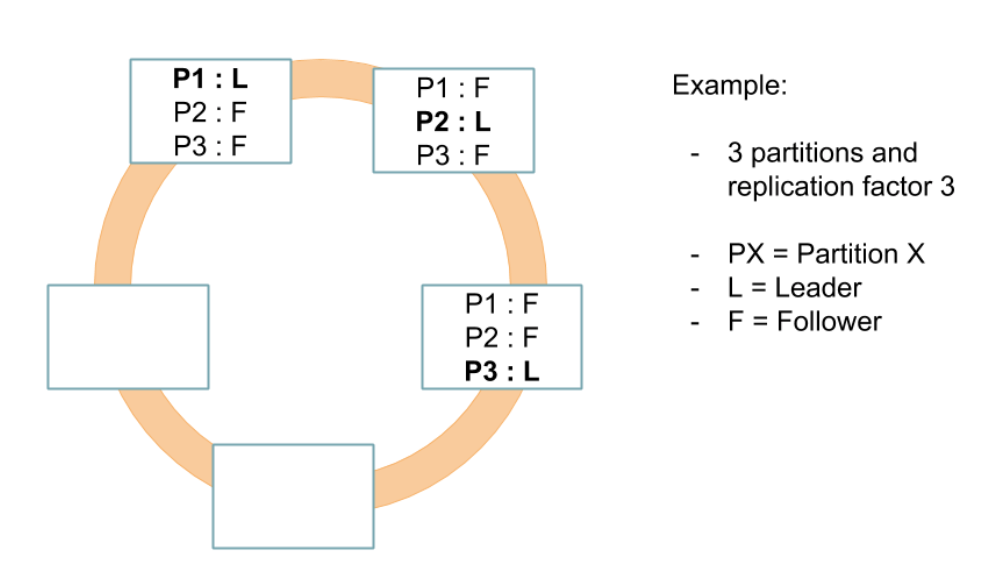
横向扩容(horizontal scalability):Zeebe支持横向扩容并且不依赖外部的数据库,相反的,Zeebe直接把数据写到所部署节点的文件系统里,然后在集群内分布式的计算处理,实现高吞吐;
容错(fault tolerance):通过简单配置化的副本机制,确保Zeebe能从软硬件故障中快速恢复,并且不会有数据丢失;
消息驱动架构(message-driven architecture):所有工作流相关事件被写到只追加写的日志(append-only log)里;
发布-订阅交互模式(publish-subscribe interaction model):可以保证连接到Zeebe的微服务根据实际的处理能力,自主的消费事件执行任务,同时提供平滑流量和背压的机制;
BPMN2.0标准(Visual workflows modeled in ISO-standard BPMN 2.0):保证开发和业务能够使用相同的语言协作设计工作流;
语言无关的客户端模型(language-agnostic client model):可以使用任何编程语言构建Zeebe客户端。
2. Zeebe架构
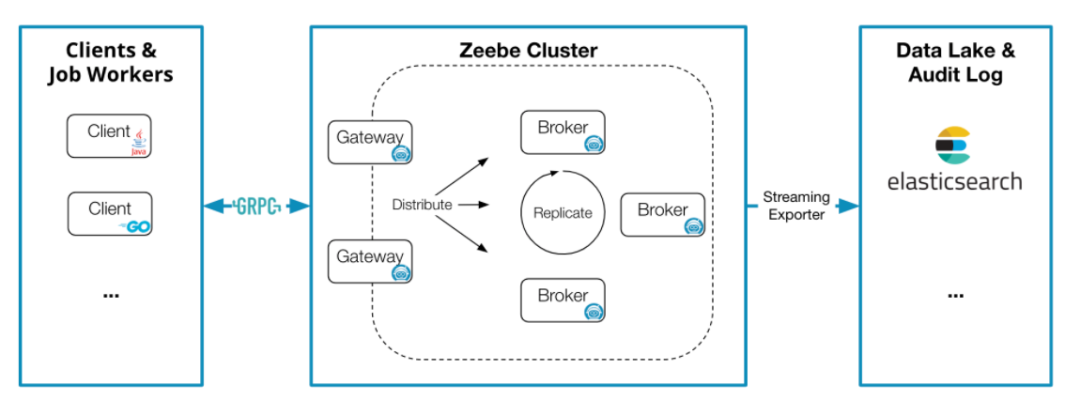
(1)Client
发布工作流(deploy workflows)
执行业务逻辑(carry out business logic)
处理运维问题(handle operational issues)
处理客户端发送的指令 存储和管理运行中流程实例的状态 分配任务给job workers
监控当前运行流程实例的状态 分析历史的工作流数据以做审计或BI 跟踪Zeebe抛出的异常(incident)
三、Zeebe内部核心实现
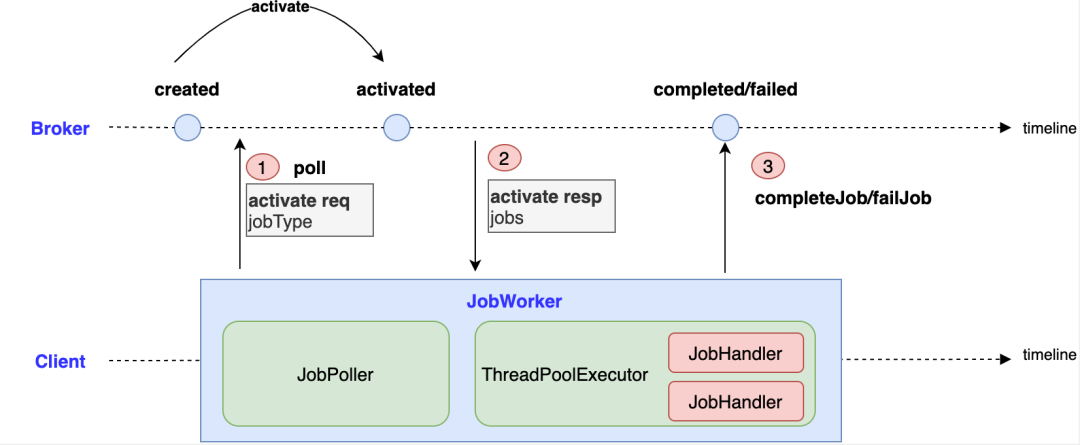
Zeebe Broker内部使用队列(即LogStream,只追加写),异步处理请求; Zeebe JobWorker和Broker使用发布订阅的模式交互,当工作流任务状态发生变化,Broker会发布相应事件。JobWorker通过轮询的方式,订阅处理自己相关的事件。
指令协议(command protocol,即请求响应) 记录导出(record export / streaming) 工作流演算(evaluation, 异步后台任务)
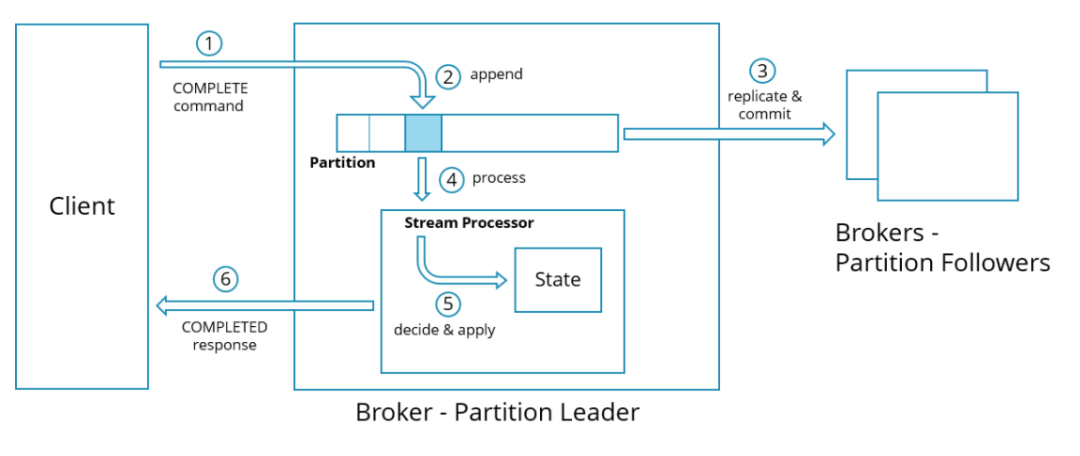
客户端发送指令。例如:发布工作流、启动流程实例、创建和完成任务等; broker自身产生指令。例如:查找可以被worker执行的任务。
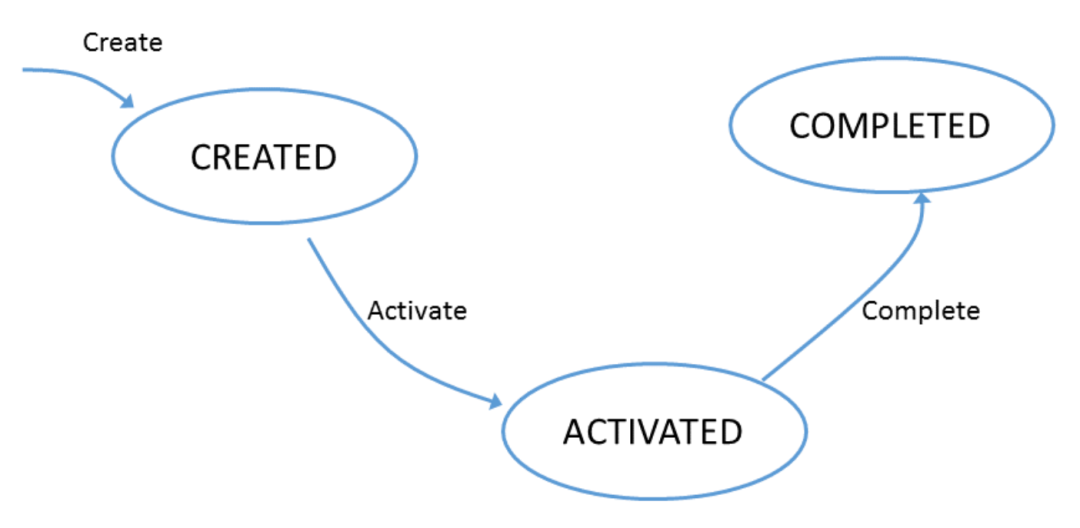
从流里消费指令(command) 根据状态生命周期和实体当前状态,判断指令是否适用 如果指令适用,应用到状态机。如果指令是客户端发送的,发送回响应。 如果指令不适用,拒绝。如果是客户端发过来的,发送错误响应信息。 发布新的事件,报告实体新的状态。
4jpublic class SomeJob {(type = "some-service.SomeJob")public void handleTask(final EnhancedJobClient client, final ActivatedJob job) {// 业务逻辑// ....// 根据业务逻辑执行情况,结单if (success) {client.completeJob(job);} else {throw SomeException("失败原因");}}

通过把历史数据推到外部数据仓库中,持久化历史数据 把记录导出到可视化工具中(例如: zeebe-simple-monitor)
exporter id不唯一 exporter指向不存在或者不能访问(non-accessible)的JAR包 exporter指向不存在或者不能实例化(non-instantiable)的类 exporter实例在Exporter#configure方法抛异常
这意味着,对于每个分区的exporter,只会有且只有一个实例:如果有4个分区,并且有至少4个线程处理记录,那么可能有4个exporter实例同时在导出记录。
在raft故障转移再处理(reprocessing)过程中(例如:选举新的leader) 偏移位没有更新出错
注意:虽然Zeebe尽力保证减少exporter处理的重复记录数,但是还是会出现重复记录,因此,有必要保证export操作的幂等性。可以在exporter代码中实现幂等性,但是如果导出到外部系统中,推荐在外部系统中做去重,这样降低Zeebe的负载。
四、上手体验